삽입 정렬(Insert Sort)
삽입 정렬(Insert Sort)
- 기초적인 정렬 알고리즘(선택 정렬, 버블 정렬, 삽입 정렬)중 하나.
- 수행 방법
- 정렬 되어있는 부분집합에 정렬할 새로운 원소의 위치를 찾아 삽입하는 방법
- 정렬할 자료를 두 개의 부분집합 S와 U로 가정
- 부분집합 S : 정렬된 앞부분의 원소들
- 부분집합 U : 아직 정렬되지 않은 나머지 원소들
- 정렬되지 않은 부분집합 U의 원소를 하나씩 거내서 이미 정렬되어있는 부분집합 S의 마지막 원소부터 비교하면서 위치를 찾아 삽입
- 삽입 정렬을 반복하면서 부분집합 S의 원소는 하나씩 늘리고 부분집합 U의 원소는 하나씩 감소하게 한다. 부분 집합 U가 공집합이 되면 삽입 정렬이 완성된다.
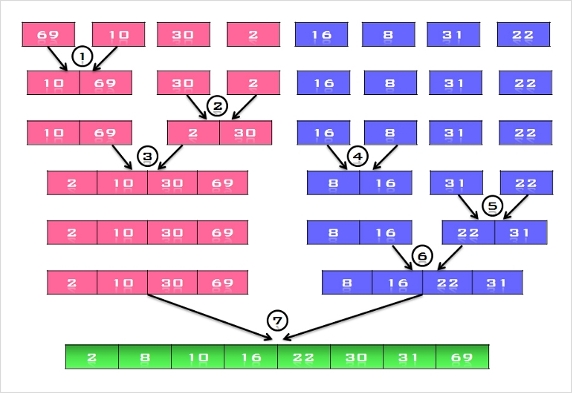
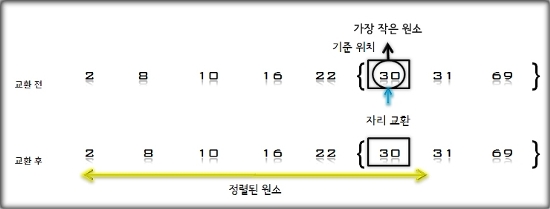
- 삽입 정렬 수행 과정
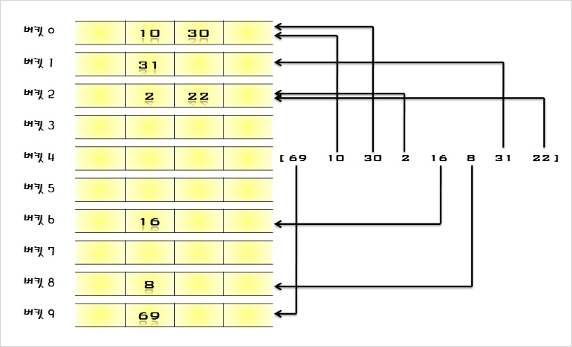
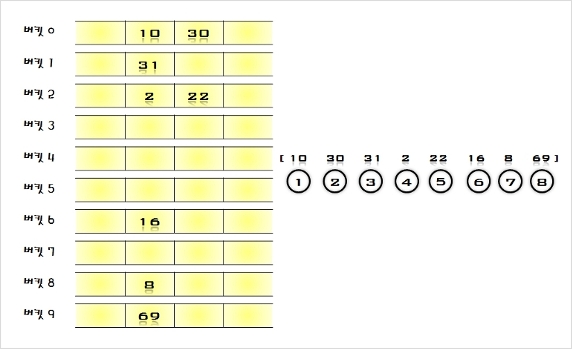
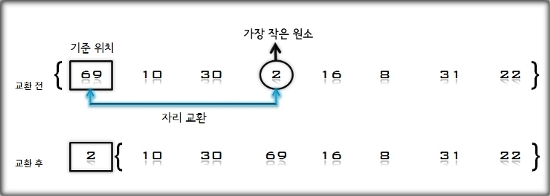
- 정렬 되지 않은 [ 69, 10, 30, 2, 16, 8, 31, 22 ]의 자료들을 삽입 정렬 방법으로 정렬하는 과정을 살펴보자.
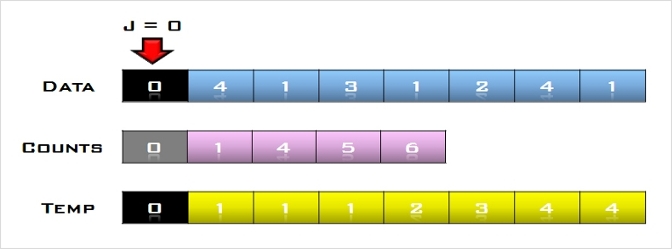
- 초기 상태 : 첫 번째 원소는 정렬되어있는 부분 집합 S로 생각하고 나머지 원소들은 정렬되지 않은 원소들의 부분 집합 U로 생각한다.
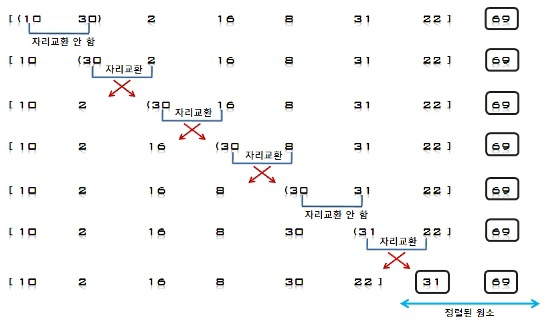
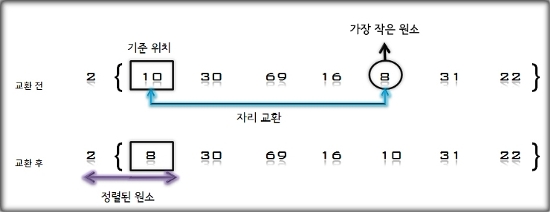
S=[69], U=[10, 30, 2, 16, 8, 31, 22]

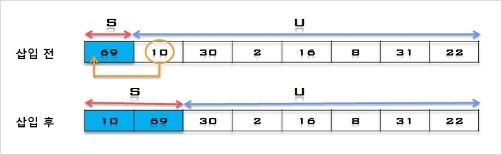
1. U의 첫 번째 원소 10을 S의 마지막 원소 69와 비교하여 (10 < 69)이므로 원소 10은 원소 69의 앞자리가 된다. 더 이상 비교할
S의 원소가 없으므로 찾은 위치에 원소 10을 삽입한다.
S = [10, 69], U = [30, 2, 16, 8, 31, 22]
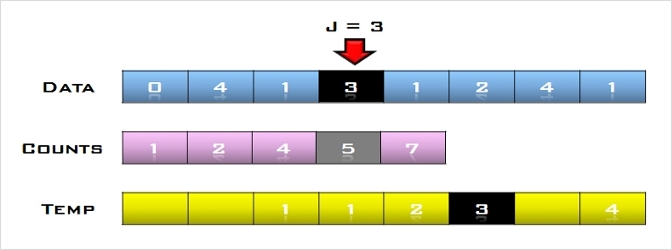
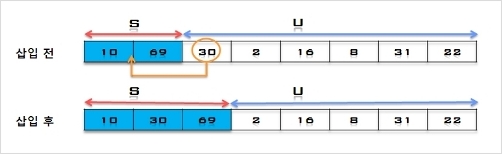
2. U의 첫 번째 원소 30을 S의 마지막 원소 69와 비교하여 (30 < 69)이므로 원소 69의 앞자리 원소 10과 비교한다. (30 > 10)이므로
원소 10과 69 사이에 삽입한다.
S = [10, 30, 69], U = [2, 16, 8, 31, 22]
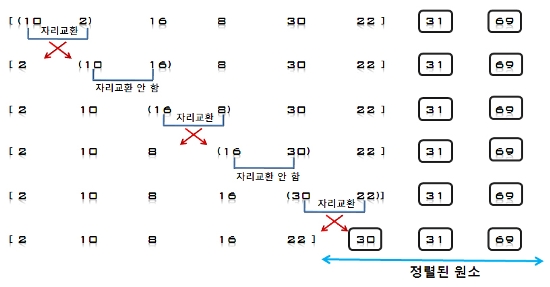
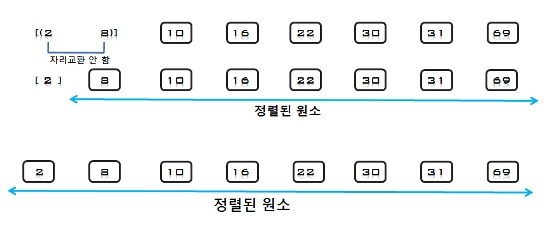
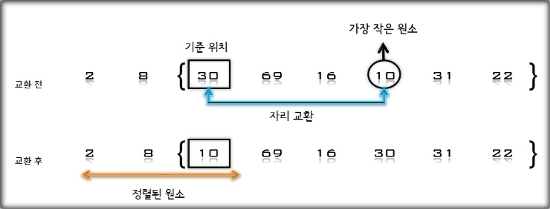
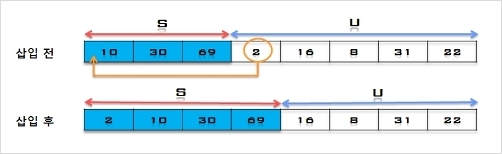
3. U의 첫 번째 원소 2을 S의 마지막 원소 69와 비교하여 (2 < 69)이므로 원소 69의 앞자리 원소 30과 비교하고, (2 < 30)이므로
다시 그 앞자리 원소 10과 비교하는데, (2 < 10)이면서 더 이상 비교할 S의 원소가 없으므로 원소 10의 앞에 삽입한다.
S = [2, 10, 30, 69], U = [16, 8, 31, 22]
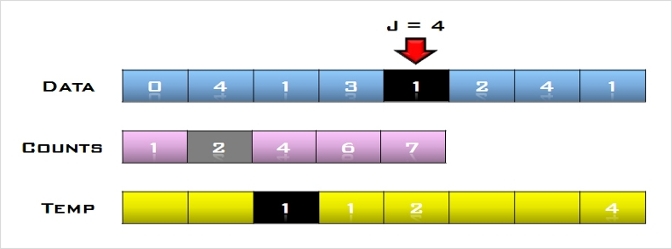
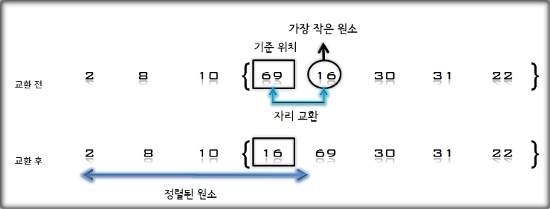
4. U의 첫 번째 원소 16을 S의 마지막 원소 69와 비교하여 (16 < 69)이므로 그 앞자리 원소 30과 비교한다. (16 < 30)이므로
다시 그 앞자리 원소 10과 비교하여, (16 > 10)이므로 원소 10과 30 사이에 삽입한다.
S = [2, 10, 16, 30, 69], U = [8, 31, 22]

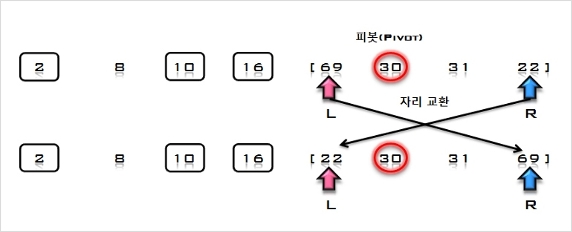
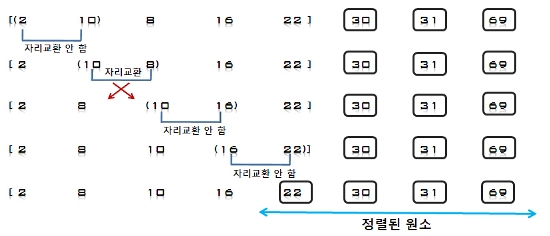
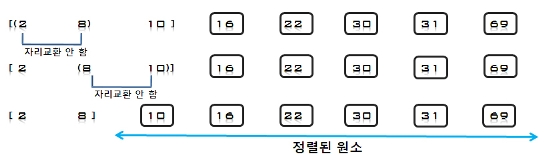
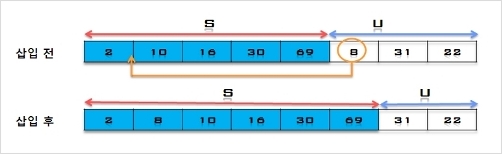
5. U의 첫 번째 원소 8을 S의 마지막 원소 69와 비교하여 (8 < 69)이므로 그 앞자리 원소 30과 비교한다. (8 < 30)이므로 그 앞자리
원소 10과 비교하여, (8 < 10)이므로 다시 그 앞자리 원소 2와 비교하는데, (8 > 2)이므로 원소 2와 10사이에 삽입한다.
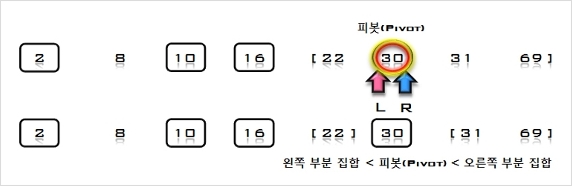
S = [2, 8, 10, 16, 30, 69], U = [31, 22]
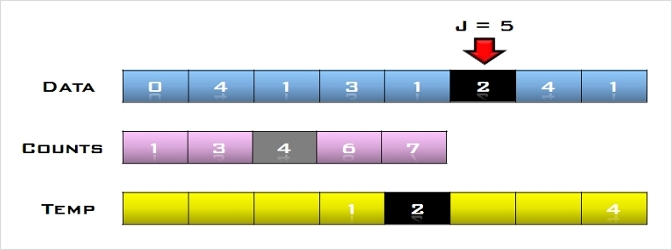
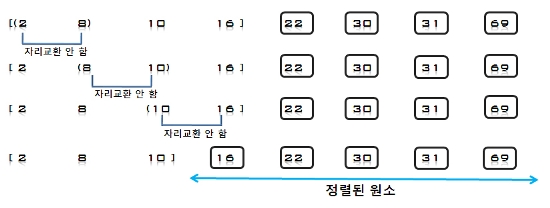
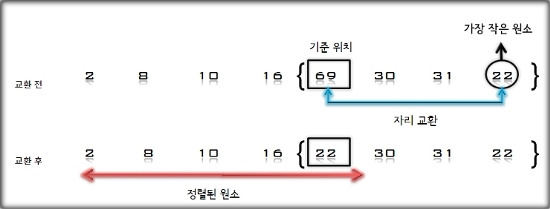
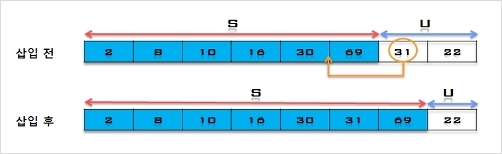
6. U의 첫 번째 원소 31을 S의 마지막 원소 69와 비교하여 (31 < 69)이므로 그 앞자리 원소 30과 비교한다. (31 > 30)이므로 원소30과
69 사이에 삽입한다.
S = [2, 8, 10, 16, 30, 31, 69], U = [22]
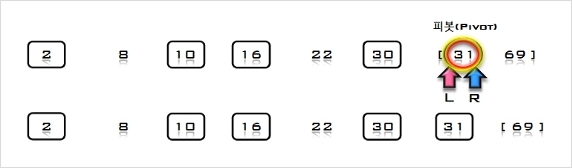
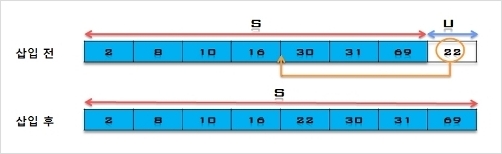
7. U의 첫 번째 원소 22를 S의 마지막 원소 69와 비교하여 (22 < 69)이므로 그 앞자리 원소 31과 비교한다. (22 < 31)이므로 그앞자리
원소 30과 비교한다. (22 < 30)이므로 다시 그 앞자리 원소 16과 비교하여, (22 > 16)이므로 원소 16과 30사이에 삽입한다.
S = [2, 8, 10, 16, 22, 30, 31, 69], U = []

- 삽입 정렬 알고리즘의 분석
- 메모리 사용공간
- 연산 시간
- 최선의 경우 : 원소들이 이미 정렬되어 있어서 비교횟수가 최소인 경우
- 이미 정렬되어있는 경우에는 바로 앞자리 원소와 한번만 비교한다.
- 전체 비교횟수 = n-1
- 시간 복잡도 : O(n)
- 최악의 경우 : 모든 원소가 역순으로 되어있어서 비굣횟수가 최대인 경우
- 전체 비교횟수 = 1+2+3+...+(n-1) = n(n-1)/2
- 시간 복잡도 : O(n²)
- 삽입 정렬의 평균 비교횟수 = n(n-1)/4
- 평균 시간 복잡도 : O(n²)