북마크 룩업 :

미리 밝혀두는데, MS-SQL 2005 로 넘어오면서 Bookmark Lookup이란 사라졌다. 하지만, 분
명 알아두면 좋은 얘기기도 하니 일단 집고 넘어가는게 좋겠다.
아래는 MSDN에서 찾은 북마크 룩업에 대한 내용이다.
The Bookmark Lookup operator uses a bookmark (row ID or clustering key) to look up
the corresponding row in the table or clustered index. The Argument column contains
the bookmark label used to look up the row in the table or clustered index. The
Argument column also contains the name of the table or clustered index in which the
row is looked up. If the WITH PREFETCH clause appears in the Argument column, the
query processor has determined that it is optimal to use asynchronous prefetching (read-
ahead) when looking up bookmarks in the table or clustered index.
Bookmark Lookup is not used in SQL Server 2005. Instead, Clustered Index Seek
and RID Lookup provide bookmark lookup functionality. In SQL Server 2005 Service Pack
2, the Key Lookup operator also provides this functionality.
해석해보자.
------------------------------------------------------------------------------------
Bookmark Lookup 연산자는 책갈피(행 ID 또는 클러스터링 키)를 사용하여 테이블이나
클러스터형 인덱스에서 해당 행을 조회합니다. Argument 열에는 테이블이나 클러스터형
인덱스에서 행을 조회할 때 사용하는 책갈피 레이블이 포함됩니다. Argument 열에는 행
을 조회하는 테이블 또는 클러스터형 인덱스의 이름도 포함됩니다. WITH PREFETCH 절
이 Argument 열에 나타나는 경우에 쿼리 프로세서에서는 테이블 또는 클러스터형 인덱
스에서 책갈피를 조회할 때 비동기 사전 인출(미리 읽기)을 사용하는 것을 최적의 방법
으로 결정합니다.
북마크 룩업은 SQL Sever 2005에서는 사용하지 않는다. 대신에, Clustered Index Seek와
RID Lookup이 북마크 룩업 기능을 제공한다. SQL Server 2005 서비스팩 2에서는 키 룩업
연산자가 이 기능을 제공한다.
------------------------------------------------------------------------------------
이게 대체 뭔말이냐...
책갈피(Bookmark Lookup) 살펴보기
우선 책갈피란 무엇일까 생각해보자. 그렇다쿠나. 아까까지 보고 있던 책 위치를 표시해 두고
다음에 읽을때 정확하게 그 페이지를 다시 보려고 사용한다. (어제 오셨던 손님 또 오셨군요~
에헤~ (~--)~) 물론, 찌게 받침대와 같이 특이한 것으로 사용하려는 번거로운 녀석들을 제외
하고 일반적인 용도가 그렇다는 것이다.
SQL Server는 이 책갈피를 RID(Row ID, 행 ID), 클러스터링 키(Clustering Key)라고 부른다.
이 책갈피에는 실제 데이터가 존재하는 위치를 적어놨다. (마치 독도에 대한 언급인 세종실록
지리지 50페이지 셋째줄처럼...)
RID는 클러스터드 인덱스가 없는 경우에 실제 데이터가 존재하는 Row ID를 말하며 클러스터
링 키는 클러스터드 인덱스가 있는 경우 클러스터드 인덱스를 탐색할 수 있게 해주는 키를 말
한다. 이런 두가지 키를 가지고 실제 데이터를 찾아가는 과정...이걸 북마크룩업으로 정의한다.
뭔가 멍하다. 당한 느낌이다. 중원의 고수들(?)이야 여기까지만 봐도 미소를 지을만 하지만, 우
리 같은 무수리들(?)이야 감이 오질 않는다. 사실 이제부터 얘기할건 뒷편에서 하고 싶으나 여
기서 해야 할만한 충분한 이유가 있을거 같다. 따라서, 조금 먼길을 돌아가더라도 이해바란다.
데이터와 인덱스 분리형 테이블
실제 데이터와 그 데이터를 찾는 키(인덱스)를 분리하여 저장하는 것은 현재 RDBMS(관계형
DBMS)에서 가장 일반적인 형태이다. 키를 따로 저장해야 한다는 부담, 그래 그게 분명 있다.
하지만, 그보다 데이터와 키를 동일한 위치에 같이 저장하는 것이 더 큰 부담이지 않겠느냐는
거다. 데이터는 아무렇게나 저장해도 좋다. 대신에 나중에 꺼내쓸 때를 위해 목록을 따로 정리
하여 저장해 놓고 언제든 그 위치를 찾아가면 원하는 데이터를 찾을 수 있다면 그것만큼 좋은
건 없다.
분리를 해놓아 데이터를 저장하는데 부담을 막았고, RID나 클러스터링 키를 가지고 실제 데이
터를 찾아가는 방법도 알고 있다. 그래, 이제 찾아가야지. Bookmark 했으니 Lookup해야하지
않겠어? :)
그럼, 이제 이런 북마크 룩업이 언제 생기느냐에 대한 문제만 남았다.
북마크 룩업(Bookmark Lookup) 언제 생기나?
가장 흔한 경우는 요거다.

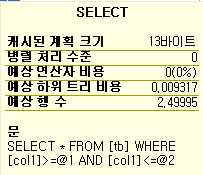
위와 같이 col1에 Non-Clustered Index만 있는 테이블을 select해보자.
select * from test where col1 = 0
MS-SQL 2000에서는 북마크 룩업이 생긴다.
그렇다면,
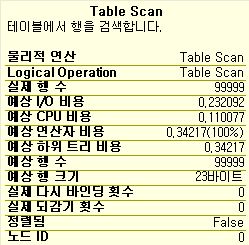
select * from test where col2 = 0
같은 경우는 생길까? 답은 안생긴다. 그냥 Table Scan만 할뿐이다.
그렇다!! 키로 검색할 때만 생긴다는 결론이다. 위에서 얘기했듯 Non-Clustered Index의 키!!!
RID다.
select col1 from test where col1 = 0
그럼, 이건? select * ~~ 가 아니라 select col1로 컬럼을 하나만 검색했다.
이것도 역시 생기지 않는다. 이유라면, 키를 찾았으면 굳이 북마크 룩업을 써가면서 데이터를
찾을 필요가 없다라는 것이 이유다. (흔히, 이걸 커버드 인덱스(Covered Index) 라고 한다.)
아하~ where절에 키로 검색을 하면서 Select절에는 키가 아닌 컬럼을 검색할때 생기는구나
라는걸 알수 있다. 키를 가지고 나머지 행의 데이터를 찾는다. 그리고, 한두개 행을 찾으면
모를까, 여러개의 행을 찾고자하면 대부분의 비용을 잡아먹는 블랙홀 같은 녀석이라 할 수 있
다.
(수정 중...)