바로 가자.

Index Seek :
Index Seek는 Non-Clustered Index를 말한다. Clustered Index와는 달리 Index 생성 당시 키
값에 따른 정렬은 하지 않는다. Non-Clustered Index를 얘기하면 개인적으로 이런 비유를 종
종 쓰곤 하는데 물건을 서랍에 넣는 비유다.
물건을 서랍에 넣고자 한다. 닥치는대로 마구 넣으면 꺼내쓸때 문제가 되더라도 당장 넣는데는
최고의 성능을 발휘하게 마련이다. 근데, Non-Clustered Index는 거추장스런 작업을 한번 하
게 된다. 뭐냐면, 서랍에 닥치는대로 넣긴 하는데 물건이 어디에 있나 메모해놓는다는 것이다.
공은 첫번째 서랍 왼편 5mm지점, 볼펜은 ... (-,.-;;) 그래...좋다이거다. 번거로운 작업이 있긴
하더라도 데이터라는건 입력할때 편하기만 하면 데이터의 존재 가치는 0 이지 않은가? 꺼내쓸
때 또한 불편함 없이, 빠르게 꺼내쓸 수 있으면 정말 좋다.
위에 말한대로 어디에 넣어뒀는지 적어놨다. 볼펜을 꺼내 쓰려면 볼펜의 위치가 적힌 메모지를
참고하여 찾아가면 된다. 그렇다!!!!!!!! 왜 Non-Clustered Index가 점검색(콕찝어 어느 물건 어
디...이런 검색)에 빠른 성능을 보이는지 그 이유가 되기도 한다.
점검색에서 Clustered Index와 Non-Clustered Index의 성능을 비교 -


그래도 Clustered Index Seek가 빠르다는걸 알수 있다. 허허...그럼, 테이블의 모든 컬럼에
Clustered Index로 떡칠해야 하는가? 이궁~ 그건 아니다. 자세한 얘기는 다음에 하겠지만,
필요한 컬럼에 필요한만큼만 주는게 가장 좋다.
어쨌거나 0.00 .. 대라면 사람의 피부로 느껴지는 성능상의 차는 그다지 없다. Non-Clustered
Index도 정말 괜찮은 성능을 낸다. Clustered와 Non-Clustered의 저마만큼의 성능 차이는 물
건이 어디에 있는지 메모지를 한번 더 살펴보는 차이라 보면 되겠다.
그럼, 이런건 어때??
같은 테이블이고 범위검색과 점검색을 해보는거다.
예를 들면
select * from tb where col1 => 0 and col1 <= 1
select * from tb where col1 = 0 or col1 = 1
이것에 대한 비교...둘 다 리턴되는 결과 레코드는 똑같다. 해볼까?
같은 테이블 내에서 범위검색과 점검색을 비교
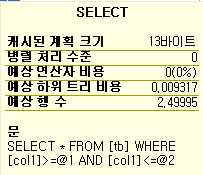

점으로 검색한 녀석이 좀 더 빠르다. 6%정도의 성능 차이를 보인다. 근데, 범위가 커지면 커질
수록 그 차이는 좁혀 오다가 결국에 범위 검색의 성능이 더 좋아진다. (10만개 데이터 기준으로
4개 컬럼비교에서는 둘 다 비슷해지더니 5개 이상부터 범위 검색의 성능이 더 좋아진다.)
그렇다. 1~2개 where col1=0 or col1=2 이런건 성능이 좋으나 비교하는 컬럼이 많아질 수록 성
능이 저하되기 시작하는 것이다.
Index Scan :

인덱스 스캔이다. 이 전 페이지에서 클러스터드 인덱스 스캔에 대한 얘기를 했는데 안봐도 결
과는 비슷할꺼라 예상한다. 클러스터드 인덱스와 마찬가지로 이녀석 또한, 맨 첫번째 키를 사
용하지 않으면 생긴다. Index를 페이지 스캔이나 테이블 스캔이나 똑같다. 이런~~~
Index Scan과 Table Scan 성능 비교


역시나 실행 비용은 거의 비슷하다. Non-Clustered Index Scan이 아주 약간 빠른 정도)
(다음편에 계속.....)
'연구개발 > 실행계획' 카테고리의 다른 글
| 2. 실행 계획 기초 - 실행 계획 깨부수기를 함께하기 위해 먼저 해야 할 일 (0) | 2011.07.17 |
|---|---|
| 1. 실행 계획 기초 - SQL을 질의하면 어떤일이 발생할까? (0) | 2011.07.17 |
| 실행계획 (0) | 2011.07.17 |
| MS-SQL 2005 실행계획 (3) (0) | 2011.07.17 |
| MS-SQL 2005 실행계획 (1) (0) | 2011.07.17 |