1.INDEX의 정의
1)정의
데이터를 찾을 때 시간을 단축하기 위해서 사용되어진다.
특정한 값을 찾기 위해 INDEX가 없으면 TABLE SCAN을 이용 함으로
서버 퍼포먼스가 저하된다.
2)특징
신속한 자료 검색을 위해 이용
단점 : DML문을 이용한 데이터의 추가/삭제 시 과부하로 인한 서버 속도 저하
(이유:DB변경시 INDEX도 변경해줘야 한다.)
3)TABLE에 INDEX를 사용하는 이유
TABLE 내에 존재하는 각가의 레코들의 유일함(UNIQUE)를 증명
TABLE 상호 간의 JOIN속도 증가
자료의 조회가 빠름
ORDER BY와 GROUP BY의 빠른 수행
4)모든 COLUMN에 사용 하지 않는 이유
INDEX작성 시 많은 시간 소요
INDEX작성 시 과도한 디스크 영역의 사용
CLUSTERED의 경우 TABLE SIZE의 5%증가
NONCLUSTERED의 경우 TABLE SIZE의 10~20%증가
DML(INSERT,DELETE,UPDATE)문 사용시 많은 시간 소요
2.INDEX의 생성 구문
인덱스 종류 | Clustered | NonClustered |
테이블 당 생생 갯수 | 1개 | 249개 |
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERD] INDEX -- 지정해주지 않을경우 UNIQUE하지
index_name 않고 NONCLUSTERED한 INDEX생성
ON <TB_NAME>(column [ASC|DESC])
WITH <elational_index_option>
ON [partition_scheme_name
| filegroup_name -- TABLE를 0번에 생성하고 INDEX를 1번에 생성하면 디스크 분산 사용으로
| default 인한 성능 향상 효과를 가질 수 있다.
<relational_index_option>
PAD_INDEX = [ON|OFF] -- INDEX 생성시 여유값을 가지냐 마냐를 설정
FILLFACTOR = -- PAD_INDEX ON값 일 때 여유값을 여기서 설정해준다.
초기 INDEX값은 2개의 행만 입력할 공간을 남기고 INDEX페이지를
채운다. DML문의 의해 INDEX갱신시 페이지 분할로 인한서버성능이 저
하 되기떄문에 초기 값을 높여주면 INDEX 페이지 분할 확률이 감소된다.
하지만 초기값이 높기 떄문에 초기에 낭비되는 공간으로서 물리적 공간
을 많이 잡아줘야 하는 단점이 있다.
ex)fillfactor=50은 Index 페이지 50%+나중 Index 페이지 공간
SORT_IN_TEMPDB=ON|OFF -- INDEX생성시 정렬작업을 TEMPDB에서 한다는 것으로 해당 DB의
로딩이 상당히 줄어드는 효과가 있다. TEMPDB는 물리적 독립된 저
장 공간을 가져야 하며 공간도 커야 하다.
IGNORE_DUP_KEY =ON|OFF
STATISTICS_NORECOMPUTE= ON|OFF
ONLINE=ON|OFF --초기값은 OFF 이며 ON시키면 Index생성중에도 TABLE의 쿼리가 가능하다
DROP_EXISTING=ON|OFF --사용시 INDEX 만드는 시간을 단축
ALLOW_ROW_LOCKS= ON|OFF
ALLOW_PAGE_LOCKS=ON|OFF
MAXDOP = max_degree_of_parallelism --INDEX생성시 사용되는 CPU의 갯수 기본값은 0(자동)
밑줄 기본값
ex)인덱스 생성
create view a_money with schemabinding
as
select count_big(*) '부서인원'
,d.deptno
,sum(isnull(s.sal,0)*12+isnull(s.comm,0)) 'yearpay'
from dbo.sawon s inner join dbo.dept d
on s.deptno = d.deptno
group by d.deptno
create index a_u_clidx_a_money_deptno -- UNIQUE하지 않고 Nonclustered한 Index생성
on a_money(deptno);
인덱스 제거
drop index TABLE_NAME.INDEX_NAME
비고> 1. text,ntext,image,bit 자료형의 컬럼에는 INDEX생성 불가
2. 복합인덱스(Composite INDEX)생성시 최고 900 byte를 넒지 못한다.
즉, 중복 PK의 총 사이즈는 900 Byte.
Varchar가 8000Byte까지 가능하지만 900Byte이상으로 잡은 컬럼은 PK생성 불가.
3. 최대 16개의 컬럼을 조합하여 하나의 INDEX생성 가능
4. 계산된 열에도 INDEX의 생성 가능. persisted키워드를 사용
create table sungjuk2
(hakbun varchar(10)
,kor smallint
,eng smallint
,math smallint
,total as (kor+eng+math) persisted
,average as (kor+eng+math)/3.0
);
go
create index ncl_sungjuk2_total
on sungjuk2(total desc);
sp_helpindex sungjuk2;
![]()
5. INDEX 생성의 Create index 로 만드는 것과 PK와 UK 제약으로 만드는 2가지다.
PK는 자동적으로 unique와 clustered index생성
UK는 자동적으로 unique와 nonclustered index생성
ex) alter table sungjuk2
add constraint a_kor_pk primary key nonclustered(kor); -- nonclustered값을 지정해주면 강제로
clustered가 아닌 non의제약을준다
sp_helpindex sungjuk2
![]()
반대로 UK를 clustered화 시킬 수도 있다.
3. INDEX 의 구조
1)데이터 페이지 -> 실제 데이터를 담고 있는 부분
2)인덱스 페이지 -> 인덱스를 담고 있는 부분 인덱스=인덱스페이지 데이타=데이타페이지
인덱스와 데이타는 공존하지 않는다.
3)루트 레벨(Root level)
->B-TREE(Balaced TREE) 구조에서 가장 최상위 즉 인덱스의 최상위 단계
4)넌리프 레벨(Non-leaf level)
-> 최상위와 제일 하위단계가 아닌 나머지 모든 단계로 Key 와 자식페이지의 대한 주소를 가짐
5)리프 레벨(Leat Level)
-> B-TREE 제일 하위단계로 KEy와 실제 데이타 위치(rowID)값을 가진다.
4. INDEX의 종류
1)Clustered Index
▶ Clustered Index가 있는 테이블은 테이터의 순서가 입력한 순서가 아닌 Clustered Index가 걸려진
컬럼의 오름차순 정렬되어 데이터페이지에 입력되어 보여진다.
ex)
sp_helpindex sawon
![]()
set rowcount 10
select * from sawon
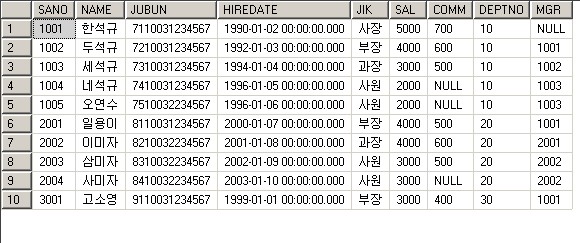
clustered된 sano순서되로 값이 출력된다.
▶ Clustered Index를 구성하면 데이타페이지가 리프 페이지가 되므로 데이타 페이지의
데이타는 항상 오름차순으로 정렬되어진다.
▶ Clsutered Inder의 실행 계획은 Clustered Index Seek이다.

2)NonClustered Index
create table NonClustertbl
(id int
,name nvarchar(10));
create unique nonclustered index uni_nclidx_nonclustertbl_id
on nonclustertbl(id);
insert into nonclustertbl values(1003,'삼용이')
insert into nonclustertbl values(1007,'칠용이')
insert into nonclustertbl values(1009,'구용이')
insert into nonclustertbl values(1001,'일용이')
insert into nonclustertbl values(1004,'사용이')
insert into nonclustertbl values(1002,'이용이')
insert into nonclustertbl values(1005,'오용이')
insert into nonclustertbl values(1008,'팔용이')
insert into nonclustertbl values(1006,'육용이')
insert into nonclustertbl values(1010,'십용이')
▶ NonClustered Index의 테이블은 테이터의 순서가 입력한 순서대로 저장된다.
sp_helpindex nonclustertbl
![]()
select * from nonclustertbl

▶ NonClustered Index의 경우 인덱스가 저장되는 물리적 파일병은 해당 테이블이 저장되는 물리적인 파일명과 달라야 좋은 성능의 효과를 기대 할 수 있다.
Create unique nonclustered index uni_nclidx_nonclustertbl_id
on nonclustertbl(id)
on indexgroup
▶ NonClsutered Inder의 실행 계획은 Clustered Index Seek이다.
select *
from nonclustertbl
with(index(uni_nclidx_nonclustertbl_id)) -- with(index(index_name))
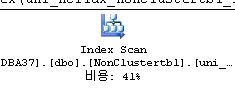
select *
from nonclustertbl
with(index(0)) -- 해당 인덱스를 사용하지 않겠다는 말
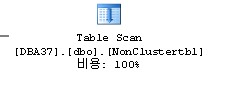
NonClustered Index만 존재하는 테이블에 데이타가 insert되면은 데이타페이지에는 분할이 발생되지 않고 인덱스 페이지에만 Sort로 인한 분할이 발생된다.
3)Clustered Index 와 NonClustered Index와의 공존시
create table clusnonclustbl
(id int
,name nvarchar(10)
,addr nvarchar(10));
create unique clustered index uniclidx_clusnonclustbl_id
on clusnonclustbl(id);
create index nclidx_clusnonclustbl_name
on clusnonclustbl(name);
insert into clusnonclustbl values(1003,'삼용이','서울')
insert into clusnonclustbl values(1007,'칠용이','인천')
insert into clusnonclustbl values(1009,'구용이','수원')
insert into clusnonclustbl values(1001,'일용이','서울')
insert into clusnonclustbl values(1004,'사용이','수원')
insert into clusnonclustbl values(1002,'이용이','인천')
insert into clusnonclustbl values(1005,'오용이','서울')
insert into clusnonclustbl values(1008,'팔용이','부천')
insert into clusnonclustbl values(1006,'육용이','서울')
insert into clusnonclustbl values(1010,'십용이','인천')
▶ Clustered Index와 NonClustered Index 있는 Clustered Index가 걸려진 컬럼의 오름차순 정렬되어 데이터페이지에 입력되어 보여진다
sp_helpindex clusnonclustbl

select * from clusnonclustbl

▶ 동일한 테이블에 Clustered Index 와 NonClustered Index가 모두 존재하는 경우 NonClustered Index의 리프레벨이 가리키는 값이 데이터의 주소값이 아니라 Clustered Index를 카리키는 이유는 시스템 부하를 줄이기 위해서이다. NonClustered Index값이 데이타 값을 지정하고 있다면 , 새로 insert되는 데이타 값은 NonClustered Index에 저장 되어지고 동일 테이블 안에 있는 Clustered index에 의해 재배열 된다면 또 데이타 값은 다시 NonClustered Index에 저장되어지는 시스템 적인 과부하가 걸린다.
---> 따라서 인덱스 생성순서는 Clustered Index 에서 Nonclustered Index순으로
인덱스의 삭제는 역순으로 해줘야 시스템 과부하 덜 걸린다.
---> Nonclustered Index의 리프 레벨에는 Clustered Index의 값이 들어오므로, 될수록 Clustered
Index 가 되는 컬럼의 크기를 작게 잡아야 Nonclustered Index에 저장되는 크기도 작아지며 성
능이 향상된다.
'연구개발 > SQL2005' 카테고리의 다른 글
| Linked Server (0) | 2010.06.18 |
|---|---|
| INDEX 2 (0) | 2010.06.18 |
| INDEXING VIEW (0) | 2010.06.18 |
| UNION ,UNION ALL ,INTERSECT and EXCEPT (0) | 2010.06.18 |
| join & subquery 연습 (0) | 2010.06.18 |