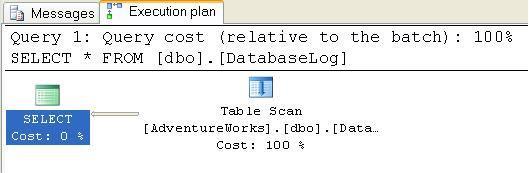
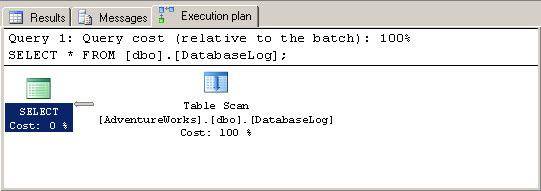
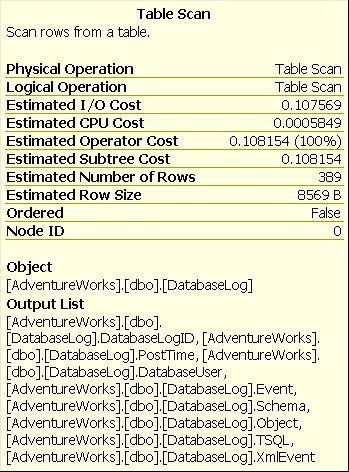
본 포스트의 내용은 MS SQL Server2005 이상에 국한된 내용입니다.
퍼가실 때는 덧글을 달아주시는 센스를...
실행 계획(Execution Plan)의 기초
실행 계획(Execution plan, 이하 실행 계획)이란 간단히 말해서 T-SQL 쿼리를 가장 최적화된 방법으로 실행하기 위해 Query optimizer(이하 쿼리 옵티마이저)의해 계산하여 만들어진 결과이다.
쿼리 옵티마이저는 RDBMS에 있어 마치 인간의 두뇌와 같은 부분으로써, 사용자가 질의한
T-SQL이 어떻게 실행되었는지, 혹은 T-SQL을 어떻게 실행할지 순식간에 계산하여 우리에게 알려준다. 따라서, 실행 계획은
악성 쿼리를 튜닝시 가장 중요한 도구로 사용된다. 예를 들어 해당 테이블에 인덱스가 적절하게 설계되어 있지 않다면, 원하는
데이터만 엑세스하지 못하고 테이블 전체를 스캔을 하는 경우가 발생할 수 있을 것이며, 이를 실행 계획을 통해 확인할 수 있는
것이다.
본 포스트에서는 실행 계획 이야기 중 아래의 토픽에 대해 먼저 다루어 보도록 하겠다.
- 쿼리 옵티마이징(쿼리 최적화)의 작동원리
- 예상 실행 계획과 실질 실행 계획
- 실행 계획을 확인 방법
- SQL Server Profiler를 이용하여 실행 계획을 캡쳐하는 방법
T-SQL을 질의하면 어떤일이 발생할까?
SQL Server에는 많은 프로세스들이 존재한다. 이 프로세스들은 데이터 질의에 대한 처리, 데이터 저장, 데이터 유지보수
등과 같이 시스템 관리를 위해 다양한 일들을 수행하는데, 우리가 T-SQL을 질의하면 SQL Server은 해당 쿼리를 수행하기
위해 몇 가지 프로세스를 동작시킨다.
이 중에서 T-SQL에 관련된 프로세스는 크게 아래의 두 개로 요약할 수 있다.
- Relational engine 관련 프로세스
- Storage engine 관련 프로세스
Relational engine은 보내어진 쿼리를 파싱한 후, 실행 계획을 작성하기 위해 쿼리 옵티마이저에게 해당 쿼리를 보낸다. 이 단계에서 작성된 실행 계획은 다시 Storage engine에 보내어 지게 되며, Storage engine은 실행 계획을 바탕으로 데이터를 검색하거나 입력, 갱신, 삭제하는 등 실질적인 데이터 처리를 수행한다. 그리고, Storage engine에는 잠금(lock), 인덱스 유지보수(index maintenance), 트랜잭션과 같은 프로세스들이 있다.
따라서, 앞으로 우리는 이 두 개의 engine 중 Relational engine에 포커스를 맞추어 이야기 할 것이다.
쿼리 파싱(Query parsing)
위에서 살펴보았듯이, T-SQL을 실행의 첫 단계는 Relational engine에서 쿼리를 파싱하는 일이다. 사용자가 T-SQL을 질의하면 먼저 T-SQL문이 정확한지 구문 검사를 하는데 이를 파싱(Parsing)이라고 한다. 그리고, 파싱 프로세스(Parse process)의 결과물을 파스 트리(parse tree), 쿼리 트리(query tree) 혹은 시퀀스 트리(squence tree)라고 하며 쿼리 실행을 위한 논리적 단계를 의미한다.
만일, 질의한 T-SQL이 DML(Data Manipulation Language)문이 아니라면 최적화(Optimizing) 단계는 건너 뛰게 된다. 예를들어 CREATE TABLE문은 단순히 "테이블을 이렇게 이렇게 작성해 주세요" 라는 의미이기 때문에 최적화할 수 있는 여지가 없는 것이다. 반대로 질의한 T-SQL이 DML인 경우에는 algebrizer라고 불리는 프로세스를 호출하여 파스 트리(parse tree)를 통과시킨다. algebrizer 프로세스에서는 질의된 T-SQL에 관련된 모든 오브젝트(테이블, 컬럼 등)을 체크하고, 이와 동시에 aggregate binding 이라고 불리는 프로세스를 함께 호출하여 GROUP BY, MAX와 같은 집계위치를 체크한다. 이렇게 쿼리 옵티마이저를 통과하여 algebrizer 프로세스가 처리한 결과물을 query processor tree라고 한다.
쿼리 옵티마이저(Query optimizer)
쿼리 옵티마이저는 Database relational engine이 동작하기 위한 길(혹은 모델)을 제시하는 역할을 하는 소프트웨어 조각이라고 말할 수 있다. 쿼리 옵티마이저는 query processor tree와 통계정보를
바탕으로 질의된 쿼리를 실행하기 위한 가장 최적화된 방법을 계산한다. 예를 들어, 해당 T-SQL을 실행하기 위해 인덱스를
사용할지, 사용한다면 어떤 인덱스를 사용할지, 혹은 조인을 한다면 어떤 조인 방법을 사용할지 등 많은 것을 결정한다.
그리고 이는 CPU 사용, I/O 그리고 실행 방법에 대한 비용(Cost) 등 다양한 계산 결과에 근거한다. 그래서 우리는 이를 비용 기반 최적화기(Cost-based optimizer)라고 하는 것이다.
퀴리 옵티마이저는 - 실행 계획이 캐쉬되어 있지 않다면 - 해당 T-SQL을 실행하기 위해 여러가지 경우의 수(실행 계획)를 생각하고, 이 중에서 가장 적은 리소스를 사용하는 실행 계획을 선택한다. 그렇다고 퀴리 옵티마이저가 항상 최적의 실행 계획을 제시하는 것은 아니라는 것을 유의하기 바란다.
만일 아주 심플한 쿼리 - 예를 들어 인덱스를 사용하지 않으며 집계나 계산이 없는... 단순히 하나의 테이블을 쿼리하는 경우
- 인 경우, 실행 계획이 이미 명백하기 때문에 실행 계획을 계산하기 위해 시간을 보내기 보다는 그냥 실행 계획
하나를 적용한다. 그래서 이를 Trivial plan (명백한 플랜) 이라고 한다. 반대로 non-trival일 경우, 퀴리 옵티마이저는 실행 계획을 선택하기 위해 비용 기반(cost-based) 연산을 실행하며, 이를 위해 SQL Server 스스로가 유지·관리하는 통계정보를 적용한다.
통계정보는 데이터베이스 내의 컬럼과 인덱스 등에서 수집되며, 데이터의 분포도, 유일성, 선택도
등을 나타낸다. 이 정보는 히스토그램 형태로 표현되는데, 전체 데이터에서 200 데이터 포인트에서 추출한 특정 값의 발생
빈도표이다. 이는 "데이터의 데이터" - 흔히들 메타데이터라고 하는 - 로써 쿼리 옵티마이저가 계산하는데 필요한 정보로 제공되어
진다.
만일, 상응하는 컬럼이나 인덱스의 통계정보가 이미 존재한다면 쿼리 옵티마이저는 그것을 사용할
것이다. 기본적으로 WHERE절이나 JOIN ON절의 한 부분으로 선언된 모든 컬럼과 인덱스에 대한 통계정보는 자동으로 생성 및
갱신된다. 반대로 통계정보가 한번도 생성되지 않은 테이블에 대해서는 그 테이블의 실제 크기를 무시하고 하나의 로우만 있다고 쿼리 옵티마이저는 가정한다. 또한, 통계정보가 생성되어 있는 임시 테이블의 경우 마치 영구 테이블처럼 히스토그램을 저장하여 사용한다.
이렇게 수집된 통계정보와 함께 앞에서 설명한 Query processor tree를 기반으로 쿼리 옵티마이저는 최적의 실행 계획을 선택하게 된다. 인생사에서도 그렇듯이 선택이라는 것은 참으로 힘든 과정이다. 이것은 쿼리 옵티마이저도
마찬가지이다. 최적의 실행 계획을 도출해 내기 위해, 일련의 실행 계획들에 대해 다양한 조인(Join) 전략을 테스트하기도
하고, 조인 순서도 바꿔보기도 하고, 때로는 다른 인덱스를 이용해 보는 등 많은 고민을 한다. 이러한 연산이 수행되는 동안 실행
계획 내의 각 스텝에 일련의 숫자가 할당하는데, 이 숫자는 해당 스텝에 수행되는데 필요한 예상 소요 시간을 의미한다. 이를 예상비용(이하 Estimated cost) 라고 하며, 결국 각 스텝의 비용의 누적치가 해당 플랜 전체의 비용이 되는 것이다.
여기서 우리는 중요한 사실을 기억해야 한다. Estimated cost는 말 그대로 예상치 라는 것을 말이다. 쿼리 옵티마이저에게 충분한 시간을 주고 매일 통계정보를 갱신시켜 준다면 쿼리를 실행하기 위한 완벽한 실행 계획을 찾을 것이다. 그러나 현실은 그렇지 못하다. 쿼리 옵티마이저가 하나의 T-SQL만 처리하는 것도 아닐 뿐더러, 제한된 통계정보를 바탕으로 수천 혹은 수만 분의 일초 안에 최적의 실행 계획을 찾아야 한다. 따라서 Estimated cost는 도구일 뿐이지 현실을 반영한 것이 아니라는 것을 유의해야 할 것이다.
쿼리 옵티마이저가 실행 계획을 작성하면 실질 실행 계획(Actual execution plan)을 만들고, 이와 똑같은 실행 계획이 캐시에 없다면 Plan cache이라고 알려져 있는 메모리 영역에 저장된다. 이는 아래의 실행 계획 재사용(Execution plan reuse)에서 다시 설명하도록 하겠다.
쿼리 실행(Query execution)
실행 계획이 작성되면 Storage engine이 쿼리를 실행한다. 앞에서 언급하였다시피 Storage engine에 대한 이야기는 본 포스트의 주제에서 벗어나기 때문에, 앞으로는 아래의 예처럼 작성된 실행 계획과 다르게 쿼리가 실행되는 경우와 같은 주의사항만 언급하기로 한다.
- 병렬 실행(Parallel execution)을 할 경우 ( 병렬 실행에 대해서는 다음에 살펴보도록 하겠다.)
- 최초 실행 계획이 작성된 당시의 통계정보가 오래되어 더 이상 무의미할 경우, 혹은 통계정보가 바뀌었을 경우
쿼리 실행 결과는 요청한 포맷에 맞추어 Relational engine이 처리하여 반환된다.
실행 계획 재사용(Execution plan reuse)
SQL Server가 실행 계획을 작성하는데 드는 비용과 부하는 상당하다. 따라서 SQL Server는 한 번 작성된 실행 계획을 어딘가에 보관해 두었다가 기회가 되면 다시 사용하려고 한다. 그 어딘가가 plan cache (이전에는 procedure cache) 라 불리는 곳이고, 기회라는 것운 똑같은 쿼리가 들어올 때이다.
SQL Server에 쿼리를 질의하면 쿼리 옵티마이저는 예상 실행 계획(Estimated Execution Plan)을 작성한다. 그리고 storage engine을 통과하기 전에, 작성된 예상 실행 계획과 plan cache에 저장되어 있는 실질 실행 계획(Actual Execution Plan) 을 비교하여 일치하는 실행 계획이 존재한다면 이를 사용한다. SQL Server는 실행 계획을 재사용 함으로써 아주 크고 복잡한 쿼리, 혹은 단순하지만 1분에 수 천, 수 만 번 실행되는 작은 쿼리에 대해 실질 실행 계획을 작성해야 하는 오버헤드를 피할 수 있는 것이다.
쿼리 옵티마이저는 각 실행 계획이 병렬 실행(Parallel execution) 했을 때 더
좋은 성능을 낼 수 있다고 판단하지 않는 이상 실행 계획을 단 한 번만 저장한다. 하지만 쿼리 옵티마이저가 병렬 실행을
선택한다면, 병렬 실행을 지원하는 또 다른 실행 계획을 작성하고 저장한다. 즉 이 순간 하나의 쿼리에 대해 두 개의 실행 계획이
존재하게 되는 것이다.
한 번 저장된 실행 계획은 메모리에 영원히 저장되는 것은 아니다. SQL Server는 저장된 실행 계획이 얼마나 자주
실행되는지 주기적으로 지켜보고 있다가 다음과 같은 공식에 의거하여 자주 사용하지 않는 실행 계획을 메모리에서 비운다. 이를 age out 이라고 한다.
- age = [estimated cost for the plan] X [the number of used times]
이 작업은 lazywriter라는 내부 프로세스가 담당하는데 비단, plan cache 뿐만 아니라 모든 종류의 캐시를 비우는 일을 한다.
Lazywriter는 아래와 같은 이슈가 발생했을 때 메모리에서 실행 계획을 비운다.
- 시스템 메모리가 부족하여 시스템에게 메모리를 양보해야 할 경우
- 실행 계획의 "age"가 0에 도달하여 실행 계획을 더 이상 사용하지 않을거라 판단할 경우
- SQL Server에 연결되어 있는 현재 커넥션들이 더 이상 실행 계획을 참조하지 않을 경우
실행 계획은 어떤 이벤트나 액션에 의해 재컴파일 되기도 한다. 실행 계획 재컴파일은 매우 비용이 높은 작업이므로 아래의 내용을 잘 숙지해야 한다.
실행 계획 재컴파일을 유발하는 액션들
- 쿼리가 참조하는 테이블의 스키마나 구조가 바뀌었을 경우
- 쿼리에서 사용된 인덱스가 바뀌었을 경우
- 쿼리에서 사용된 인덱스가 삭제되었을 경우
- 쿼리에서 사용된 통계정보가 갱신되었을 경우
- sp_recompile 함수가 호출되었을 경우
- 대량의 insert나 delete를 하는 쿼리를 할 때 (특히 해당 쿼리가 테이블의 key가 참조될 경우)
- 트리거로 인해 inserted 테이블과 deleted 테이블의 사이즈가 급격히 증가하였을 경우
- 하나의 쿼리 안에 DDL과 DML이 함께 존재하는 경우(deferred compile)
- 쿼리 내의 SET 옵션을 변경하는 경우
- 쿼리에서 사용된 임시 테이블의 스키마나 구조가 변경되었을 경우
- 쿼리에서 사용된 동적 뷰(dynamic view)가 바뀌었을 경우
- 쿼리 내의 커서 옵션을 변경한 경우
- Distributed partitioned view와 같은 remote rowset 을 변경한 경우
- FOR BROWSE 옵션이 변경되어 클라이언트 측 커서(clinet side cursor)를 사용할 경우
경우에 따라서는 캐시를 비워야 할 필요가 있을 수도 있다. 예를 들어 실행 계획을 컴파일할 때 얼마나 시간이 걸리는지, 혹은 튜닝 전후의 실행 계획을 비교하고자 할 때 아래의 명령어를 사용하여 캐시를 비울 수 있다.
※ Plan cache를 이 전에는 procedure cache라고 했기때문에 명령어가 이렇지 않은가 싶다.
그리고 아래와 같이 몇 가지 동적 관리 뷰(dynamic management view)와 동적 관리 함수(dynamic
management function)를 조회하는 T-SQL문을 작성하여, SQL Server내에서 실행된 쿼리와 해당 쿼리가
실행되었을 때의 실행 계획을 조회할 수 있다.
|
SELECT [cp].[refcounts]
,[cp].[usecounts]
,[cp].[objtype]
,[st].[dbid]
,[st].[objectid]
,[st].[text]
,[qp].[query_plan]
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp;
|
이 쿼리를 사용하면 호출된 T-SQL과 해당 T-SQL이 실행될 때 작성된 XML 실행 계획을 모두 확인 할 수
있다. 그리고 XML 실행 계획은 XML 형식으로 직접 확인하거나 그래픽 실행 계획으로 파일을 열어서 확인할 수 있다.
왜 "예상 실행 계획"과 "실질 실행 계획"이 차이를 보이는 것일까?
일반적으로, 여러분은 예상 실행 계획과 실질 실행 계획의 차이점을 발견하기 힘들 것이다. 하지만, 아래와 같이 어떤 환경적인 요인으로 인해 예상 실행 계획과 실질 실행 계획이 달라지는 경우도 발생한다.
실행 계획이 오래된 경우
두 개의 실행 계획이 달라지게 되는 가장 큰 요인은 수집된 통계정보와 실 데이터가 다른 경우이다. 그렇다면 이 두 가지가 달라지는 원인은 무엇일까?
서비스가 시작되고 시간이 경과함에 따라 데이터의 추가, 갱신, 삭제가 끊임없이 반복될 것이다. 이 과정에서 데이터나 인덱스의
키 값의 분포도가 달라지게 된다. 예를 들어 처음에는 'A'라는 데이터가 전 데이터의 대부분을 차지 했지만 시간이 흐를수록
'B"라는 데이터의 비중이 높아질 수도 있다. 이 경우 통계정보를 갱신시켜야 할 것인데, 일반적으로 통계정보 자동 갱신 옵션이 'ON'으로 설정되
어 있다면, SQL Server는 통계정보를 주기적으로 자동 갱신한다. 하지만 통계정보 자동 갱신에는 한계가 있다. 왜냐하면,
SQL Server는 통계정보의 갱신 비용을 줄이기 위해 전 데이터가 아닌 일부 데이터를 샘플링하여 통계정보를 계산하기 때문이다.
이는 곧, 시간이 지나면 지날수록 통계정보와 실 데이터의 차이는 점점 더 커진다는 것을 의미한다.
예상 실행 계획이 Invalid일 경우
어떤 상황에서는 예상 실행 계획이 제대로 동작하지 않을 수도 있다. 간단한 테스트를 위해 아래의 T-SQL 스크립트를 작성한 후 예상 실행 계획을 보도록 하자. (예상 실행 계획을 보는 방법은 실행 계획 기초(3) 그래픽 실행계획 사용하기 를 참고하기 바란다.)
|
CREATE TABLE [TempTable]
(
Id int IDENTITY (1,1)
,Dsc NVARCHAR(50)
);
INSERT INTO TempTable (Dsc)
SELECT [Name]
FROM [Sales].[Store];
SELECT *
FROM [TempTable];
DROP TABLE [TempTable];
|
이 스크립트의 예상 실행 계획을 표시하면 아마 아래와 같은 에러를 확인할 수 있을 것이다. 왜일까?
|
Msg 208, Level 16, State 1, Line 7
Invalid object name 'TempTable'.
|
쿼리 옵티마이저는 먼저, 과거에 어떤 예상 실행 계획이 작성되었는지 확인하려 할 것이다. 이 때
앞에서 살펴 보았듯이 해당 구문을 algebrizer 프로세스에 통과시킨다. 하지만 algebrizer 프로세스를 통과하는
시점에는 TempTable 이라는 테이블은 아직 존재하지 않는다. 따라서 'TempTable이라는 테이블이 없습니다.' 라고
에러를 발생시킨다. 그러나 이 스크립트가 실질 실행 계획을 통해 실행되면 - 그냥 해당 T-SQL 스크립트를 실행하면 -, 문제없이 잘 실행되는 것을 확인할 수 있다.
병렬실행이 요청되었을 경우
병렬실행의 임계치를 만나게 되면 두 개의 실행 계획이 만들어진다. 이 중에서 어떤 실행 계획을 사용할지는 query engine이 판단한다. 따라서 예상 실행 계획에서 parallel operator가 보일 수도, 혹은 보이지 않을 수도 있다. 또한 쿼리가 실제로 실행되었을 때에도 query engine이 병렬실행을 선택하느냐 마느냐에 따라 전혀 다른 실행 계획을 볼 수도 있다.
실행 계획 형식
SQL Server는 실행 계획을 볼 수 방법으로 아래의 3가지 형식을 지원한다.
- 그래픽 실행 계획(Graphical Plans)
- 텍스트 실행 계획(Text Plans)
- XML 실행 계획(XML Plans)
얼마나 상세한 정보를 보기를 원하는지 자신의 기호에 따라 선택해서 사용하면 된다.
그래픽 실행 계획
실행 계획을 보는 방법 중 가장 빠르고 직관적인 방법일 것이다. 실행 계획의 자세한 내용까지 확인 가능하며 예상 실행 계획과 실질 실행 계획 모두 그래픽 실행 계획으로 확인할 수 있다.
텍스트 실행 계획
그래픽 실행 계획보다는 가독성이 좋지 못하다. 그러나 보다 많은 정보를 즉시 활용할 수 있다는 장점을 가지고 있다.
텍스트 실행 계획에는 다음의 3가지 형식이 있다.
- SHOWPLAN_ALL : 해당 쿼리에 대한 예상 실행 계획을 보여준다.
- SHOWPLAN_TEXT : osql.exe 와 같은 툴에서 사용할 수 있도록 매우 제한된 실행 계획 데이터를 보여준다. 역시 예상 실행 계획만 볼 수 있다.
- STATISTICS PROFILE : 실질 실행 계획을 보여준다는 것을 제외하고는 SHOWPLAN_ALL과 흡사하다.
XML 실행 계획
XML 실행 계획은 XML 형식으로 실행 계획 내의 대부분의 데이터를 보여준다.
XML 실행 계획에는 다음의 2가지 형식이 있다.
- SHOWPLAN_XML : 해당 쿼리에 대한 예상 실행 계획를 XML 형식으로 보여준다.
- STATISTICS_XML : 해당 쿼리에 대한 실질 실행 계획을 XML 형식으로 보여준다.
다음 이야기 : 2. 실행 계획 기초 - 실행 계획 깨부수기를 함께하기 위해 먼저 해야 할 일