반응형
악성 쿼리가 하나 있다.
테이블 네 개를 조인하여 실행하는데, 가장 큰 테이블도 2만건이 안된다.
그런데 실행시간이 무려 2분이 넘게 걸린다.
문제의 쿼리는 다음과 같다.
- SET STATISTICS TIME ON
- SET STATISTICS IO ON
- -- 기존 쿼리
- SELECT DISTINCT
- A.Sw_Seq Sw_Seq, A.Seq Seq, B.File_Desc File_Desc, D.USER_NAME USER_NAME,
- ISNULL(C.HNAME,'') HNAME, A.START_TIME START_TIME,
- A.END_TIME END_TIME, A.Running RUNNING,
- dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'A') All_Count,
- dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'M') Msg_Count,
- dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'O') OK_Count,
- dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'F') Fail_Count,
- dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq,'D') Done_Count
- FROM SCHED A, USER_GROUP D, POLICY B
- LEFT JOIN PC_USER C
- ON B.REG_EMPNO = C.EMPNO
- WHERE
- A.Sw_Seq = B.Sw_Seq AND
- A.Seq = D.SEQ AND
- A.Running IN ('Y','N')
SET STATISTICS TIME ON
SET STATISTICS IO ON
-- 기존 쿼리
SELECT DISTINCT
A.Sw_Seq Sw_Seq, A.Seq Seq, B.File_Desc File_Desc, D.USER_NAME USER_NAME,
ISNULL(C.HNAME,'') HNAME, A.START_TIME START_TIME,
A.END_TIME END_TIME, A.Running RUNNING,
dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'A') All_Count,
dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'M') Msg_Count,
dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'O') OK_Count,
dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq, 'F') Fail_Count,
dbo.UFN_COUNT_ALL(A.Sw_Seq, A.Seq,'D') Done_Count
FROM SCHED A, USER_GROUP D, POLICY B
LEFT JOIN PC_USER C
ON B.REG_EMPNO = C.EMPNO
WHERE
A.Sw_Seq = B.Sw_Seq AND
A.Seq = D.SEQ AND
A.Running IN ('Y','N') 실행시간과 IO 측정 결과는 다음과 같다.
(8개 행 적용됨)
테이블 'Worktable'. 검색 수 0, 논리적 읽기 수 0, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'GROUP'. 검색 수 9, 논리적 읽기 수 294, 물리적 읽기 수 3, 미리 읽기 수 1, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'POLICY'. 검색 수 0, 논리적 읽기 수 18, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'SCHED'. 검색 수 1, 논리적 읽기 수 2, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'USER'. 검색 수 1, 논리적 읽기 수 3, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'Worktable'. 검색 수 0, 논리적 읽기 수 0, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'GROUP'. 검색 수 9, 논리적 읽기 수 294, 물리적 읽기 수 3, 미리 읽기 수 1, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'POLICY'. 검색 수 0, 논리적 읽기 수 18, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'SCHED'. 검색 수 1, 논리적 읽기 수 2, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'USER'. 검색 수 1, 논리적 읽기 수 3, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
SQL Server 실행 시간:
CPU 시간 = 200828ms, 경과 시간 = 201734ms.
CPU 시간 = 200828ms, 경과 시간 = 201734ms.
아무리 들여다 봐도 이해가 되지 않았다.
어떻게 I/O를 다 합쳐도 300페이지 정도밖에 안되는데 2분이 넘게 걸릴 수가 있나?? 내가 귀신에 홀렸나??
문제는 저 사용자 정의 함수였다.
예전부터 알고는 있었지만... 저렇게 SELECT 뒤에 컬럼이 많은 데다가... 실제 SQL에서는 저렇게 보기좋게 Indentation이 되어 있지 않아서리.. 사용자 정의함수가 있는줄 몰랐었다. ㅡ.ㅜ
삼십분 넘게 FROM절이랑 WHERE절만 뒤지고 있었으니 답이 나올 리가 있나...
저 사용자 정의 함수 안에는 count 함수가 잔뜩 들어 있었다.
그런데 문제의 지점이 사용자 정의함수 안에 숨겨져 있어서 눈에 띄지 않았던 거다.
....
문제를 찾았으니 개선만 하면 된다.
사용자 정의 함수가 DISTINCT에 의해 필터링되기 전에 수행되기 때문에 큰 I/O를 발생시키는 count 함수가 불필요하게 중복되어 실행되고 있었다.
마지막에 한번만 실행되도록 DISTINCT 바깥으로 빼주면 되겠다.
문제는 저 사용자 정의 함수였다.
사용자 정의 함수 내에서 발생하는 I/O 는 실행계획이나 쿼리창에서 측정하는 I/O 에
나타나지 않는다.
나타나지 않는다.
예전부터 알고는 있었지만... 저렇게 SELECT 뒤에 컬럼이 많은 데다가... 실제 SQL에서는 저렇게 보기좋게 Indentation이 되어 있지 않아서리.. 사용자 정의함수가 있는줄 몰랐었다. ㅡ.ㅜ
삼십분 넘게 FROM절이랑 WHERE절만 뒤지고 있었으니 답이 나올 리가 있나...
저 사용자 정의 함수 안에는 count 함수가 잔뜩 들어 있었다.
그런데 문제의 지점이 사용자 정의함수 안에 숨겨져 있어서 눈에 띄지 않았던 거다.
....
문제를 찾았으니 개선만 하면 된다.
사용자 정의 함수가 DISTINCT에 의해 필터링되기 전에 수행되기 때문에 큰 I/O를 발생시키는 count 함수가 불필요하게 중복되어 실행되고 있었다.
마지막에 한번만 실행되도록 DISTINCT 바깥으로 빼주면 되겠다.
- -- 개선된 쿼리
- SELECT
- SubTable.Sw_Seq Sw_Seq, SubTable.Seq Seq, SubTable.File_Desc File_Desc,
- SubTable.USER_NAME USER_NAME, SubTable.HNAME,
- SubTable.START_TIME START_TIME,
- SubTable.END_TIME END_TIME, SubTable.Running RUNNING,
- dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'A') All_Count,
- dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'M') Msg_Count,
- dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'O') OK_Count,
- dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'F') Fail_Count,
- dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'D') Done_Count
- FROM
- (
- SELECT DISTINCT
- A.Sw_Seq Sw_Seq, A.Seq Seq, B.File_Desc File_Desc,
- D.NAME NAME, ISNULL(C.HNAME,'') HNAME, A.START_TIME START_TIME,
- A.END_TIME END_TIME, A.Running RUNNING
- FROM SCHED A, USER_GROUP D, POLICY B
- LEFT JOIN PC_USER C
- ON B.REG_EMPNO = C.EMPNO
- WHERE
- A.Sw_Seq = B.Sw_Seq AND
- A.Seq = D.SEQ AND
- A.Running IN ('Y','N')
- ) SubTable
-- 개선된 쿼리
SELECT
SubTable.Sw_Seq Sw_Seq, SubTable.Seq Seq, SubTable.File_Desc File_Desc,
SubTable.USER_NAME USER_NAME, SubTable.HNAME,
SubTable.START_TIME START_TIME,
SubTable.END_TIME END_TIME, SubTable.Running RUNNING,
dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'A') All_Count,
dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'M') Msg_Count,
dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'O') OK_Count,
dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'F') Fail_Count,
dbo.UFN_COUNT_ALL(SubTable.Sw_Seq, SubTable.Seq, 'D') Done_Count
FROM
(
SELECT DISTINCT
A.Sw_Seq Sw_Seq, A.Seq Seq, B.File_Desc File_Desc,
D.NAME NAME, ISNULL(C.HNAME,'') HNAME, A.START_TIME START_TIME,
A.END_TIME END_TIME, A.Running RUNNING
FROM SCHED A, USER_GROUP D, POLICY B
LEFT JOIN PC_USER C
ON B.REG_EMPNO = C.EMPNO
WHERE
A.Sw_Seq = B.Sw_Seq AND
A.Seq = D.SEQ AND
A.Running IN ('Y','N')
) SubTable
개선된 결과는 다음과 같다.
(8개 행 적용됨)
테이블 'Worktable'. 검색 수 0, 논리적 읽기 수 0, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'GROUP'. 검색 수 9, 논리적 읽기 수 294, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'POLICY'. 검색 수 0, 논리적 읽기 수 18, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 'SCHED'. 검색 수 1, 논리적 읽기 수 2, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
테이블 ' USER'. 검색 수 1, 논리적 읽기 수 3, 물리적 읽기 수 0, 미리 읽기 수 0, LOB 논리적 읽기 수 0, LOB 물리적 읽기 수 0, LOB 미리 읽기 수 0.
SQL Server 실행 시간:
CPU 시간 = 782ms, 경과 시간 = 777ms.
에... 201 초가 0.7초로 단축되었으면.. 몇 % 개선이지?? ^^a
결론은 이거다.
사용자 정의함수 안에서 성능 문제가 발생하면 찾아내기 매우 어려우므로,
사용자 정의 함수를 사용할 때는 처음부터 퍼포먼스를 생각하라.
사용자 정의 함수를 사용할 때는 처음부터 퍼포먼스를 생각하라.
반응형
'연구개발 > SQL2005' 카테고리의 다른 글
| SQL Server 튜닝시 성능모니터를 활용한 H/W 병목 진단 가이드 (0) | 2009.06.28 |
|---|---|
| Query의 Recompile 문제에 관하여 : 쿼리 매개변수화 (0) | 2009.06.27 |
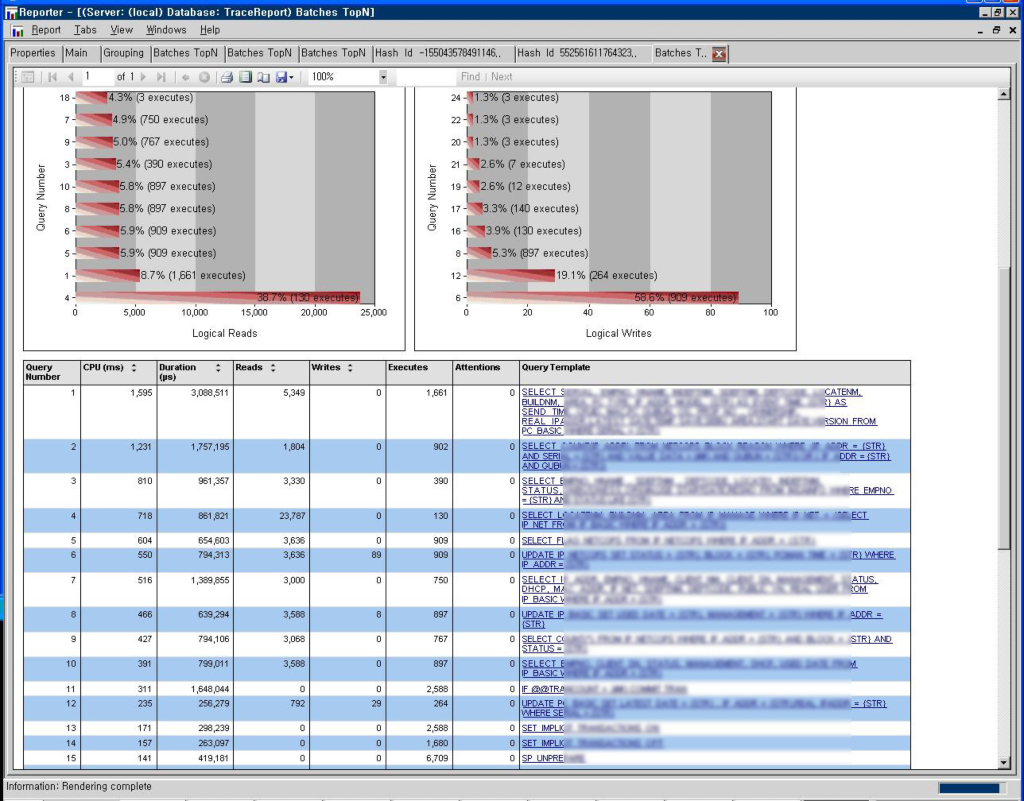
| 악성 쿼리 찾아내기(3) - 프로필러(Profiler)로 수집한 .trc 파일을 ReadTrace로 분석하기 (0) | 2009.06.27 |
| 악성 쿼리 찾아내기(2) - ClearTrace (0) | 2009.06.27 |
| 악성 쿼리 찾아내기(1) - ReadTrace (0) | 2009.06.27 |
 william_read80trace-macro3.zip
william_read80trace-macro3.zip






 TraceCaptureDef.sql
TraceCaptureDef.sql