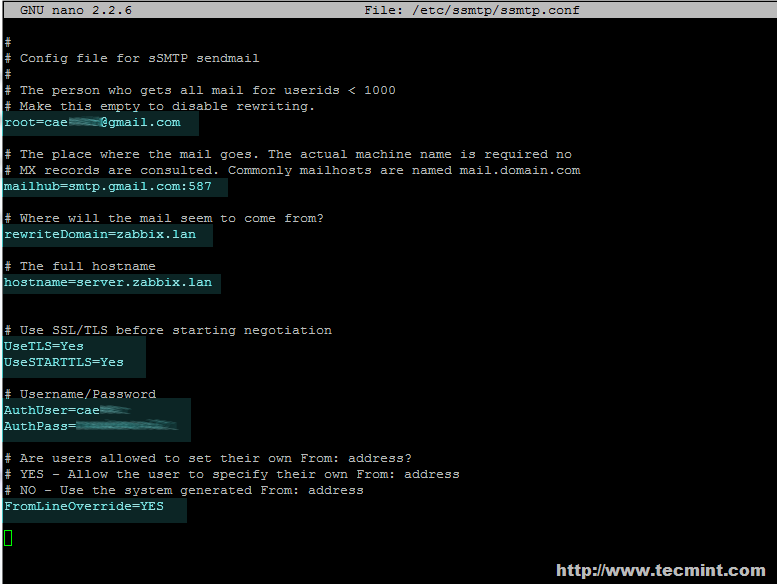
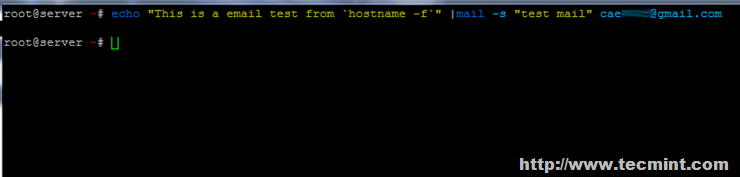
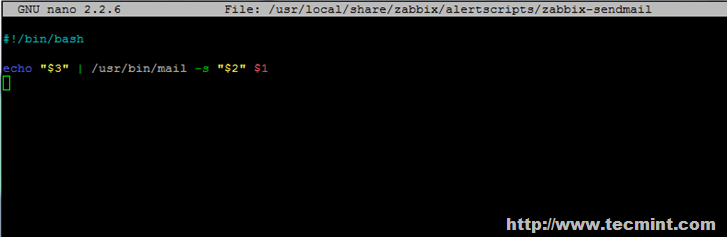
빅데이터 저장소
- 1테라 바이트를 약 100MB/S 로 전송한다면 2시간 반 이상 걸린다.
- 100개의 드라이브가 있고, 각 드라이브는 100/1씩 저장하고 병렬로 동작한다면 2분내에 데이터를 읽을 수 있다
- 병렬 분산처리를 위해서는 하드웨어 장애와 데이터 분할 결합에 대한 고려가 필요하다.
- 하둡은 안정적인 공유저장소(HDFS)와 분산 프로그래밍 프레임웍(맵리듀스)을 제공한다.
HDFS
- 파일시스템(Storage)
- FILE은 Block 단위(64MB or 128MB)로 분할되고 분산되어 저장됨
- 분할된 정보는 Name node(master)에 메타정보가 기록이 되고, 실제 분할된 파일은 Data node(Slave)들에 분산되어 저장이 됨
- Name node 가 없으면 Data node에 저장된 분할된 파일을 찾을 수 없다.
- 각 Block은 장애 복구 용도로 복제본이 생성(default 3 copy) 되어 여러 Data node에 분산되어 저장이 된다.
- HDFS 접근 방법 : Shell 사용(hadoop fs), Java API, Ecosystem(Hue, Sqoop, Flume)
- A.log 파일을 hadoop fs -get 하여 가져올때 Name node에서 해당 파일의 메타 정보를 기준으로 분산저장이 되어 있는 Data node에 저장된 파일을 찾아온다. 이때, 복제본중에서 리소스가 여유있는 서버(혹은 Data node)에 저장되어 있는 파일을 찾아준다.
- Job tracker(master) 데몬이 각각의 task들을 관리해주고 있고, Task tracker(slave) 데몬은 각 Data node에 있는 분산파일 처리를 담당하고 있다.
- Task tracker는 mapper task와 reducer task로 구성이 되어 있으며 해당 task가 위치한 Data node의 데이터를 사용해서 MapReduce를 수행한다.
MapReduce
- Hadoop 클러스터의 분산 데이터를 처리하기 위한 방식(computation)
- 큰 파일을 분할(map)하여 저장하고, 분할된 파일을 다시 하나로 병합(reduce)하는 프레임웍
- 예시, wordcount(단어 갯수 세기), 1억개 단어를 가지고 있는 하나의 파일을 단일 프로세스로 수행하는 것보다 100개 단어를 가지는 100만개 파일로 분할하여 각각 수행하고 이 결과를 최종 병합하여 수행하는 개념이다.
- map은 다수의 data node에 동일한 작업을 수행한다.
- HDFS(Disk)에서 데이터를 read하여 MapReduce 수행하고 완료되면 HDFS(Disk)에 데이터를 다시 write한다.
- Disk IO는 비용이 크기 때문에 이를 Memory로 대체하는 방법이 대안으로 제시된다. (Spark)
- 각 data node의 task들이 모두 완료가 되어야 Reduce를 수행할 수 있다. (하나라도 늦게 끝나면 전체적으로 처리시간이 늦어지는 문제점이 있다.)
- Mapper는 Key/Value 형태로 데이터를 읽어서 처리하고 그 결과를 [Key/Value] List 형태로 출력한다.
- Mapper 출력의 Key 값은 중요하게 사용할 수도 있고 무시할 수도 있고 변경하여 새로운 key를 생성할 수도 있다.
- Mapper는 각 pc에서 memory를 사용해서 처리됨으로 시간이 짧게 걸린다.
- Reducer는 shuffle, sort가 이루어지고 최종적으로 원하는 결과를 출력하도록 수행이 된다.
- shuffle은 Mapper가 출력한 데이터를 Reducer에게 적절히 배분하여 전달해주어야 함으로 시간이 상당히 오래걸린다.(하둡이 해줌)
- sort는 key 값을 cache하여 같은 key 값을 갖는 데이터는 같은 reducer로 전달이 된다.
- Reducer의 입력은 Mapper의 출력인 [Key/Value] List 형태가 되고, 출력은 Key/Value 가 된다.
- Reducer의 출력은 다시 HDFS에 저장된다.
- MapReduce 프로그램은 Java or Python으로 한다.

HIVE
- MapReduce 프로그램을 통해서 데이터를 처리하거나 분석해야하는데 데이터 분석자는 프로그램을 할줄 모른다.
- 페이스북에서 이에 대한 고민을 통해서 Hive를 만들었다.
- RDBMS의 Sql와 비슷하게 작성된 문장(HiveQL)을 Hive가 이를 Mapreduce로 converting 하여 수행해준다.
- structured data 를 Hadoop file system에 저장하기 위한 data warehousing system이다.
- MapReduce를 몰라도 대용량 데이터를 처리하기 용이하다.
- high level 언어임으로 단점이 발생함.(개별 record의 insert, update, delete, transaction이 지원안됨)
- 로그 분석, Data/Text mining(기계학습), 광고배달, 스팸방지등에 활용된다.
- Local PC에 mysql DB를 생성하고 메타데이터(테이블)를 생성 한후 HDFS로 올리는 방법을 많이 사용한다. 직접 HDFS에 생성하는 것은 힘듬
- RDBMS Table을 Hadoop HDFS File로 올릴때에는 Sqoop을 사용한다.
- Hive도 Metastore(master)가 있고, Hive Tables(slave)가 있다. HDFS의 구성과 비슷하게 생성이 됨.
- 기존의 RDBMS 데이터를 HDFS에서 사용이 가능하다.
- Hive에서 ngrams를 지원해준다.
- Hive에서 sentences() 함수는 문장을 array of words로 변환해준다. 2개 이상의 문장은 2-dimensional로 변환해준다.
n-grams
- 검색엔진과 같은 application에서 검색결과의 spelling 교정에 사용
- 웹 페이지에서 가장 중요한 topics 찾는데 사용
- SNS message등에서 트랜드 topics 검색에 사용
Python Basics
http://ai.berkeley.edu/tutorial.html#PythonBasics
pySpark
- RDD(Resilient Distributed Dataset) : 메모리에 데이터 손실이 되어도 다시 생성이 가능하고, 메모리에 분산 저장되어 있고, 초기 데이터는 파일을 통해 가져온다.
- RDD는 spark의 기본적인 데이터 단위이다.
- RDD를 생성하는 방법
sc.textFile("text.txt") #from file to RDD
sc.parallelize(num) #from memory(list) to RDD
objectRDD.map(lambda line: line.upper()) #from RDD to new RDD
- RDD Operations
Actions : RDD의 값을 리턴하거나 내장함수를 사용한다.
Transformations : 현재 RDD로 부터 새로운 RDD를 생성한다.
- RDD는 immutable이여야 하며, 절대로 값이 불변이다. 그러므로 변경하고자 할때에는 transformation을 통해 새로운 RDD로 생성해야 한다.
- transformation에 사용되는 대표적인 함수는 map(f), filter(f), flatMap(f), distinct() 이다.
http://spark.apache.org/docs/latest/programming-guide.html#transformations
- action에 사용되는 대표적인 함수는 count(), take(n), collect(n), saveAsTextFile(path) 이다.
http://spark.apache.org/docs/latest/programming-guide.html#actions
- RDD 데이터는 action 함수로 인한 작업을 만날때까지는 실제적으로 수행/처리되지 않는다. transformations는 즉시 수행이 되지 않는다. (Lazy Execution)
- 복잡한 처리를 한번에 수행하게 되면 시간이 오래걸리므로, 중간에 적절하게 action 함수를 혼용해서 프로그래밍 한다.
- transformations 구문들은 chaining 하여 1라인으로 작성해도 된다.
- Spark 에서는 driver와 executors로 구성이 되고 이 둘 사이에는 통신을 한다.
- Spark Application 을 시작할때 SparkContext 생성으로 부터 시작되고 Master node에서는 동작 가능한 cores을 사용자의 spark application에 할당한다.
- 사용자는 보통 Spark Context를 사용해서 RDD 생성하고 사용한다.
- SparkContext 사용 방법 : sc = SparkContext(conf = conf)
- Partition 갯수 변경 및 확인 방법 : repartition(n), getNumPartitions() <- number만 지정해주면 spark이 알아서 분배해준다.
- python의 range(10,21) 함수는 선언 즉시 메모리를 할당하고 list 값을 갖지만, xrange 함수는 실행되는 시점에 메모리를 할당(lazy evaluation)한다.
- RDD의 lineage 확인하는 방법 : RDD.toDebugString()
- RDD의 type 확인하는 방법 : print 'type of RDD: {0}',format(type(RDD))
- map 함수를 사용하는 방법 : RDD.map(f), f 함수는 partition별로 처리할 로직의 함수이며 새로 생성되는 RDD는 동일한 partition 수를 갖는다.
- filter 함수를 사용하는 방법 : RDD.filter(f), f 함수는 true or false 값을 리턴해주어야 하며 true에 해당하는 data만 남게된다. data가 없어도 partition 수는 그대로 유지가 된다.
- reduce 함수는 파라메터로 function을 전달 받는데 이 function은 항상 associative(더하기 연산) 하고 commutative(곱하기 연산) 해야한다. (마이너스나 나누기 연산은 partition 변경에 따라 값이 달라지므로 사용 불가)
- takeSample 함수는 중복 허용 여부에 따라 num 갯수만큼 샘플링한다. seed 값을 사용하면 항상 같은 샘플링 값이 나오도록 할 수 있다.
- key/value 데이터의 경우에는 reduceByKey(f) 를 사용할 수 있다. 동일node의 같은key기준으로 병합한다. 이는 shuffling 할 때 네트워크 부하를 줄여주는 효과가 있다. (groupByKey()는 데이터가 많이 몰릴경우 네트워크 부하발생 및 out of memory가 발생할 수 있어 주의해야한다.)
- mapValues(sum) 이나 mapValues(list)를 사용해서 pySpark에서 처리도 가능하다.
- pySpark wordcount
text = sc.textFile("test")
wc = text.flatMap(lambda line : line.split()).map(lambda word : (word,1)).reduceByKey(lambda c1,c2 : c1+c2)
wc.collect()
print wc.sortByKey(ascending=True).collect()
print wc.map(lambda (w,c) : (c,w)).sortByKey(ascending=False).collect()
- file 기반의 검색 및 split 하기 위해서 정규화표현식(Regexp)을 사용한다.
(참고)
http://www.kocw.net/home/search/kemView.do?kemId=1174002
http://wiki.gurubee.net/pages/viewpage.action?pageId=28116079
http://hadoop.apache.org/
http://spark.apache.org/docs/latest/programming-guide.html