lsof -i :8080
kill {PID}
'연구개발 > Etc..' 카테고리의 다른 글
| [Docker] 생성 및 실행 (0) | 2018.07.04 |
|---|---|
| 운영체제 개론 (0) | 2017.05.29 |
| 지표 관련 용어 (0) | 2016.08.22 |
| unity key (0) | 2016.05.07 |
| RAID 1+0 과 0+1의 차이점 (0) | 2011.07.11 |
lsof -i :8080
kill {PID}
| [Docker] 생성 및 실행 (0) | 2018.07.04 |
|---|---|
| 운영체제 개론 (0) | 2017.05.29 |
| 지표 관련 용어 (0) | 2016.08.22 |
| unity key (0) | 2016.05.07 |
| RAID 1+0 과 0+1의 차이점 (0) | 2011.07.11 |
config server
yml 설정
dev, beta, prod
spring cloud bus 사용 - mq 사용하면 편함
| gateway (0) | 2024.01.17 |
|---|---|
| h2 database (0) | 2024.01.16 |
| 'io.netty:netty-resolver-dns-native-macos'. Use DEBUG level to see the full stack: java.lang.UnsatisfiedLinkError: failed to load the required native library (0) | 2024.01.15 |
| 03. API Gateway Service (0) | 2024.01.15 |
| 02. user service (0) | 2024.01.15 |
gateway 에서 당연히 url filter 설정 & token 검증, 등등.. 진
| 04. spring cloud config (0) | 2024.01.18 |
|---|---|
| h2 database (0) | 2024.01.16 |
| 'io.netty:netty-resolver-dns-native-macos'. Use DEBUG level to see the full stack: java.lang.UnsatisfiedLinkError: failed to load the required native library (0) | 2024.01.15 |
| 03. API Gateway Service (0) | 2024.01.15 |
| 02. user service (0) | 2024.01.15 |
보안 뭐시기 하면서 연결이 안된다면..
entity class 하나 맹글어주고 application.yml 에 jpa 설정 추가해주면 해결 끝
application.yml
jpa:
hibernate:
ddl-auto: create-drop
show-sql: true
User.class
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
| 04. spring cloud config (0) | 2024.01.18 |
|---|---|
| gateway (0) | 2024.01.17 |
| 'io.netty:netty-resolver-dns-native-macos'. Use DEBUG level to see the full stack: java.lang.UnsatisfiedLinkError: failed to load the required native library (0) | 2024.01.15 |
| 03. API Gateway Service (0) | 2024.01.15 |
| 02. user service (0) | 2024.01.15 |
gradle
implementation 'io.netty:netty-resolver-dns-native-macos:4.1.104.Final:osx-aarch_64'
maven
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-resolver-dns-native-macos</artifactId>
<version>4.1.104.Final</version>
<classifier>osx-aarch_64</classifier>
</dependency>| gateway (0) | 2024.01.17 |
|---|---|
| h2 database (0) | 2024.01.16 |
| 03. API Gateway Service (0) | 2024.01.15 |
| 02. user service (0) | 2024.01.15 |
| 01. Service Discovery (0) | 2024.01.15 |
인증, 권한 부여
서비스 검색 통합
응답 캐싱
정책, 회로 차단기 & Qos 다시 시도
속도 제한
부하 분산
로깅, 추적, 상관 관계
헤더, 쿼리 문자열 및 청구 변환
IP 허용 목록 추가 (whitelist)
| gateway (0) | 2024.01.17 |
|---|---|
| h2 database (0) | 2024.01.16 |
| 'io.netty:netty-resolver-dns-native-macos'. Use DEBUG level to see the full stack: java.lang.UnsatisfiedLinkError: failed to load the required native library (0) | 2024.01.15 |
| 02. user service (0) | 2024.01.15 |
| 01. Service Discovery (0) | 2024.01.15 |
eureka 에 user service 등록
1. intellij로 실행
vm option 에서 -Dserver.port=포트
2. mvn으로 실행
mvn spring-boot:run -Dspring-boot.run.jvmArguments='-Dserver.port=포트'
3. command로 실행
java -jar -Dserver.port=포트 ./target/user-service-0.0.1-SNAPSHOT.jar
| gateway (0) | 2024.01.17 |
|---|---|
| h2 database (0) | 2024.01.16 |
| 'io.netty:netty-resolver-dns-native-macos'. Use DEBUG level to see the full stack: java.lang.UnsatisfiedLinkError: failed to load the required native library (0) | 2024.01.15 |
| 03. API Gateway Service (0) | 2024.01.15 |
| 01. Service Discovery (0) | 2024.01.15 |
서비스 등록
Load Balance
서비스 구성확인 (서비스 목록 확인)
| gateway (0) | 2024.01.17 |
|---|---|
| h2 database (0) | 2024.01.16 |
| 'io.netty:netty-resolver-dns-native-macos'. Use DEBUG level to see the full stack: java.lang.UnsatisfiedLinkError: failed to load the required native library (0) | 2024.01.15 |
| 03. API Gateway Service (0) | 2024.01.15 |
| 02. user service (0) | 2024.01.15 |
confluent/etc/kafka 의 server.properties 를
server_01.properties, server_02.properties, server_03.properties 형식으로 복사 후
broker id 변경, 접속 주소 변경, kafka 로그 저장 주소 변경
broker.id = {인식숫자} 1, 2, 3, 4 같이 순번으로
listeners=PLAINTEXT://0.0.0.0:9092 / 0.0.0.0:9093 / 0.0.0.0:9094 형식으로 (외부/내부 접속 가능)
내부만 접속 시 localhost:9092 / localhost:9093 / localhost:9094
advertied.listeners=PLAINTEXT://{ec2 DNS}:9092 / 9093 / 9094
log.dirs=/home/ubuntu/kafka-logs-01 / 02 / 03
으로 변경
실행은 각각 실행
ex) confluent/bin/kafka-server-start confluent/etc/kafka/server.properties <- 위의 파일 순번대로
멀티 브로커 사용시 zookeeper.properties 그대로 사용하지 말고 zookeeper의 dataDir를 별도 구성
| Kafka ec2 외부 연결 (0) | 2023.10.05 |
|---|
Java Source 상에는 ec2 의 외부 접속 아이피를 적용
예) 15.164.90.79:9092
ec2 내부와 외부를 모두 사용하기 위해서는
ec2 의 kafka 폴더의 etc 안 kafka 폴더에서 server.properties
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listener=PLAINTEXT://{여기에 ec2의 dns 주소를 쓰고}:9092
하면 끝..
| kafka multi broker (0) | 2023.10.13 |
|---|
sudo spctl --master-disable
cd data_directory
mongod --dbpath=data/db
new window
mongo
sudo spctl --master-enable
| [MongoDB] Replication and Repica Sets 만들기 (0) | 2014.09.02 |
|---|---|
| MongoDB : Ubuntu Server에서 MongoDB replication 설정 (0) | 2014.09.02 |
| Mongostat (0) | 2014.04.08 |
| mongo db 설정 (0) | 2012.12.18 |
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
# tf.compat.v1.disable_eager_execution()
# config = tf.compat.v1.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.1
# set_session(tf.compat.v1.Session(config=config))
config = tf.compat.v1.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.1
tf.compat.v1.keras.backend.set_session(tf.compat.v1.Session(config=config))
| [Chapter6] 모델 평가와 하이퍼파라미터 튜닝에 관한 사례학습 (0) | 2017.12.05 |
|---|---|
| [Chapter5] 차원축소를 이용한 데이터 압축 (0) | 2017.12.05 |
| [Chapter4] 데이터 전처리 (0) | 2017.12.04 |
| 모두를 위한 머신러닝과 딥러닝의 강의 (0) | 2017.03.13 |
| 7. 매트릭스와 벡터 계산하기(Linear algebra) (0) | 2017.03.03 |
로그 파일 업데이트 되는 내용을 보려면 tail을 사용하면 된다.
tail -f log.txt이렇게 하면 log.txt파일에 새로 추가된 내용이 화면에 출력된다.
ssh로 원격에 있는 서버의 로그 파일도 볼 수 있다.
ssh user@host "tail -f /locaion/to/log/file"서버가 두대여서 터미널 창 두개 열어놓고 보고 있었는데 현진한테 물어보니 multitail을 사용하면 된다고 한다. 찾아보니 관련 글도 많다.
일단 맥에는 multitail이 없으니 brew install multitail로 설치한다.
그러고 위의 링크에 나와있는대로 해보면 화면이 분할되어서 로그파일이 나온다.
multitail -l 'ssh user@host1 "tail -f /var/log/apache2/error.log"' -l 'ssh user@host2 "tail -f /var/log/apache2/error.log"'상하좌우 화면 분할도 자유롭고 보고있는 파일명도 아래에 표시되어서 훨씬 알아보기 쉽다.
| jenkins (젠킨스) 설치 (0) | 2017.07.06 |
|---|---|
| 우분투 계정 관리 (0) | 2017.06.13 |
| 한글 (0) | 2016.05.22 |
| [Ubuntu] 시간 동기화 - ntpdate (0) | 2014.12.12 |
| ubuntu mysql 삭제 (0) | 2014.10.27 |
도커 명령어
| 옵션 | 설명 |
|---|---|
| -d | detached mode (백그라운드 모드) |
| -p | Host와 컨테이너의 Port를 연결 (fowarding) |
| -v | Host와 컨테이너의 Directory 연결 (마운트) |
| -e | 컨테이너 내에서 사용할 환경변수 설정 |
| -it | -i와 -t를 동시에 사용한 것으로 터미널 입력을 위한 옵션 |
| --rm | 프로세스 종료시 컨테이너 자동 제거 |
| --link | 컨테이너 연결[컨테이너명:별칭] |
| --name | 컨테이너 이름 설정 |
도커 실행중인지 확인 docker version
C:\Users\bactoria>docker version Client: Version: 18.03.0-ce API version: 1.37 Go version: go1.9.4 Git commit: 0520e24 Built: Wed Mar 21 23:06:28 2018 OS/Arch: windows/amd64 Experimental: false Orchestrator: swarm Server: Engine: Version: 18.03.0-ce API version: 1.37 (minimum version 1.12) Go version: go1.9.4 Git commit: 0520e24 Built: Wed Mar 21 23:14:32 2018 OS/Arch: linux/amd64 Experimental: false C:\Users\bactoria>
우분투 이미지 다운로드 docker pull ubuntu:16.04
C:\Users\bactoria>docker pull ubuntu:16.04 16.04: Pulling from library/ubuntu 22dc81ace0ea: Pull complete 1a8b3c87dba3: Pull complete 91390a1c435a: Pull complete 07844b14977e: Pull complete b78396653dae: Pull complete Digest: sha256:e348fbbea0e0a0e73ab0370de151e7800684445c509d46195aef73e090a49bd6 Status: Downloaded newer image for ubuntu:16.04 C:\Users\bactoria>
이미지 확인하기 docker images
C:\Users\bactoria>docker images REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu 16.04 f975c5035748 2 weeks ago 112MB C:\Users\bactoria>
우분투 컨테이너 실행하기 docker run -it --name myUbuntu ubuntu:16.04 /bin/bash
C:\Users\bactoria>docker run -it --name myUbuntu ubuntu:16.04 /bin/bash root@27db33196683:/#
리눅스 접속 확인하기 ls
root@27db33196683:/# ls bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var root@27db33196683:/#
우분투 컨테이너 종료하기 exit
root@27db33196683:/# exit exit C:\Users\bactoria>
실행중인 컨테이너 확인하기 docker ps
C:\Users\bactoria>docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES C:\Users\bactoria>
모든 컨테이너 확인하기 docker ps -a
C:\Users\bactoria>docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES be76370e89aa ubuntu:16.04 "/bin/bash" 45 seconds ago Exited (0) 15 seconds ago myUbuntu C:\Users\bactoria>
종료된 우분투 컨테이너 실행하기 docker start myUbuntu
C:\Users\bactoria>docker start myUbuntu myUbuntu C:\Users\bactoria>
우분투 컨테이너 접속하기 docker attach myUbuntu + Enter X2
C:\Users\bactoria>docker attach myUbuntu root@be76370e89aa:/# root@be76370e89aa:/#
우분투 컨테이너 빠져나가기 Ctrl+p + Ctrl+q
(컨테이너 종료하지 않음)
root@be76370e89aa:/# root@be76370e89aa:/# read escape sequence C:\Users\bactoria>
실행중인 모든 컨테이너 확인하기 docker ps
C:\Users\bactoria>docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES be76370e89aa ubuntu:16.04 "/bin/bash" 5 minutes ago Up 3 minutes myUbuntu C:\Users\bactoria>
우분투 컨테이너 종료하기 docker stop myUbuntu
C:\Users\bactoria>docker stop myUbuntu myUbuntu C:\Users\bactoria>
이미지 제거하기 docker rmi ubuntu:16.04
(삭제안됨)
C:\Users\bactoria>docker rmi ubuntu:16.04 Error response from daemon: conflict: unable to remove repository reference "ubuntu:16.04" (must force) - container be76370e89aa is using its referenced image f975c5035748 C:\Users\bactoria>
컨테이너 제거하기 docker rm myUbuntu
(이미지 제거하려면 컨테이너 먼저 제거해야 함)
C:\Users\bactoria>docker rm myUbuntu myUbuntu C:\Users\bactoria>
컨테이너 제거 확인 docker ps -a
(삭제되어서 없어졌을거임)
C:\Users\bactoria>docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES C:\Users\bactoria>
이미지 보기 docker images
C:\Users\bactoria>docker images REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu 16.04 f975c5035748 2 weeks ago 112MB C:\Users\bactoria>
이미지 삭제하기 docker rmi ubuntu:16.04
C:\Users\bactoria>docker rmi ubuntu:16.04 Untagged: ubuntu:16.04 Untagged: ubuntu@sha256:e348fbbea0e0a0e73ab0370de151e7800684445c509d46195aef73e090a49bd6 Deleted: sha256:f975c50357489439eb9145dbfa16bb7cd06c02c31aa4df45c77de4d2baa4e232 Deleted: sha256:0bd983fc698ee9453dd7d21f8572ea1016ec9255346ceabb0f9e173b4348644f Deleted: sha256:08fe90e1a1644431accc00cc80f519f4628dbf06a653c76800b116d3333d2b6d Deleted: sha256:5dc5eef2b94edd185b4d39586e7beb385a54b6bac05d165c9d47494492448235 Deleted: sha256:14a40a140881d18382e13b37588b3aa70097bb4f3fb44085bc95663bdc68fe20 Deleted: sha256:a94e0d5a7c404d0e6fa15d8cd4010e69663bd8813b5117fbad71365a73656df9 C:\Users\bactoria>
무에서 유를 창조하고
다시 무로 돌아갔다.
안보고 우분투 컨테이너 생성까지 가즈아~
docker version에서 Server가 안뜰 때| mac port kill (0) | 2024.01.31 |
|---|---|
| 운영체제 개론 (0) | 2017.05.29 |
| 지표 관련 용어 (0) | 2016.08.22 |
| unity key (0) | 2016.05.07 |
| RAID 1+0 과 0+1의 차이점 (0) | 2011.07.11 |
http://symplog.tistory.com/266
| oracle mssql linked server (0) | 2018.04.17 |
|---|---|
| select 처리순서 (0) | 2017.08.02 |
| Microsoft Windows DistributedCOM 오류 로그 (0) | 2016.03.23 |
| mssql 권한설정 (0) | 2016.03.16 |
| tempdb 분리 (0) | 2016.03.15 |
https://blogs.msdn.microsoft.com/dbrowne/2013/10/02/creating-a-linked-server-for-oracle-in-64bit-sql-server/
exec master.dbo.sp_MSset_oledb_prop 'ORAOLEDB.Oracle', N'AllowInProcess', 1
exec master.dbo.sp_MSset_oledb_prop 'ORAOLEDB.Oracle', N'DynamicParameters', 1
exec sp_addlinkedserver N'MyOracle', 'Oracle', 'ORAOLEDB.Oracle', N'//192.168.10.80:1521/myora', N'FetchSize=5000', ''
exec master.dbo.sp_serveroption @server=N'MyOracle', @optname=N'rpc out', @optvalue=N'true'
exec sp_addlinkedsrvlogin @rmtsrvname='MyOracle', @useself=N'FALSE', @rmtuser=N'system', @rmtpassword='head1ton'
exec ('select 1 a from dual') at MyOracle
| Mysql Mssql linked server (0) | 2018.04.17 |
|---|---|
| select 처리순서 (0) | 2017.08.02 |
| Microsoft Windows DistributedCOM 오류 로그 (0) | 2016.03.23 |
| mssql 권한설정 (0) | 2016.03.16 |
| tempdb 분리 (0) | 2016.03.15 |
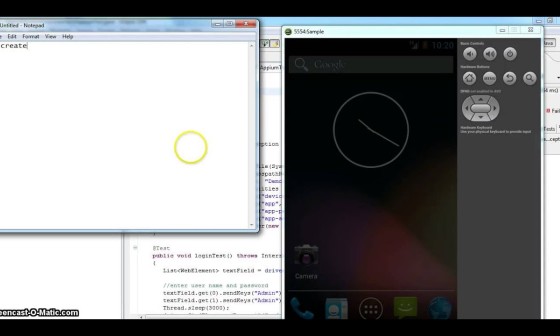
앞에 설명한 것에 이어서 인제 앞에서 짠것과 같은 코드를 DeviceFarm에 올리는 방법에 대해 설명하겠다. 그냥 지금 프로젝트를 압축해서 올리면 DeviceFarm에서는 돌아가지 않는다. Maven 프로젝트로 만들어줘야 한다. Maven을 잘 모르더라도 겁먹을 필요는 없다. 그냥 설명하는 대로 잘 따라하면 제대로 동작한다.
그리고 아직 AWS DeviceFarm에 대해 더 자세히 알고 싶으면 http://docs.aws.amazon.com/devicefarm/latest/developerguide/devicefarm-dg.pdf
에 접속해서 저 PDF를 꼼꼼히 읽어보길 바란다.
여기서는 Working with Appium Java TestNG for Android and Device Farm 이부분만을 보면된다.
혹시라도 완성된 다른코드를 보고 싶으면 사람을 위해
https://github.com/awslabs/aws-device-farm-appium-tests-for-sample-app
이 코드를 보고 참고해서 만들면 된다.
우선 Maven 프로젝트를 만들어준다. 툴을 Eclipse이다.
빨간색 표시된 곳을 눌러 MavenProject를 만들어 준다.
그리고 그냥 다 Next를 눌러 완성 시킨 후 pom.xml을 우선 셋팅해준다.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.acme</groupId>
<artifactId>acme-android-appium</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.8.8</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.appium</groupId>
<artifactId>java-client</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.6</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>test-jar</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.10</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/dependency-jars/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.5.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
<configuration>
<finalName>zip-with-dependencies</finalName>
<appendAssemblyId>false</appendAssemblyId>
<descriptors>
<descriptor>src/main/assembly/zip.xml</descriptor>
</descriptors>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
위와 같이 설정을 해준 후 src안에 main 과 test패키지를 만들어준다. 그 이후 main 안에는 assembly안에 zip.xml파일을 만들어준다.
zip.xml의 내용은
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id>zip</id>
<formats>
<format>zip</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>${project.build.directory}</directory>
<outputDirectory>./</outputDirectory>
<includes>
<include>*.jar</include>
</includes>
</fileSet>
<fileSet>
<directory>${project.build.directory}</directory>
<outputDirectory>./</outputDirectory>
<includes>
<include>/dependency-jars/</include>
</includes>
</fileSet>
</fileSets>
</assembly>
와 같다.
위와 같은 구조로 만들어 준 후 page, 와 test는 테스트 코드들이다. 저것과 꼭 똑같이 할필요는 없다. 그냥 테스트 코드를 저 위치에 test패키지안에 넣어주면 된다. 주의할점은 selenium의 라이브러리 값들을 maven이 가져오는 depedency들에게 맞춰서 다시 임포트 해줘야한다.
이후에는 cmd 창에가서 mvn package install 를 해주면 target에 pom에 설정해두었던 대로 폴더들이 생성된다.
여기서 중요한 것은 zip-with-depedencies 파일이다. 이것을 deviceFarm에 올려주면 된다.
DeviceFarm에 테스트를 설정하는 것은 매우 간단하므로 굳이 설명하지 않겠다.
이것보다 더 나은 방법도 있을 수 있다. 그러나 나처럼 삽질하시는 분들이 없으면 하는 마음에 포스트를 작성해보았다. 그나마 삽질하시는 분들에게 조금이나마 도움이되었으면한다.
| [Appium, TestNG, AWS DevicaFarm] 안드로이드 자동화 테스트하기 1 -(Appium 셋팅, TestCode 셋팅) (0) | 2018.01.04 |
|---|---|
| ec2 apm 설치 (0) | 2017.09.02 |
| AWS EC2 생성 후 접속(pem -> ssh-keygen) (0) | 2017.08.08 |
| openvpn aws (0) | 2017.07.26 |
| lrzsz (0) | 2017.07.12 |
이번에 내가 있던 스타트업에서 안드로이드 어플을 런칭할 기회가 생겨 테스트를 위해 AWS DeviceFarm 을 이용하여 테스트를 해볼 기회가 생겼다. 안드로이드 기기를 실제로 Device와 OS 버전을 전부 맞춰서 일일이 테스트하기란 거의 불가능에 가깝다. 그래서 자동화 테스트툴 Appium , Calabash, uiAutomator등이 나오게 되었고 DeviceFarm은 이런 자동화테스트 툴을 이용하여 실제 디바이스에서 테스트하는 것을 간단한 조작 만으로 가능하게 해주었다.
그 과정이 한글로된 문서들이 없어서 힘들어할 사람들을 위해 내가 삽질했던 부분들을 다른 분들은 좀 더 편하게 작업하시라고 포스트를 할려고한다.
먼저 Appium을 설치해야한다. 그리고 자신이 만들 프로젝트에 Selenium 라이브러리를 추가해주어야한다. 먼저 Appium 을 설치하는 방법이다.
일단 이동영상을 먼저 보면 어떻게 설치하고 돌려야하는지 대충 감이 잡힌다.
https://www.youtube.com/watch?v=FJ_GwSApOpo
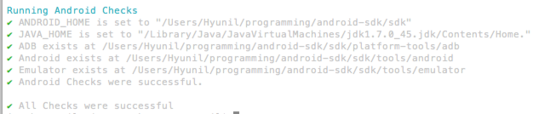
https://github.com/testvagrant/AppiumDemo
| [Appium, TestNG, AWS DevicaFarm] 안드로이드 자동화 테스트하기 2 -(Device Farm에 올리기 위한 셋팅 ) (0) | 2018.01.04 |
|---|---|
| ec2 apm 설치 (0) | 2017.09.02 |
| AWS EC2 생성 후 접속(pem -> ssh-keygen) (0) | 2017.08.08 |
| openvpn aws (0) | 2017.07.26 |
| lrzsz (0) | 2017.07.12 |
1. AWS EC2 접속
2. AMI 버전 확인
$ grep . /etc/*-release
/etc/os-release:NAME="Amazon Linux AMI"
/etc/os-release:VERSION="2017.03"
/etc/os-release:ID="amzn"
/etc/os-release:ID_LIKE="rhel fedora"
/etc/os-release:VERSION_ID="2017.03"
/etc/os-release:PRETTY_NAME="Amazon Linux AMI 2017.03"
/etc/os-release:ANSI_COLOR="0;33"
/etc/os-release:CPE_NAME="cpe:/o:amazon:linux:2017.03:ga"
/etc/os-release:HOME_URL="http://aws.amazon.com/amazon-linux-ami/"
/etc/system-release:Amazon Linux AMI release 2017.03
3. Java 1.8 설치
$ java -version
java version "1.7.0_151"
OpenJDK Runtime Environment (amzn-2.6.11.0.74.amzn1-x86_64 u151-b00)
OpenJDK 64-Bit Server VM (build 24.151-b00, mixed mode)
$ sudo yum install java-1.8.0
$ sudo yum remove java-1.7.0
$ java -version
openjdk version "1.8.0_141"
OpenJDK Runtime Environment (build 1.8.0_141-b16)
OpenJDK 64-Bit Server VM (build 25.141-b16, mixed mode)
4. Scala 설치
$ wget https://downloads.lightbend.com/scala/2.12.3/scala-2.12.3.tgz
$ tar xzvf scala-2.12.3.tgz
$ sudo su -
# cd /home/ec2-user/
# mv scala-2.12.3 /usr/local/scala
# exit
$ sudo vi /etc/profile
export PATH=$PATH:/usr/local/scala/bin
$ source /etc/profile
$ scala -version
Scala code runner version 2.12.3 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.
5. Spark 설치
* 주의 사항 : AWS t2.large 인스턴스 정도가 되어야 정상 동작함 (t2.small에서는 Spark Streaming 정상 동작 하지 않음)
$ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
$ tar xvzf spark-2.2.0-bin-hadoop2.7.tgz
$ sudo su -
# cd /home/ec2-user/
# mv spark-2.2.0-bin-hadoop2.7 /usr/local/spark
# exit
$ sudo vi /etc/profile
export PATH=$PATH:/usr/local/spark/bin
$ source /etc/profile
$ spark-shell
6. Kafka 설치 및 데몬 실행
$ wget http://apache.mirror.cdnetworks.com/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz
$ tar xzvf kafka_2.11-0.11.0.0.tgz
$ ln -s kafka_2.11-0.11.0.0 kafka
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
$ bin/kafka-server-start.sh -daemon config/server.properties
7. MongoDB 설치 및 서비스 실행
$ sudo su
# vi /etc/yum.repos.d/mongodb-org-3.4.repo
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/amazon/2013.03/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
# yum install -y mongodb-org
# service mongod start
# mongo
# exit
8. Redis 설치 및 서비스 실행
$ sudo yum -y update
$ sudo yum -y install gcc make
$ sudo wget http://download.redis.io/redis-stable.tar.gz
$ tar xvzf redis-stable.tar.gz
$ cd redis-stable
$ sudo make install
$ sudo mkdir -p /etc/redis /var/lib/redis /var/redis/6379
$ sudo cp redis.conf /etc/redis/6379.conf
$ sudo vi /etc/redis/6379.conf
daemonize yes
logfile /var/log/redis_6379.log
dir /var/redis/6379
$ sudo wget https://raw.githubusercontent.com/saxenap/install-redis-amazon-linux-centos/master/redis-server
$ sudo mv redis-server /etc/init.d
$ sudo chmod 755 /etc/init.d/redis-server
$ sudo vi /etc/init.d/redis-server
REDIS_CONF_FILE="/etc/redis/6379.conf"
$ sudo chkconfig --add redis-server
$ sudo chkconfig --level 345 redis-server on
$ sudo service redis-server start
9. Node.js 개발 환경 구축
$ sudo yum install git-core
$ sudo yum install nodejs npm --enablerepo=epel
$ npm -v
1.3.6
$ sudo npm update -g npm
$ npm -v
5.3.0
$ npm install
$ sudo npm cache clean -f
$ sudo npm install -g n
$ sudo n 6.11.1
$ node -v
v0.10.48
재접속
$ node -v
v6.11.1
10. Maven 개발 환경 구축
$ sudo yum install java-1.8.0-openjdk-devel.x86_64
$ sudo alternatives --config java
$ sudo alternatives --config javac
$ javac -version
javac 1.8.0_141
$ sudo wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
$ sudo sed -i s/\$releasever/6/g /etc/yum.repos.d/epel-apache-maven.repo
$ sudo yum install -y apache-maven
$ mvn -v
Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-10T16:41:47+00:00)
Maven home: /usr/share/apache-maven
Java version: 1.7.0_151, vendor: Oracle Corporation
Java home: /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.151.x86_64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.9.38-16.35.amzn1.x86_64", arch: "amd64", family: "unix"
------------------
<참고자료>
리눅스 버전 확인
AMI에 JDK 1.8 설치
http://blog.naver.com/PostView.nhn?blogId=typez&logNo=221020775376&redirect=Dlog&widgetTypeCall=true
스칼라 및 스파크 설치
http://www.w3ii.com/ko/apache_spark/apache_spark_installation.html
카프카 설치
https://blog.knoldus.com/2017/04/19/installing-and-running-kafka-on-aws-instance-centos/
몽고디비 설치
레디스 설치
웹 프론트 개발 환경 구축
Node.js 최신 버전 설치
NPM 최신 버전 설치
https://askubuntu.com/questions/562417/how-do-you-update-npm-to-the-latest-version
$ npm -v
2.15.1
$ sudo npm update -g npm
/usr/local/bin/npm -> /usr/local/lib/node_modules/npm/bin/npm-cli.js
npm@3.10.9 /usr/local/lib/node_modules/npm
$ npm -v
3.10.9Maven 설치
http://bhargavamin.com/how-to-do/install-jenkins-on-amazon-linux-aws/
sudo yum install -y git java-1.8.0-openjdk-devel aws-cli
sudo alternatives --config java
sudo wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
sudo sed -i s/\$releasever/6/g /etc/yum.repos.d/epel-apache-maven.repo
sudo yum install -y apache-maven
mvn –v
AWS EC2 t2.micro Swap 할당하는 방법
$ dd if=/dev/zero of=/swapfile bs=1M count=1024 $ mkswap /swapfile $ swapon /swapfile $ echo "/swapfile swap swap defaults 0 0" >> /etc/fstab
출처: http://nashorn.tistory.com/623 [나숑의 법칙]
| VirtualEnv Wrapper를 이용한 파이썬 가상환경 설정 (0) | 2017.04.05 |
|---|---|
| centos fdisk (0) | 2017.03.30 |
| ubuntu 방화벽 (0) | 2016.03.14 |
| zabbix mail setting (0) | 2016.03.03 |
| swap (0) | 2016.03.02 |
고가용성(HA) : 서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질로
고(高)가용성이란 "가용성이 높다"는 뜻으로서, "절대 고장 나지 않음"을 의미한다.
고가용성은 흔히 가용한 시간의 비율을 99%, 99.9% 등과 같은 퍼센티지로 표현하는데, 1년에 계획 된 것 제외 5분 15초 이하의 장애시간을 허용한다는 의미의 파이브 나인스(5 nines), 즉 99.999%는 매우 높은 수준으로 고품질의 데이터센터에서 목표로 한다고 알려져 있다.
하나의 정보 시스템에 고가용성이 요구된다면, 그 시스템의 모든 부품과 구성 요소들은 미리 잘 설계되어야 하며, 실제로 사용되기 전에 완전하게 시험되어야 한다.
고가용성 솔루션(HACMP)을 이용하면, 각 시스템 간에 공유 디스크를 중심으로 집단화하여 클러스터로 엮어지게 만들 수 있다. 동시에 다수의 시스템을 클러스터로 연결할 수 있지만 주로 2개의 서버를 연결하는 방식을 많이 사용한다. 만약 클러스터로 묶인 2개의 서버 중 1대의 서버에서 장애가 발생할 경우, 다른 서버가 즉시 그 업무를 대신 수행하므로, 시스템 장애를 불과 몇 초만에 복구할 수 있다.
위와 같은 목적을 가지고 MySQL에서도 HA구성을 하게 되는데, 대표적으로 MHA(MasterHA)와 MySQL Fabric, MtoM이 있다.
제가 MySQL을 HA로 구성한 방법은 MHA이다.
MySQL Fabric보다 나아서라기보다는 기존의 MySQL 장비에 추가적인 작업 없이 HA를 구성할 수 있었으면 하고
MtoM은 IP에 대한 부분이 IP스위치가 어렵고 MHA는 자동으로 IP가 변경할 수 있기에 MHA로 구성을 해 보았다.
구성은 IP도 할당해야하고 대수도 여러대 필요하기 때문에 AWS에서 테스트를 해보았다.
호스트명 | IP |
bastion_server | 172.31.2.124 |
mha_manager | 172.31.13.97 |
my_master | 172.31.9.88, 172.31.0.79 |
my_slave1 | 172.31.6.249 |
my_slave2 | 172.31.4.175 |
bastion_server는 AWS로 들어가는 진입통로이다. 나는 AWS를 접근할 때 처음 통로를 Bastion_server로 놓고 해당 서버에만
EIP를 주어 접속할 수 있게 해놓았다. 그리고 bastion_server에 pem파일을 올려 모든 서버는 bastion_server를 통해
접근하도록 설정되어 있다.
mha_manager는 모든 my_master의 장애를 모니터링하고 장애시 my_slave2가 master로써 승격되고 my_slave1은 기존 my_master에서 my_slave2에 동기화된다. (bastion_server는 굳이 구성할 때 없어도 되는 서버이다.)
1. 기본 모듈 설치
[manager/master/slave1/slave2]
MHA는 Perl 모듈로 동작하기 때문에 펄 관련 모듈 설치
yum install -y perl-DBD-MySQL yum install -y perl-Config-Tiny yum install -y perl-Params-Validate yum install -y perl-Parallel-ForkManager yum install -y perl-Log-Dispatch yum install -y perl-Time-HiRes yum install -y perl-ExtUtils-MakeMaker yum install -y perl-CPAN
#perl -MCPAN -e "install Config::Tiny" #perl -MCPAN -e "install Log::Dispatch" #perl -MCPAN -e "install Parallel::ForkManager" |
2. MHA 노드 설치
[manager/master/slave/slave2]
https://code.google.com/p/mysql-master-ha/wiki/Downloads?tm=2/
mha4mysql-node-0.56.tar.gz download
mha4mysql-manager-0.56.tar.gz download
bastion_server 접속
sftp -o IdentityFile=/key_pair/XXXX.pem ec2-user@172.31.9.88 put mha4mysql-node-0.56.tar.gz
sftp -o IdentityFile=/key_pair/XXXX.pem ec2-user@172.31.6.249 put mha4mysql-node-0.56.tar.gz
sftp -o IdentityFile=/key_pair/XXXX.pem ec2-user@172.31.4.175 put mha4mysql-node-0.56.tar.gz
sftp -o IdentityFile=/key_pair/XXXX.pem ec2-user@172.31.13.97 put mha4mysql-node-0.56.tar.gz put mha4mysql-manager-0.56.tar.gz
tar xvzf mha4mysql-node-0.56.tar.gz cd mha4mysql-node-0.56 perl Makefile.PL make make install |
3. MHA 매니저 설치
[manager]
mha_manager서버에 mha4mysql-manager 파일 설치
mkdir /data/mha_manager cd /data/mha_manager tar xvzf mha4mysql-manager-0.56.tar.gz cd mha4mysql-manager-0.56 perl Makefile.PL
make
make install |
4. SSH 설정
[manager/master/slave1/slave2]
모든 IP에 서로 SSH 접근이 가능하도록 추가해준다.
(AWS에서는 security_group에 22번 포트를 열어줌으로써 아래와 같은 작업이 불필요하다.)
vi /etc/hosts.allow
# for MHA sshd: 172.31.2.124,172.31.1.164,172.31.4.134,172.31.4.134,172.31.0.79 |
[master/slave1/slave2]
MHA구성으로 사용한 시스템계정 생성
useradd -g mysql -d /home/mhauser -m -s /bin/bash mhauser cat /etc/passwd | grep mhauser
passwd mhauser 패스워드 설정 |
[manager]
mha_manager 서버에도 시스템계정 생성
groupadd mysql useradd -r -g mysql mysql useradd -g mysql -d /home/mhauser -m -s /bin/bash mhauser cat /etc/passwd | grep mhauser
passwd mhauser |
[manager/master/slave1/slave2]
mhauser에 대한 SSH key파일 설정
su - mhauser ssh-keygen
cat /home/mhauser/.ssh/id_rsa.pub
manager, master, slave1, slave2 서버의 id_rsa.pub 파일을 각각 복사해 서버의 authorized_keys 파일에 붙여 넣는다.
cat /root/.ssh/authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC+… mhauser@mha_manager ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDWqz+… mhauser@my_master ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCaeQE+… mhauser@my_slave1 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCg6QU… mhauser@my_slave2
|
[manager/master/slave/slave2]
해당 서버에 SSH 접속을 원활하게 하기 위해 /etc/hosts파일에 아래와 같이 내용을 추가한다.
그리고 .ssh 디렉토리 내의 파일에 대한 모든 권한을 변경한다.
(root계정으로 실행)
vi /etc/hosts
cd .ssh/ chmod 600 * |
접속테스트(mhauser로 접속한 상태에서 테스트)
각 서버마다 접속해서 아래와 같이 전부 접속 테스트를 해준다.
ssh 172.31.2.124 hostname ssh 172.31.13.97 hostname ssh 172.31.9.88 hostname ssh 172.31.0.79 hostname ssh 172.31.6.249 hostname ssh 172.31.4.175 hostname |
아래와 같은 메시지가 나오면 yes를 누른다.
다음에 실행 시, 해당 IP 호스트명만 출력된다.
[mhauser@my_slave2 .ssh]$ ssh 172.31.4.175 hostname The authenticity of host '172.31.4.175 (172.31.4.175)' can't be established. ECDSA key fingerprint is 49:c7:ae:1c:90:1a:b1:a1:d1. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '172.31.4.175' (ECDSA) to the list of known hosts. my_slave2 [mhauser@my_slave2 .ssh]$ ssh 172.31.4.175 hostname my_slave2 |
[master/slave1/slave2]
sudo 권한에 변경작업을 해준다.
root계정 접속
visudo
|
[master]
my_master 서버에 서비스로 쓰이는 IP 하나를 할당해준다.
vip 할당 ifconfig eth0:0 172.31.0.79 netmask 255.255.0.0 broadcast 172.31.0.255 up |
5. DB접속 계정 생성
[master/slave1/slave2]
MHA 매니저 서버(배스천)에서는 모든 DB서버의 MySQL에 접속할 수 있어야 한다.
/mysql/bin/mysql -uroot -p grant all on *.* to mhauser@'172.31.2.124' identified by 'XXXXXXXX'; grant all on *.* to mhauser@'172.31.13.97' identified by 'XXXXXXXX'; grant all on *.* to mhauser@'172.31.0.79' identified by 'XXXXXXXX'; grant all on *.* to mhauser@'172.31.9.88' identified by 'XXXXXXXX'; grant all on *.* to mhauser@'172.31.6.249' identified by 'XXXXXXXX'; grant all on *.* to mhauser@'172.31.4.175' identified by 'XXXXXXXX'; |
[master/slave2]
master의 repl 계정 권한을 마스터 대체서버(slave2)에도 동일하게 적용
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'172.31.6.249' IDENTIFIED BY PASSWORD 'XXXXXXXX'; GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'172.31.4.175' IDENTIFIED BY PASSWORD 'XXXXXXXX'; flush privileges; |
6. MHA 설정
* master 대체 slave서버의 주의사항
- mysqlbinlog 버전이 5.1이상이어야 한다. master의 binlog가 row 포맷이면 mysqlbinlog 5.1부터는
분석이 가능하다. 만약 5.1보다 낮으면 동기화시 row포맷을 사용해서는 안된다.
- DB서버의 binlog에 접근할 수 있게 디렉토리 권한을 설정해야 한다.
(저는 mhauser를 mysql 그룹으로 묶어서 mysql이 접근가능한 디렉토리는 mhauser도 접근 가능하게 하였다.)
- 새로운 master가 될 slave에 binlog가 횔성화 되어 있어야 한다.(log-bin)
(저는 log-bin 뿐만 아니라 log-bin=경로/파일명 이렇게하여 마스터와 동일한 경로와 파일명이 생기도록 하였다.)
- binlog와 relay log의 필터 규칙이 모든 MySQL DB군에서 동일해야 한다.
즉, binlog에 대해 binlog-db-db나 replicate-ignore-db와 같은 필터 규칙이 정의되어 있다면 모든 MySQL은
동일하게 해줘야 한다.
- 새로운 master가 될 slave에 read_only로 읽기 전용으로만 해두는 것이 나중에 교체시 문제를 최소화 시킬 수 있다.
[manager]
MHA를 사용하기 위한 디렉토리 생성
mkdir /data/mha_log ## mha 로그파일 저장 mkdir /data/mha_app ## mha 실행시 failover 프로그램 저장 mkdir /data/mha_scripts ## mha 스크립트 저장 chown mhauser:mysql /data/mha_log chown mhauser:mysql /data/mha_app chown mhauser:mysql /data/mha_scripts |
7. MHA 매니저 서버 설정파일
* 싱글모드로 설정하여 테스트를 진행하였다.
1) 싱글모드
vi /etc/mha-manager.cnf
[server default] user=mhauser password=XXXXXXXX repl_user=repl repl_password=XXXXXXXX
## mha manager 실행파일이 생길 폴더 지정 manager_workdir=/data/mha_app ## 로그파일 지정 manager_log=/data/mha_log/mha4mysql.log
## mysql서버에 실행파일이 생길 폴더 지정 remote_workdir=/data/mha_app ## binlog 파일 폴더 지정 master_binlog_dir=/mysql/var
## mysql서버의 mysql 실행파일 폴더 지정 client_bindir=/mysql/bin ## mysql서버의 mysql 라이브러리가 저장되어 있는 폴더 지정 client_libdir=/mysql/lib ignore_fail=2
[server1] hostname = 172.31.9.88 ## my_master ip candidate_master=1
[server2] hostname = 172.31.4.175 ## replace slave2 ip candidate_master=1
[server3] hostname = 172.31.6.249 ## slave1 ip no_master=1 |
2) 다중모드
[manager]
vi /etc/mha-manager.cnf
[server default] user=mhauser password=XXXXXXXX ssh_user=mhauser
master_binlog_dir=/mysql/var remote_workdir=/data/mha_app secondary_check_script= masterha_secondary_check -s remote_host1 -s remote_host2 ping_interval=3 master_ip_failover_script=/data/mha_script/master_ip_failover shutdown_script=/data/mha_script/power_manager report_script=/data/mha_script/send_master_failover_mail |
vi /etc/my_master.cnf
[server_default] manager_workdir=/data/mha_app manager_log=/data/mha_log/mha4mysql.log
[server1] hostname = 172.31.9.88 ## my_master ip candidate_master=1
[server2] hostname = 172.31.4.175 ## replace slave2 ip candidate_master=1
[server3] hostname = 172.31.6.249 ## slave1 ip no_master=1 |
[master]
할당된 IP 설정을 확인한다.
ifconfig
|
* 비활성화
ifconfig eth0:0 172.31.0.79 netmask 255.255.0.0 broadcast 172.31.0.255 down
8. MHA모니터링 시작하기
mha 기동
cd /data/mha4mysql-manager-0.56/bin nohup masterha_manager --conf=/etc/mha-manager.cnf < /dev/null > /data/mha_log/mha4mysql.log 2>&1 & |
* 중단
/data/mha/mha4mysql-manager-0.56/bin/masterha_stop --conf=/etc/mha_manager.cnf
masterha_check_status로 masterha_manager 모니터링
./masterha_check_status --conf=/etc/mha-manager.cnf
|
ssh접속이 정상적으로 이루어지는지 확인
masterha_check_ssh --conf=/etc/mha-manager.cnf
|
리플리케이션 상태 모니터링
./masterha_check_repl --conf=/etc/mha-manager.cnf
|
* 호스트 정보 관리(IP추가)
./masterha_conf_host --command=add --conf=/etc/mha-manager.cnf --hostname=XXX.XXX.XXX.XXX
옵션 : --command=(add/delete)
[slave2]
slave2에 릴레이로그는 mysql 설치시 적용후 자동삭제하게 되어 있다.
master 대체 서버이기 때문에 릴레이로그를 purge하는 것을 중단하고 크론탭에 새벽에 자동 삭제할 수
있게 걸어 놓는다.
/mysql/bin/mysql -uroot -p set global relay_log_purge=0 릴레이로그 삭제 설정 vi /etc/crontab
|
9. 스크립트 생성
1) 스위치오버 시 vip도 자동으로 스위치 오버하는 스크립트 생성(root계정으로 실행)
cd /data/mha4mysql-manager-0.56/samples/scripts cp master_ip_online_change master_ip_online_change.org chown mhauser:mysql master_ip_online_change vi master_ip_online_change
cd /data/mha_scripts/ vi change_virtual_ip_master_to_slave.sh
vi change_virtual_ip_slave_to_master.sh
vi /etc/mha-manager.cnf
|
2) 페일오버 시 vip도 자동으로 페일오버하는 스크립트
cd /data/mha4mysql-manager-0.56/samples/scripts cp master_ip_failover /data/mha_scripts/ cd /data/mha_scripts/ chown mhauser:mysql master_ip_failover
vi master_ip_failover
vi change_virtual_ip.sh
vi /etc/mha-manager.cnf
cd /data/mha_scripts chown mhauser:mysql *
|
10. 테스트
1) 상태확인
[master]
my_master 서버는 read 전용이 아니며 아래와 같은 master 상태값을 가지고 있다.
mysql> show variables like 'read_only'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | read_only | OFF | +---------------+-------+ 1 row in set (0.01 sec)
mysql> show master status; +------------------+----------+--------------+--------------------------------------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+--------------------------------------------------+-------------------+ | mysql-bin.000004 | 120 | | mysql,test,information_schema,performance_schema | | +------------------+----------+--------------+--------------------------------------------------+-------------------+ 1 row in set (0.00 sec)
ifconfig
|
[slave1]
my_slave1은 현재 my_master(172.31.9.88)을 master로써 동기화하고 있다.
mysql> show slave status \G; Slave_IO_State: Waiting for master to send event Master_Host: 172.31.9.88 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000005 Read_Master_Log_Pos: 120 Relay_Log_File: my_slave1-relay-bin.000009 Relay_Log_Pos: 283 Relay_Master_Log_File: mysql-bin.000005 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 120 Relay_Log_Space: 623 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 88 Master_UUID: b3146e4b-d3e3-11e6-b88d-028ca261c841 Master_Info_File: /mysql/var/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 |
[slave2]
my_slave2는 my_master 대체 슬레이브로써 읽기 전용으로만 사용되고 있고 172.31.9.88(my_master)와 동기화 되어 있다.
mysql> show variables like 'read_only'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | read_only | ON | +---------------+-------+ 1 row in set (0.00 sec)
mysql> show slave status \G; Slave_IO_State: Waiting for master to send event Master_Host: 172.31.9.88 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000004 Read_Master_Log_Pos: 120 Relay_Log_File: my_slave2-relay-bin.000006 Relay_Log_Pos: 236 Relay_Master_Log_File: mysql-bin.000004 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 120 Relay_Log_Space: 576 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 88 Master_UUID: b3146e4b-d3e3-11e6-b88d-028ca261c841 Master_Info_File: /mysql/var/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 |
[manager]
mha_manager 기동하여 위의 모든 서버들을 모니터링하게 한다.
su - mhauser cd /data/mha4mysql-manager-0.56/bin/ nohup masterha_manager --conf=/etc/mha-manager.cnf < /dev/null > /data/mha_log/mha4mysql.log 2>&1 & |
[master]
my_master서버에서 mysql를 kill하여 장애를 발생시킨다.
mysql kill ps -ef | grep mysql kill -9 22009 22921 |
위와 같이 할 경우, mha_manager서버의 /data/mha_log/mha4mysql.log파일에 마스터와 슬레이브가
스위칭 되는 로그가 남는다.
마지막에 failover report까지 나오면 스위칭이 완료된다.
ifconfig
eth0 Link encap:Ethernet HWaddr 02:8C:A2:61:C8:41 inet addr:172.31.9.88 Bcast:172.31.15.255 Mask:255.255.240.0 inet6 addr: fe80::8c:a2ff:fe61:c841/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1 RX packets:116549 errors:0 dropped:0 overruns:0 frame:0 TX packets:85789 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:113678944 (108.4 MiB) TX bytes:12379793 (11.8 MiB)
lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:138 errors:0 dropped:0 overruns:0 frame:0 TX packets:138 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1 RX bytes:27398 (26.7 KiB) TX bytes:27398 (26.7 KiB) |
[slave2]
마스터에 있던 IP정보가 my_slave2 서버에 옮겨진 것을 확인할 수 있다.
ifconfig
|
[slave1]
slave 상태를 확인하면 my_slave1 서버가 동기화하는 master IP가 변경된 것을 확인할 수 있다.
show slave status \G;
|
[manager/master/slave/slave2]
mha_manager은 이렇게 IP와 동기화 되는 부분을 자동으로 변경하고 중지된다.
/data/mha_app를 삭제하지 않으면 mha_manager 기동 시 에러가 발생한다.
rm -f /data/mha_app/*
* MHA 구성시 에러사항 정리
Mon Jan 9 04:24:20 2017 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln177] Got Error on finalize_on_error at monitor: Permission denied:/data/mha_app/mha-manager.master_status.health at /usr/local/share/perl5/MHA/MasterMonitor.pm line 633. |
chown mhauser.mysql mha_app
chown mhauser.mysql mha_scripts
Mon Jan 9 04:29:26 2017 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln122] Got error when getting node version. Error: Mon Jan 9 04:29:26 2017 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln123] |
mysql에 mha4node가 설치되어 있지 않았다.
Mon Jan 9 05:28:53 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln158] Binlog setting check failed! Mon Jan 9 05:28:53 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln405] Master configuration failed. Mon Jan 9 05:28:53 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln424] Error happened on checking configurations. at /u sr/local/bin/masterha_manager line 50. Mon Jan 9 05:28:53 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln523] Error happened on monitoring servers. Mon Jan 9 05:28:53 2017 - [info] Got exit code 1 (Not master dead). |
mkdir /data/mha_app
chown mhauser.mysql /data/mha_app
| MS-SQL 에서 연결된 서버 (Linked Server )에 MY-SQL DataBase 서버 등록하기 (0) | 2016.07.14 |
|---|---|
| [Centos] ssh 원격 접속 장애 (WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!) (0) | 2015.12.22 |
| mssql 에서 mysql linked Server 사용하기 (0) | 2015.12.08 |
| Couldn't find MySQL server (0) | 2015.11.12 |
| 형변환 에러시 (0) | 2015.09.04 |
2016년 9월 12일 오후 7시 45분, 8시 35분 2차례 강력한 지진이 연달아 발생했습니다.
1차 지진의 규모는 5.1, 2차 지진의 규모는 5.8이라고 하는데, 서울에 사는 저도 진동을 꽤 느꼈는데 지진 진앙지 근처인 경주 지방에는 많은 사람들이 엄청나게 놀랐을 것 같습니다.
규모 5.8은 기상청에서 관측한 한반도 지진중 가장 강력하다고 알려져 있습니다. 아마 이 지진은 앞으로 경주 지진으로 불리며 회자 될듯 합니다.
아래 그림은 미국 지질 조사국(USGS)의 실시간 데이터를 받아서 지도에 그린 것입니다.
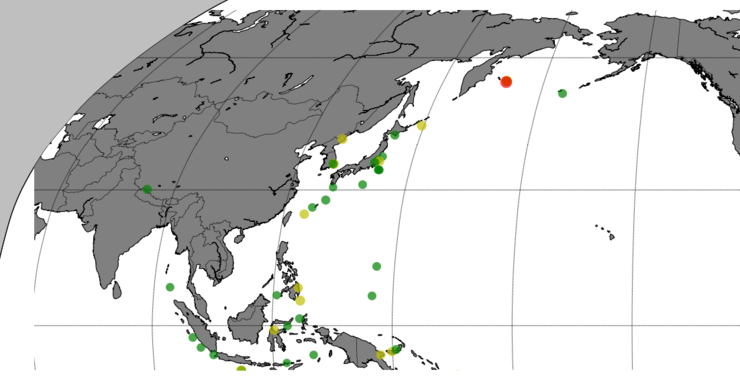
해당 지역은 양산 단층이 지나가는 곳인데, 이 곳은 예전부터 이 단층이 활단층이냐 아니냐 논란이 있었는데요,, 활단층일 가능성이 많은 것 같습니다. 만약 활성 단층이라면 이 부근에 있는 원전이 참으로 문제가 아닐 수 없네요..
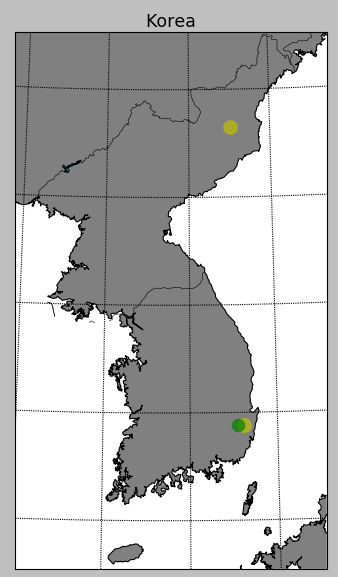
아무쪼록 무탈했으면 좋겠습니다.
여기서 지진에 대한 기초 상식에 대해 가볍게 살펴보도록 하겠습니다.
지진의 크기는 보통 모멘트 규모(Moment Magnitude Scale)라고 불리는 지진으로 인해 발생되는 에너지의 크기로 나타내는 단위로 표시합니다. 모멘트 규모는 그냥 규모라고 부르기도 합니다.
규모는 1에서 시작하는데, 규모의 크기가 1 증가할 때마다 에너지의 크기는 약 32배가 커집니다. 만약 규모가 2차이가 나면 에너지 크기는 약 1000배가 됩니다. 따라서 규모 6 지진은 규모4 지진의 1000배나 되는 에너지를 분출합니다.
이해를 돕기 위해 예를 들어보자면, 규모 8의 지진은 이번 경주 지진의 크기인 규모 6 정도의 지진이 1000번 일어나야 해소되는 에너지를 가지고 있습니다.
규모가 지진의 실제적인 에너지의 크기라면 진도는 발생한 지진으로 인해 사람이 직접적으로 느끼고 땅이 흔들리는 정도를 의미합니다. 따라서 진도 등급이 피해 정도와 직결되는 단위라고 생각하면 됩니다. 미국, 일본, 우리나라에서 사용되는 진도는 수정 메르칼리 진도 등급(Modified Mercalli Intensity Scale)입니다. 수정 메르칼리 진도 등급은 아래의 표와 같이 총 12 등급으로 되어 있습니다.
이번에 서울에서 느낀 진도는 4정도가 되는거 같네요..
진도 | 상황 |
1 | 미세한 진동. 특수한 조건에서 극히 소수 느낌 |
2 | 실내에서 극히 소수 느낌 |
3 | 실내에서 소수 느낌. 매달린 물체가 약하게 움직임 |
4 | 실내에서 다수 느낌. 실외에서는 감지하지 못함. |
5 | 건물 전체가 흔들림. 물체의 파손, 뒤집힘, 추락. 가벼운 물체의 위치 이동 |
6 | 똑바로 걷기 어려움. 약한 건물의 회벽이 떨어지거나 금이 감. 무거운 물체의 이동 또는 뒤집힘 |
7 | 서 있기 곤란함. 운전 중에도 지진을 느낌. 회벽이 무너지고 느슨한 적재물과 담장이 무너짐 |
8 | 차량운전 곤란. 일부 건물 붕괴. 사면이나 지표의 균열. 탑·굴뚝 붕괴 |
9 | 견고한 건물의 피해가 심하거나 붕괴. 지표의 균열이 발생하고 지하 파이프관 파손 |
10 | 대다수 견고한 건물과 구조물 파괴. 지표균열, 대규모 사태, 아스팔트 균열 |
11 | 철로가 심하게 휨. 구조물 거의 파괴. 지하 파이프관 작동 불가능 |
12 | 지면이 파도 형태로 움직임. 물체가 공중으로 튀어오름 |
|
[출처] 경주 지진: 한반도 지진 관측 사상 최대 지진|작성자 옥수별 |
| 한반도에 지진 발생 (0) | 2017.12.14 |
|---|---|
| 지진 지역 지도에 표시하기3 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기2 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
2016년 9월 9일 한반도 북부 북한 지역에 지진이 발생했다고 표시되어 있네요. 뉴스를 보니까 북한에서 핵실험을 한걸로 판명되었군요.
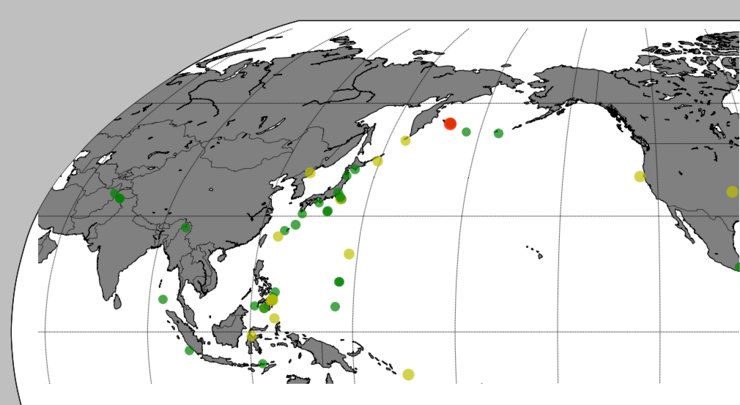
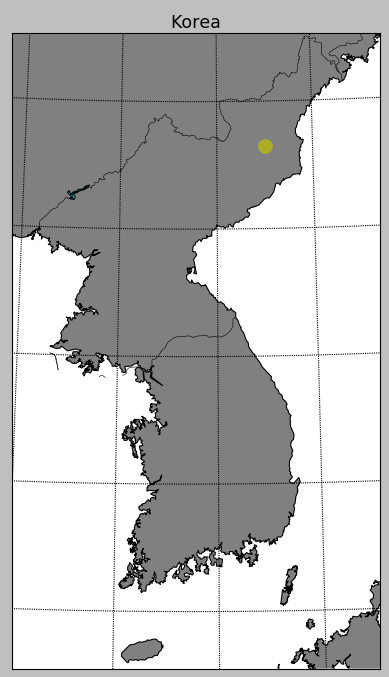
참,, 걱정이 이만저만 아닙니다. 국민 모두 일치단결하여 이 난국을 극복해야 할 것 같습니다.
[출처] 한반도에 지진 발생|작성자 옥수별
| 경주 지진: 한반도 지진 관측 사상 최대 지진 (0) | 2017.12.14 |
|---|---|
| 지진 지역 지도에 표시하기3 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기2 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
지진 지역 지도에 표시하기3 - 발생한 지진 규모에 따라 다르게 표시하기
지진 지역 지도에 표시하기2에서는 USGS에서 제공하는 전세계에서 현재 기준 1주일간 발생한 규모 4.5이상의 지진을 발생한 위치에 빨간색 점으로 표시해봤습니다.
이제 이를 좀 더 응용하여 발생한 지진 규모에 따라 아래의 규칙으로 다른 크기의 원과 색상으로 표시를 해보도록 하겠습니다.
원의 크기는 발생한 지진 규모에 비례하게 만들겠습니다. 2편의 코드를 좀 수정하여 아래와 같이 구현합니다.

주요 변경 부분만 살펴보겠습니다.
>>> mags.append(float(ret[4]))
발생한 지진 규모를 리스트인 mags에 추가합니다.
>>> get MarkerColor(mag)
지진 규모에 따라 표시할 색상과 마커모양(원)을 리턴합니다.
>>> m.plot(x, y, color, markersize=2.5*mag, alpha=0.7)
지진 규모에 따른 색상과 원 크기를 지정하고 투명도 0.7로 지도에 그려줍니다.
코드를 실행하면 아래와 같은 결과가 나옵니다.
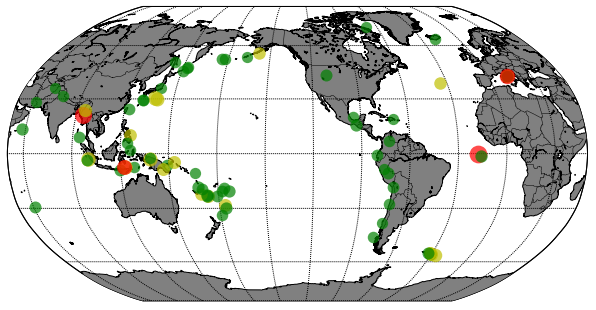
지도를 확대해보면 아래와 같습니다.
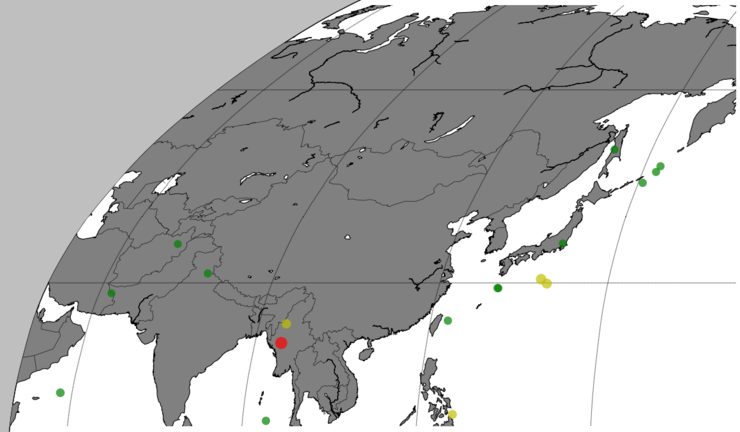
좀 더 응용을 해서 이탈리아 부분만을 중점적으로 지도에 표시하고 지진 지역을 나타내 보도록 하겠습니다.

변경된 부분은 다음과 같습니다.
>>> m = Basemap(llcrnrlon=6.0,llcrnrlat=36.00,urcrnrlon=21.0,urcrnrlat=48.0,
resolution='i',projection='cass',lon_0=18.0,lat_0=42.0)
인자는 다음과 같은 의미를 지닙니다.
이 코드를 실행하면 아래와 같은 결과가 나옵니다.
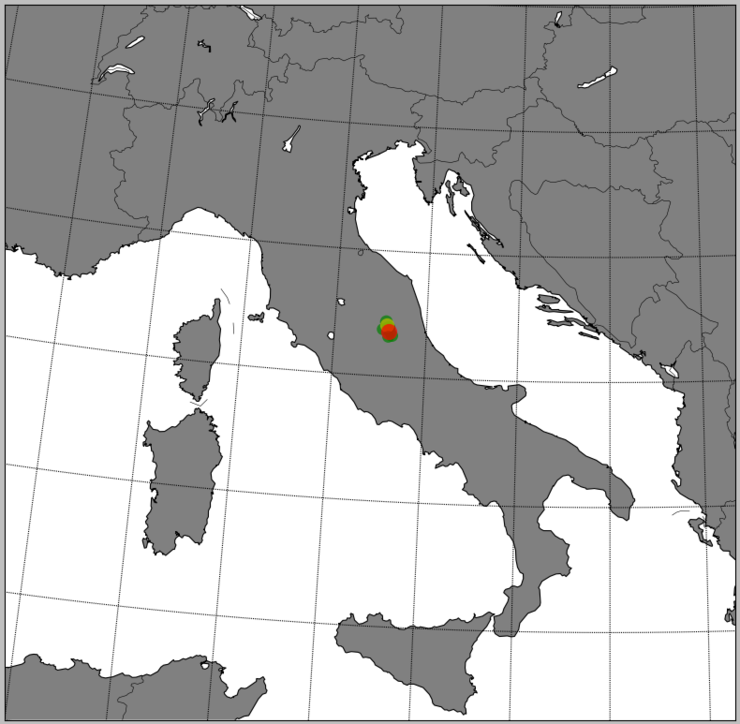
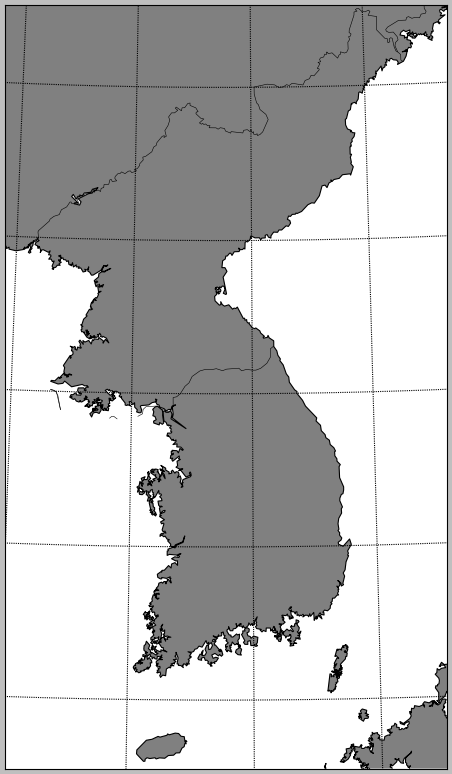
참고로 우리나라만 살펴보면 지진이 없는 깨끗한 땅임을 알 수 있습니다.
이상으로 지진 지역을 지도에 표시하는 포스팅은 마무리 하도록 하겠습니다.
[출처] 지진 지역 지도에 표시하기3|작성자 옥수별
| 경주 지진: 한반도 지진 관측 사상 최대 지진 (0) | 2017.12.14 |
|---|---|
| 한반도에 지진 발생 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기2 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
지진 지역 지도에 표시하기2 - 지진 데이터를 인터넷에서 가져와 지도에 표시하기
이제 인터넷에 공개된 지진 데이터를 가져와 우리의 지도에 표시를 해보도록 하겠습니다.
미국 지질조사국 USGS는 다양한 지진 데이터를 제공하고 있는데, 이 포스팅에서 사용할 데이터는 프로그램을 구동하는 시간 기준으로 1주일간 전 세계적으로 발생한 규모 4.5 이상 지진입니다.
URL은 다음과 같습니다.
http://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/4.5_week.csv
아래의 코드로 이 데이터가 어떤 형태로 되어 있는지 확인해봅니다.

위 코드에서 주석 처리한 부분은 나중에 실제로 사용할 코드입니다. 코드를 실행하면 다음과 같은 내용이 화면에 출력됩니다.
time,latitude,longitude,depth,mag,magType,nst,gap,dmin,rms,net,id,updated,place,type,horizontalError,depthError,magError,magNst,status,locationSource,magSource 2016-08-27T08:59:13.780Z,-29.0991,60.9897,10,4.8,mb,,51,9.213,0.51,us,us20006ui0,2016-08-27T09:17:32.040Z,"Southwest Indian Ridge",earthquake,9.6,1.9,0.09,38,reviewed,us,us 2016-08-27T08:24:09.990Z,53.1043,-166.7081,39.28,4.5,mb,,167,0.752,1.04,us,us20006uhu,2016-08-27T08:53:36.040Z,"86km S of Unalaska, Alaska",earthquake,8.1,6.8,0.076,51,reviewed,us,us 2016-08-27T04:51:06.190Z,-56.2823,-26.9039,66.12,5.4,mb,,83,5.831,0.83,us,us20006ugf,2016-08-27T05:09:29.040Z,"49km NNE of Visokoi Island, South Georgia and the South Sandwich Islands",earthquake,7.9,6.8,0.053,122,reviewed,us,us 2016-08-27T02:34:41.440Z,13.4315,57.8638,10,4.9,mb,,49,11.56,1.19,us,us20006ufv,2016-08-27T02:53:11.040Z,"Owen Fracture Zone region",earthquake,9.8,1.9,0.053,114,reviewed,us,us 2016-08-27T01:14:33.850Z,31.5284,77.7042,31.67,4.6,mb,,153,4.3,0.78,us,us20006ufk,2016-08-27T09:07:01.643Z,"9km W of Sarahan, India",earthquake,9.2,6.2,0.088,38,reviewed,us,us ... ... |
출력된 내용에서 첫번째 줄을 보면 어떤 데이터가 있는지 알 수 있습니다. 모든 데이터는 콤마로 구분되어 있고 주요 내용은 다음과 같습니다.
나머지 부분은 이 포스팅에서는 사용하지 않을 내용이므로 패스하고, 이 포스팅에서 사용할 데이터는 3번째, 4번째, 5번째 데이터입니다.
이제 코드를 구현해보도록 합니다. 지진 지역 지도에 표시하기1의 'robin' 지도를 나타내는 코드에서 style.use('seaborn-talk') 다음 줄에 아래의 코드를 추가합니다.

그리고, plt.show() 앞 부분에 아래의 코드를 추가합니다.

이제 코드를 실행해보면 아래 그림과 같이 세계 지도에 최근 1주일간 전세계에서 발생한 규모 4.5 이상 지진 발생 위치를 빨간색 점으로 표시됩니다.
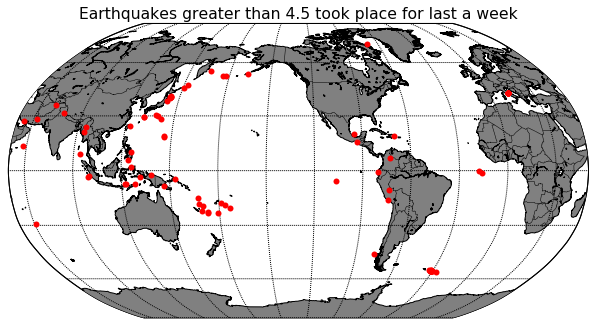
위 결과를 보면 아직도 구조 활동을 하고 있는 이탈리아 지진이 표시되어 있음을 알 수 있습니다. 윈도우에서 이 코드를 실행하고 있으면 Matplotlib 출력 화면에 있는 아이콘을 이용해 지도를 축소하고 확대할 수 있습니다. 아래 그림은 이탈리아 지진 지역을 자세히 보기 위해 지도를 확대한 것입니다.
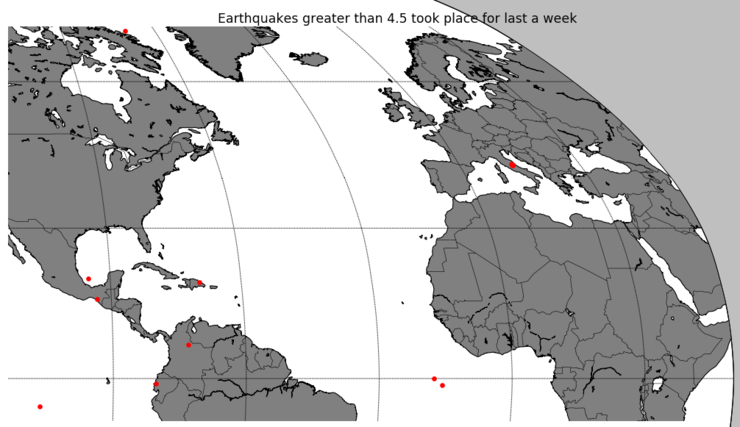
이번 포스팅에서는 현재 기준으로 과거 1주일간 전세계에서 발생한 지진 지역을 빨간색 점으로 표시하는 방법을 다루었습니다. 다음 포스팅에서는 발생한 지진 규모에 따라 색상과 점의 크기를 다르게 표현하는 방법을 다루겠습니다.
[출처] 지진 지역 지도에 표시하기2|작성자 옥수별
| 한반도에 지진 발생 (0) | 2017.12.14 |
|---|---|
| 지진 지역 지도에 표시하기3 (0) | 2017.12.14 |
| 지진 지역 지도에 표시하기1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍19 - 3D 플로팅3 (0) | 2017.12.14 |
지진 지역 지도에 표시하기1 - Basemap 설치하기
요즘 지진이 전세계적으로 자주 일어나고 있습니다. 제가 원래 지구물리학을 전공해서 지진에 대해서는 조금 아는 편입니다. 지진은 지구의 맨틀위에 둥둥 떠다니는 판이라 불리는 지각판들의 경계부분에서 대부분 일어나지만, 판경계가 아닌 판내부에서도 일어납니다. 일본은 판경계에 위치한 섬이라서 하루에도 몇번씩 지진이 발생하는 나라죠.
지진의 세기는 규모와 진도라는 용어를 사용하는데, 규모는 실제 지진 에너지의 크기이고, 진도는 땅이 흔들리는 정도를 의미합니다. 지진 규모는 5이지만 발생한 곳의 지질에 따라 진도가 작을 수도 있고 클 수도 있습니다. 따라서 실제 피해와 직결되는 것은 규모보다는 진도가 더 맞다고 볼 수 있습니다.
지진 이야기는 이쯤에서 마무리하고, 이번에 해볼 것은 전세계에서 지진이 일어나는 곳을 세계 지도에 표시해보는 것입니다. 지진 데이터는 미국 USGS(US Geological Survey)에서 제공하는 자료를 이용할 예정입니다.
일단 지진 지역을 세계 지도에 표시하려면 지도를 화면에 그려야겠지요. 이를 위해 다음과 같은 일들을 먼저 해야 합니다.
Matplotlib은 이미 설치되었으리라 생각하고, Basemap을 설치하는 방법에 대해 살펴보겠습니다.
Basemap은 GEOS에 기반하여 2D 데이터를 지도에 플로팅할 수 있는 Matplotlib 툴킷입니다. Basemap의 설치는 윈도우 환경과 리눅스 환경에서 각각 다른 방법으로 수행해야 합니다. 윈도우에 Basemap을 설치하려면 Basemap 라이브러리를 다운로드 받아 PIP를 이용해 간단하게 설치할 수 있지만 리눅스의 경우, 리눅스에 OpenCV를 설치하는 것처럼 관련 소스를 다운로드 받고 make 파일을 만들고 빌드를 해야합니다. 저 같은 경우는 리눅스 기반의 Jupyter에서 개발을 하기 때문에 리눅스에 Basemap을 설치해서 사용하지만 이 포스팅에서는 윈도우에 설치하는 것으로 설명하도록 하겠습니다.
아래 링크에서 파이썬3.5용 Basemap 라이브러리인 Basemap1.0.8-cp35-none-win32.whl을 다운로드 받습니다.
☞ Basemap for Python 3.5 다운로드 받기
PIP를 이용해 다운로드 받은 파일을 설치합니다. 설치가 종료되면 윈도 커맨드창을 열고 파이썬을 실행한 후 아래와 같이 Basemap 을 import 해봅니다.
>>> from mpl_toolkits.basemap import Basemap
아무런 오류없이 import가 제대로 되면 준비가 끝났습니다. 자 이제 기본적인 지도를 화면에 그려보겠습니다.

윈도우 환경에서는 위 코드의 맨 윗줄은 삭제해야 합니다.
이 코드는 기본적인 세계 지도에 나라 경계만 구분하여 화면에 출력합니다.
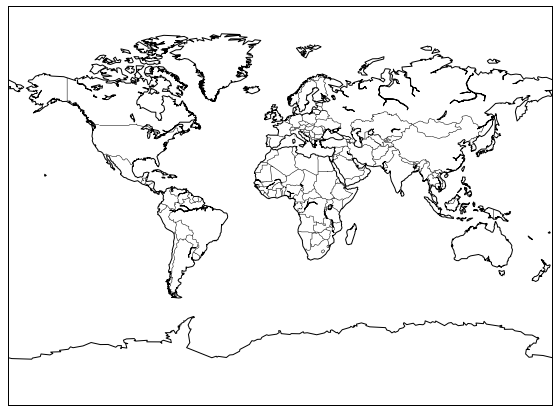
그러면 위 코드를 조금 수정하여 지도 모양을 바꾸어 보겠습니다.

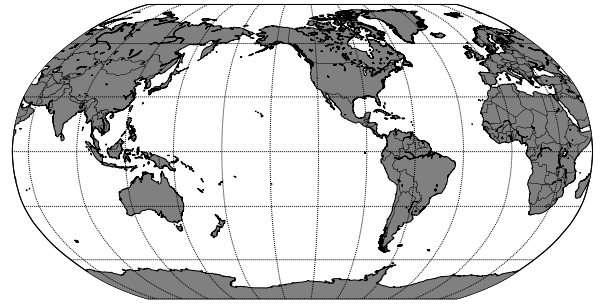
이 코드는 지도 형태를 'robin'으로 변경했고, lat_0=0, lon_0=130은 지도의 중심을 동경 130도로 설정한다는 의미입니다.
>>> m.fillcontinents(color='gray')
지도에서 대륙부분을 회색으로 채웁니다.
>>> m.drawmeridians(np.arange(0, 360, 30))
>>> m.drawparallels(np.arange(-90, 90, 30))
위도선과 경도선을 30도 간격으로 그려줍니다.
이 코드를 실행하면 다음과 같은 지도가 화면에 나타납니다.
다음 포스팅에서는 지진 데이터를 인터넷에서 받아와 이 지도 위에 표시하는 방법을 다루도록 하겠습니다.
[출처] 지진 지역 지도에 표시하기1|작성자 옥수별
| 지진 지역 지도에 표시하기3 (0) | 2017.12.14 |
|---|---|
| 지진 지역 지도에 표시하기2 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍19 - 3D 플로팅3 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍18 - 3D 플로팅2 (0) | 2017.12.14 |
파이썬 Matplotlib을 이용한 데이터 시각화 프로그래밍20 - 3D 플로팅4
이번 포스팅은 데이터 가시화 프로그래밍 마지막편으로 아래와 같은 3D 플로팅에 대해 살펴보고 마무리하겠습니다.
3D 다각형 그래프 그리기

3D 막대그래프 그리기

3D Quiver

3D 평면에 2D 그래프 그리기

3D 평면에 텍스트 삽입하기

3D 평면에서 서브플롯 구성하기

이상으로 Matplotlib을 이용해 데이터 시각화하는 방법에 대해 가볍게 살펴보았습니다.
실제 Matplotlib의 다양한 기능들은 이번 포스팅에서 다룬 것보다 훨씬 방대하고 다양한 기능들을 제공하므로 관심 있는 분들은 관련 서적을 참고하는 등으로 심화 학습을 하시면 되겠네요.
[출처] 데이터 시각화 프로그래밍20 - 3D플로팅4|작성자 옥수별
| 지진 지역 지도에 표시하기2 (0) | 2017.12.14 |
|---|---|
| 지진 지역 지도에 표시하기1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍19 - 3D 플로팅3 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍18 - 3D 플로팅2 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍17 - 3D 플로팅1 (0) | 2017.12.14 |
파이썬 Matplotlib을 이용한 데이터 시각화 프로그래밍19 - 3D 플로팅3
이번에는 3차원 좌표에서 그려진 surface에서 같은 값들을 연결한 등가선(Contour)을 표현하는 방법에 대해 알아보겠습니다. Contour에는 같은 높이를 이어서 만든 등고선, 같은 압력을 이어서 만든 등압선, 같은 온도를 이어서 만든 등온선 등 다양한 종류가 있습니다.
Matplotlib은 다양한 형태로 Contour를 아래와 같은 다양한 방법으로 그려주는 기능을 제공합니다.
자 그러면 실제 코드를 보고, 이해를 해보시면 됩니다. 아래 제시된 코드는 모두 Matplotlib 예제에서 가져온 것입니다.
Contour 플로팅
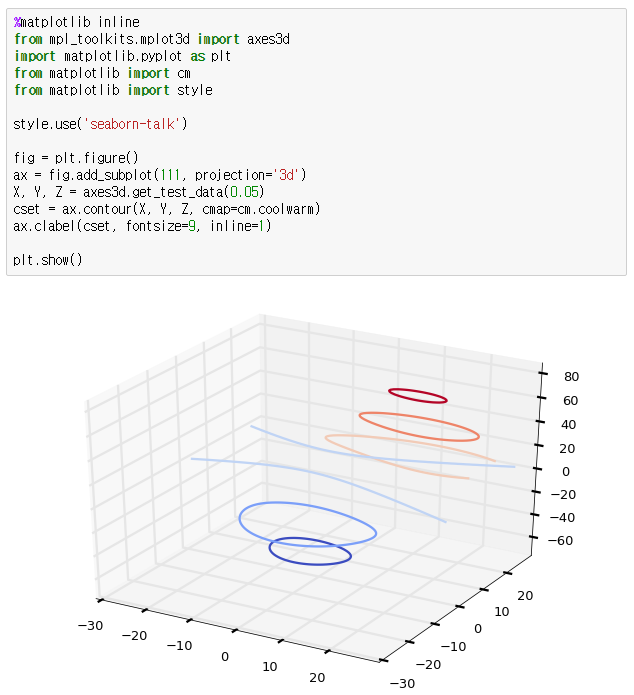
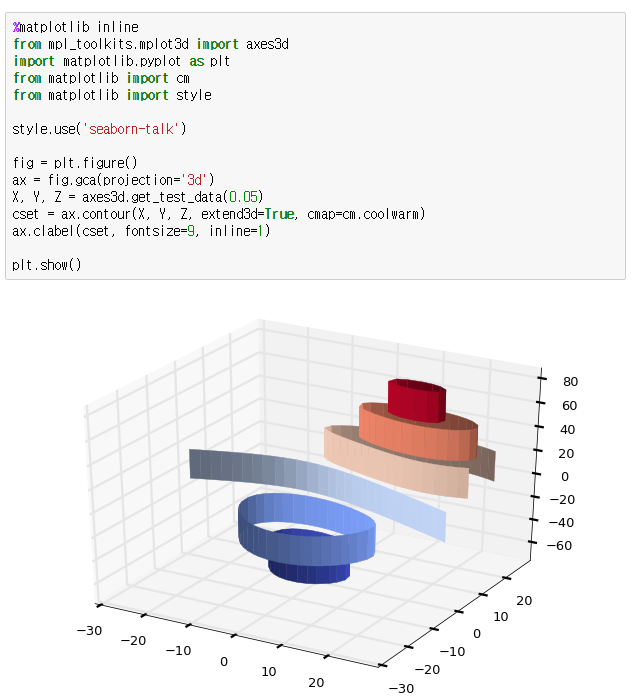

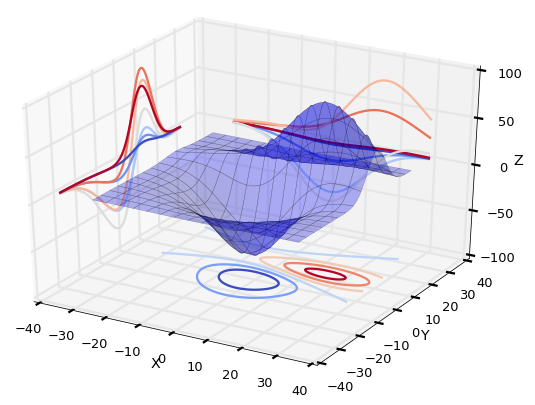
Filled Contour 플로팅
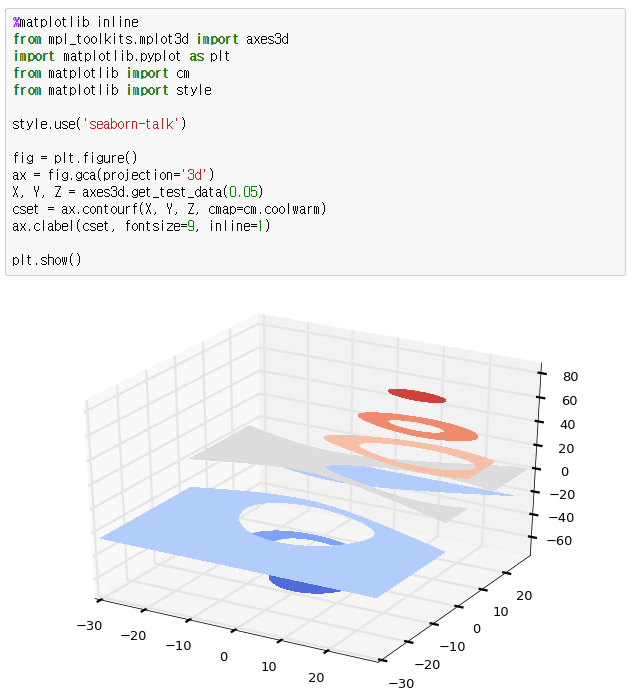

[출처] 데이터 시각화 프로그래밍19 - 3D 플로팅3|작성자 옥수별
| 지진 지역 지도에 표시하기1 (0) | 2017.12.14 |
|---|---|
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍18 - 3D 플로팅2 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍17 - 3D 플로팅1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍16 - Matplotlib 애니메이션 (0) | 2017.12.14 |
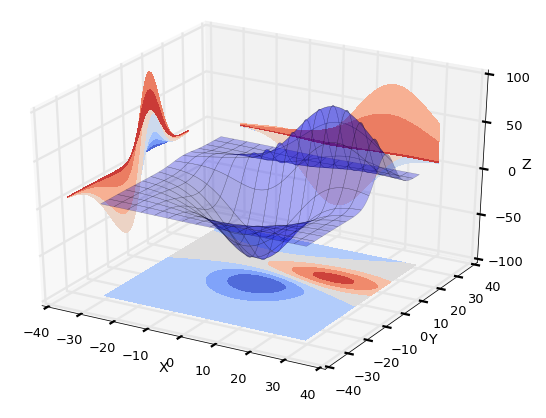
파이썬 Matplotlib을 이용한 데이터 시각화 프로그래밍18 - 3D 플로팅2
Matplotlib을 이용한 3D 플로팅 예는 대부분 알려진 복잡한 수학식을 이용한 것입니다. 실제 데이터를 3D 플로팅으로 분석하는 경우 이런 복잡한 수학식이 아니라 데이터를 어떻게 표현하고 나타낼지에 관한 아이디어가 중요한 것이 되겠죠.
이번 포스팅에서는 아래와 같은 것들이 어떻게 표현되는지에 대해 소개합니다.
아래 예제들은 Matplotlib 문서에 제시되어 있는 것들이며, 대부분이 3차원 좌표를 설정한 후 3D 플로팅을 위한 수학방정식을 파이썬으로 구현하고, 이 방정식으로 구한 x, y, z값들을 3차원 좌표상에 그리되 표면을 특정한 색상으로 칠하거나 삼각형으로 채워서 나타내는 방법을 보여줍니다.
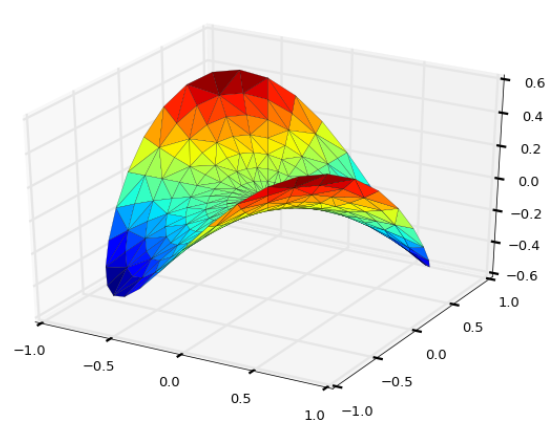
코드가 수학식이라 해석이 까다롭기 때문에 그냥 이런식으로 3D 플로팅을 하는구나 하고 넘어가시기 바랍니다. 다만 Suface 플로팅과 Tri-Surface 플로팅을 위해 활용되는 함수들은 눈여겨 보시기 바라구요..
Surface 플로팅
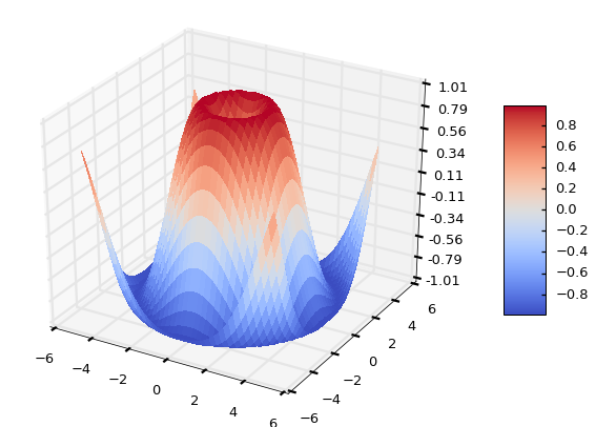
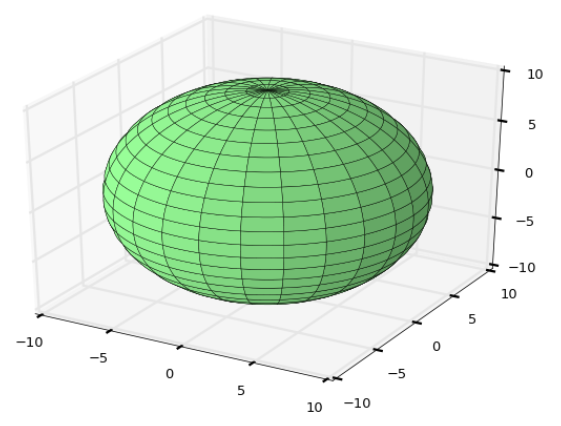

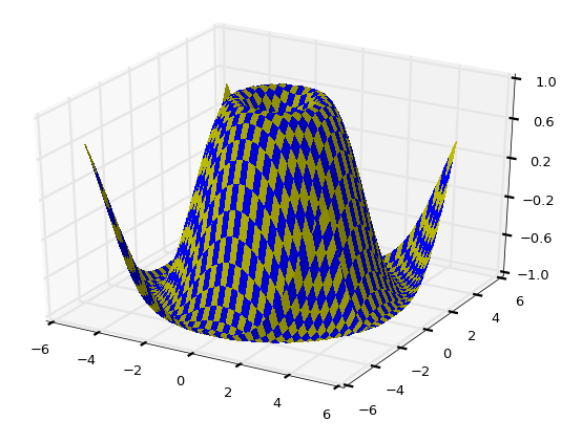
Tri-Surface 플로팅

[출처] 데이터 시각화 프로그래밍18 - 3D 플로팅2|작성자 옥수별
| 데이터 시각화 프로그래밍20 - 3D플로팅4 (0) | 2017.12.14 |
|---|---|
| 데이터 시각화 프로그래밍19 - 3D 플로팅3 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍17 - 3D 플로팅1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍16 - Matplotlib 애니메이션 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍15 - 서브플롯 활용하기 (0) | 2017.12.14 |
파이썬 Matplotlib을 이용한 데이터 시각화 프로그래밍17 - 3D 플로팅1
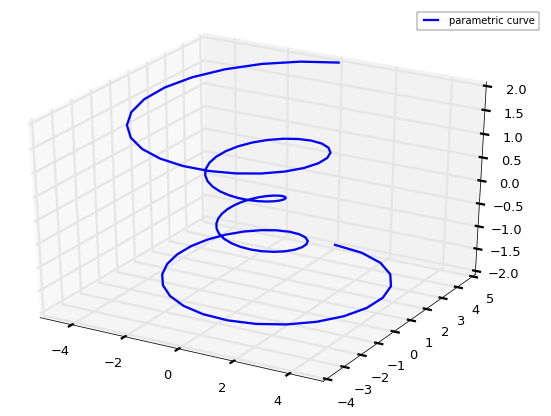
Matplotlib은 3차원 좌표에 플로팅 해주는 다양한 기능들을 제공하고 있습니다. 이번 포스팅에서는 다음과 같은 내용에 대해 살펴봅니다.
3D 곡선 그리기
3D 플로팅을 하려면 3차원 좌표를 설정하는 것이 제일 먼저 해야할 일입니다. 아래 코드는 3차원 좌표에 Parametric 곡선을 그리는 예입니다.

코드의 주요부분만 살펴보면,
>>> mpl.rcParams['legend.fontsize'] = 10
레전드의 폰트 크기를 10으로 설정해줍니다.
>>> ax = fig.gca(projection='3d')
플로팅 하려는 좌표를 3D로 지정합니다. 이제 ax는 3D 좌표가 기준이 됩니다.
>>> ax.plot(x, y, z, label='parametric curve')
x, y, z 를 3차원 좌표에 플로팅합니다.
이상을 보면 2차원 좌표에서 플로팅하는 것과 비교하면 z값이 하나 더 늘었을 뿐입니다. 결과는 아래와 같습니다.
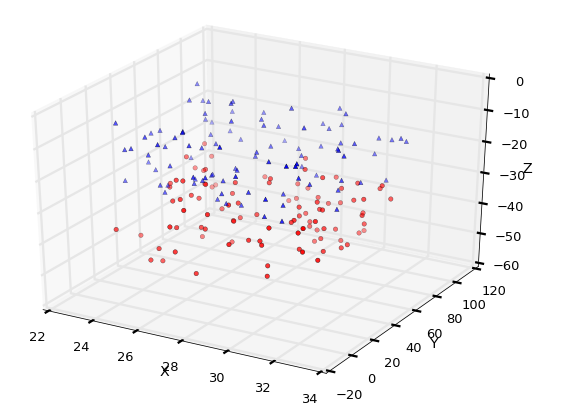
3D 산점도 그리기
3차원 좌표에 산점도를 그리는 것 역시 제일 먼저 해야할 일은 3차원 좌표계를 설정하는 것입니다.

>>> ax = fig.add_subplot(111, projection='3d')
3D 곡선 그리기에서 3차원 좌료를 설정하기 위해 fig.gca(projection='3d')를 이용했지만, 여기서는 3차원 서브플롯을 추가하여 설정했습니다.
결과는 아래와 같습니다.
3D 와이어 프레임 그리기

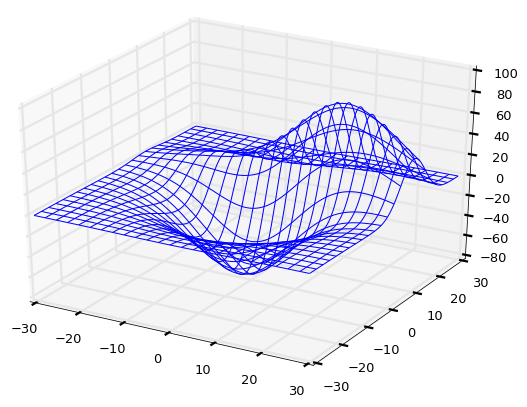
>>> X, Y, Z = axes3d.get_test_data(0.05)
mpl_toolkits.mplot3d.get_test_data()는 테스트용 3차원 좌표 샘플을 만들어 줍니다.
>>> ax.plot_wireframe(X, Y, Z, rstride=5, cstride=5, lw=1)
3차원 좌표에 와이어 프레임을 그립니다. 와이어의 간격은 row 방향으로 5(rstride=5), column 방향으로 5(cstride=5)이며 선두께는 1로 설정했습니다. 이 값들을 적절하게 변경하면 와이어 프레임의 모양이 달라집니다. 만약 rstride나 cstride의 값이 0으로 설정되면 해당 방향의 와이어는 사라집니다.
결과는 아래와 같습니다.
[출처] 데이터 시각화 프로그래밍17 - 3D 플로팅1|작성자 옥수별
| 데이터 시각화 프로그래밍19 - 3D 플로팅3 (0) | 2017.12.14 |
|---|---|
| 데이터 시각화 프로그래밍18 - 3D 플로팅2 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍16 - Matplotlib 애니메이션 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍15 - 서브플롯 활용하기 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍14 - 그래프에 주석 달기 (0) | 2017.12.14 |
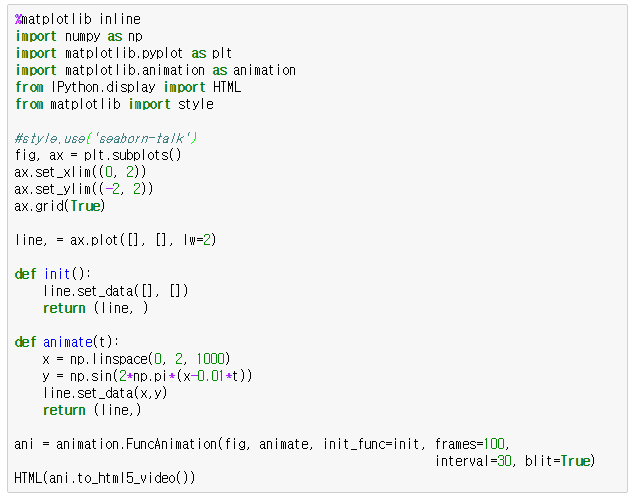
파이썬 Matplotlib을 이용한 데이터 시각화 프로그래밍16 - Matplotlib 애니메이션으로 라이브 그래프 그리기
Matplotlib은 애니메이션 기능을 제공하여 라이브 그래프를 그릴 수 있게 해줍니다. 아래의 코드를 보시죠~
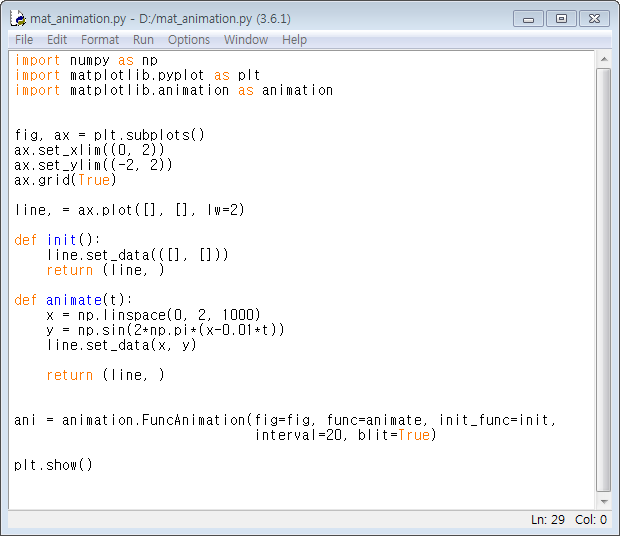
이 코드는 삼각함수 사인그래프를 오른쪽 방향으로 움직이게 합니다. 자, 아래의 수학 함수를 생각해봅니다.
![]()
이 함수는 주기가 1인 사인 곡선을 양수 t의 값을 연속적으로 증가시키면 사인 곡선 전체를 오른쪽으로 움직이게 하는 효과를 발휘합니다. 이는 고등학교 수학을 충실히 학습한 분들은 모두 알 수 있을 겁니다.
위 코드는 이 함수를 Matplotlib 애니메이션으로 시각화하는 코드입니다. Matplotlib에서 애니메이션을 수행하는 함수는 FuncAnimation()입니다. 이 함수의 주요 인자를 살펴보면
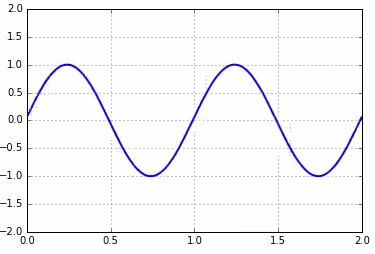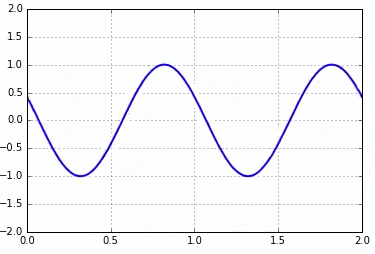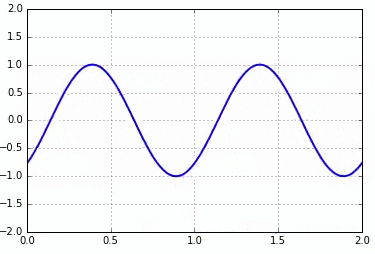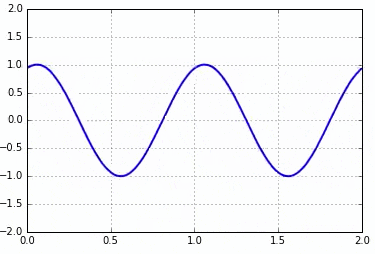
아래는 interval의 값이 20, 30, 10일 때 결과입니다.
interval = 20
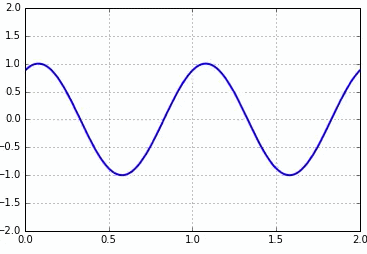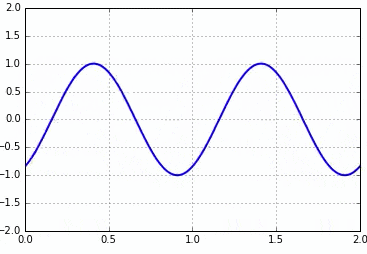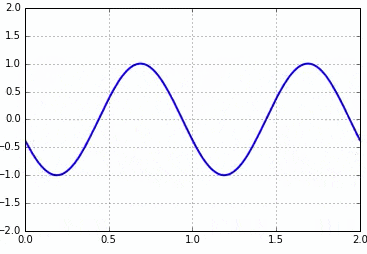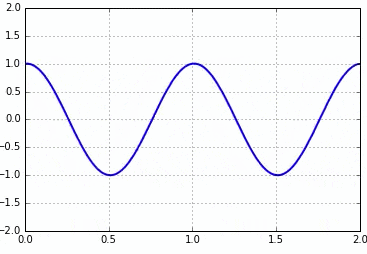
interval = 30
interval = 10
만약 Jupyter Notebook을 활용하고, Jupyter Notebook 내에 애니메이션 결과를 나타내고자 하면 아래의 코드와 같이 작성하면 됩니다.
Jupyter에서 Matplotlib 애니메이션이 가능하게 하려면
아래는 Matplotlib 애니메이션으로 표현할 수 있는 다양한 애니메이션 예입니다. 각 애니메이션에 대한 소스코드를 설명하기에는 수학적인 지식이 필요하고, 포스팅에 많은 시간이 필요할 것 같아서 실제 소스코드의 링크만 걸어둡니다. 필요하신 분들은 소스코드를 참고하시어 응용하시면 되겠네요~
Decay - 소스코드 바로가기
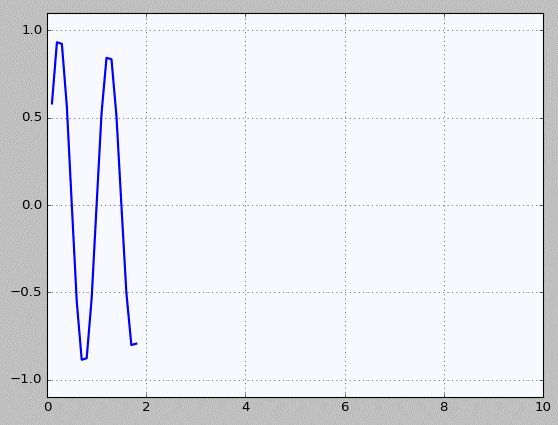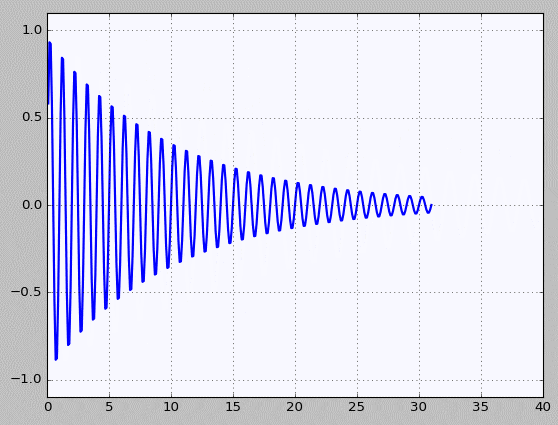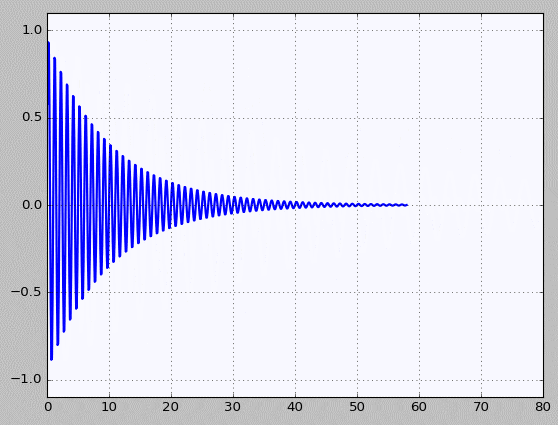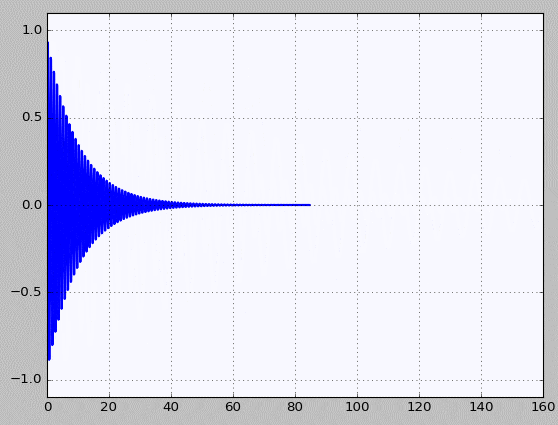
Basic - 소스코드 바로가기
Dynamic Image - 소스코드 바로가기
Unchained - 소스코드 바로가기

Subplots - 소스코드 바로가기
Strip Chart - 소스코드 바로가기
Bayes_update - 소스코드 바로가기
Double_pendulum - 소스코드 바로가기
Histogram - 소스코드 바로가기
Rain - 소스코드 바로가기

Random 3D animation - 소스코드 바로가기
이와 같이 Matplotlib으로 표현할 수 있는 애니메이션은 매우 다양합니다. 데이터를 분석하고 이를 어떻게 사용자에게 보여줄 것인지 잘 기획한 다음 최적의 효과를 낼 수 있도록 해보세요~
[출처] 데이터 시각화 프로그래밍16 - Matplotlib 애니메이션|작성자 옥수별
| 데이터 시각화 프로그래밍18 - 3D 플로팅2 (0) | 2017.12.14 |
|---|---|
| 데이터 시각화 프로그래밍17 - 3D 플로팅1 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍15 - 서브플롯 활용하기 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍14 - 그래프에 주석 달기 (0) | 2017.12.14 |
| 데이터 시각화 프로그래밍13 - Matplotlib 스타일 적용하기 (0) | 2017.12.14 |