우리가 여태까지 다루었던 퍼셉트론, 로지스틱 회귀, SVM, 의사결정 트리, 랜덤 포레스트, kNN과 같은 알고리즘은 트레이닝 데이터를 학습한 후, 주어진 데이터에 대해 어떤 그룹에 속하는지 또는 어떤 범주에 포함되는지 예측하는 분류를 위한 알고리즘입니다.
이번 포스팅에서 다룰 회귀 분석(Regression Analysis)은 분류가 아니라 데이터들 사이의 상관관계라던가, 추이를 예측한다던가, 대상 값 자체를 예측하는 지도학습 알고리즘입니다. 예를 들어, 방의 개수와 집값의 상관 관계라던가, 과거 10년간의 영업 실적을 분석하여 미래의 영업 실적을 예측하는 것 등은 회귀 분석으로 가능합니다.
아래의 식을 살포시 봅니다.
![]()
이 식은 우리가 잘 알고 있는 1차 함수이며, 입력 값이 1개인 퍼셉트론의 순입력 함수로 볼 수 있습니다. 회귀 분석에서는 x를 설명 변수(explanatory variable)라 부르고, y^를 반응 변수(response variable) 또는 대상 변수(target variable)라 부릅니다. 그리고 가중치 w0은 y절편, w1은 설명 변수의 계수가 됩니다.
회귀 분석은 주어진 데이터 (x, y)의 분포를 분석하여 이 분포와 가장 일치하는 직선을 구하는 것이 최종 목표입니다. 결국 회귀 분석의 최종 목표는 데이터 (x, y)의 분포와 가장 일치하는 직선이 되는 w0와 w1을 계산하는 것입니다.

위 그림에서 9개의 설명 변수 x와 그에 대응하는 실제 반응 변수 y의 쌍 (x, y)의 분포를 초록색 사각형으로 표시한 것입니다. 회귀 분석은 이 9개의 사각형의 분포에 가장 일치하는 직선을 구하는 것이며, 이 직선을 회귀직선(regression line)이라 하며 일반적인 경우를 포함하면 그냥 회귀 모델이라 합니다. 회귀선과 개별 사각형과의 수직으로 떨어진 거리를 오프셋이라 합니다.
설명 변수의 회귀 직선 방정식에 의한 반응 값을 y^, 설명 변수에 대한 실제 반응값을 y라 하면, 오프셋의 크기는 다음과 같습니다.
![]()
이 값은 결국 실제값과 회귀 분석에 의한 예측값의 오차(error)입니다.
여기서 예로 든 것처럼 설명 변수가 1개에 기반한 회귀 분석을 단순 회귀 분석(simple regression analysis)이라 합니다. 만약, 설명 변수가 1개가 아니라 n개이면 회귀 분석에서 구해야 할 식은 우리에게 익숙한(퍼셉트론의 순입력 함수가 바로 이것이죠..) 아래의 식처럼 되겠지요.
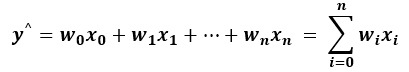
여기서 x0 = 1로 두면 됩니다~
이와 같이 설명 변수가 2개 이상에 기반한 회귀 분석을 다중 회귀 분석(multiple regression analysis)라 합니다.
회귀 분석에 대한 개념은 이쯤에서 마무리하고, 이제 우리가 학습할 데이터를 확보해야겠습니다. 본 포스팅에 첨부한 파일은 1978년 미국 보스턴 교외의 주택 정보 데이터입니다. 첨부한 데이터를 다운로드 받습니다.
이 데이터는 1978년 보스턴 교외의 506개의 주택에 대해 14개 범주의 수치를 정리한 것입니다. 14개 범주는 아래와 같습니다.
- CRIM: 타운별 1인당 범죄율
- ZN: 25,000 평방 피트가 넘는 다수 거주자를 위한 주거 지역 비율
- INDUS: 타운당 비소매 사업 면적 비율
- CHAS: 길이 강과 경계하면 1, 아니면 0
- NOX: 산화질소 농도( 0.1ppm 단위)
- RM: 주택당 평균 방수
- AGE: 1940년 이전에 건축된 주인이 거주하는 주택 비율
- DIS: 보스턴의 5개 고용 센터까지 가중치 거리
- RAD: 방사형 고속도로로의 접근성 지수
- TAX: $10,000 당 최대 자산 가치 비율
- PTRATIO: 타운별 학생-교사 비율
- B: 아프라카계 미국인의 비율을 Bk라고 할 때, 1000 x (Bk - 0.63)^2 의 값
- LSTAT: 인구의 낮은 백분율
- MEDV: 주인이 거주하는 주택 가격의 중간값($1,000 단위)
주택 정보 데이터를 다운로드 받았으면 적당한 폴더에 저장합니다.
이제 우리가 다운로드 받은 주택 정보 데이터를 pandas의 DataFrame 객체로 읽어 출력해봅니다.

코드를 실행하면 주택 정보의 첫 번째 몇 개가 화면에 출력됩니다.
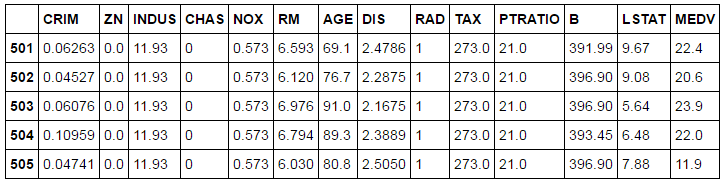
이로써 데이터를 제대로 확보했다는 것을 확신할 수 있네요~
트레이닝 데이터로 머신러닝을 수행하기 앞서, 탐색적 데이터 분석(Exploratory Data Analysis; EDA)이라는 방법을 이용해 데이터를 파악하는 것이 매우 중요하며, 데이터 과학자들은 이를 권장하고 있습니다.
이를 위해 seaborn이라는 유용한 도구 하나를 설치합니다.
pip install seaborn
seaborn은 matplotlib 기반의 통계와 관련된 차트나 분포도를 그려주는 기능들을 제공해주는 파이썬 확장 라이브러리입니다. 우리가 seaborn으로 먼저 해 볼 것은 페어플롯(pairplot)이라는 기능입니다. 일단, 아래 코드를 보실까요..

seaborn의 sns가 제공하는 pairplot()이 위에서 언급한 페어플롯을 그려주는 함수입니다. 설명을 위해 코드를 실행해보기로 하죠. 코드를 실행하면 아래와 같은 페어플롯 그래프가 등장합니다.
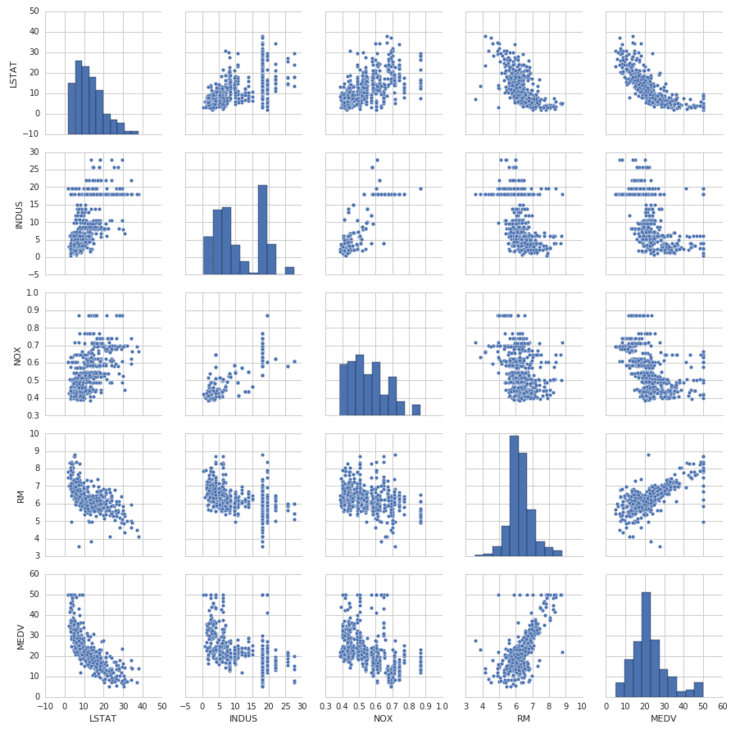
위 그래프를 보면 세로축은 위에서부터 LSTAT, INDUS, NOX, RM, MEDV 이고, 가로축은 왼쪽부터 LSTAT, INDUS, NOX, RM, MEDV 으로 되어 있습니다.
세로축의 RM과 가로축의 MEDV가 만나는 부분에 있는 그래프는, 세로축 값은 RM, 가로축 값은 MEDV로 하는 그래프라는 의미입니다. 따라서 위 그림을 보면 한 눈에 각 범주끼리 상관관계를 쉽게 파악할 수 있겠지요.
예를 들어볼까요..
세로축이 NOX, 가로축이 RM이 대응되는 그래프는 아래와 같습니다.
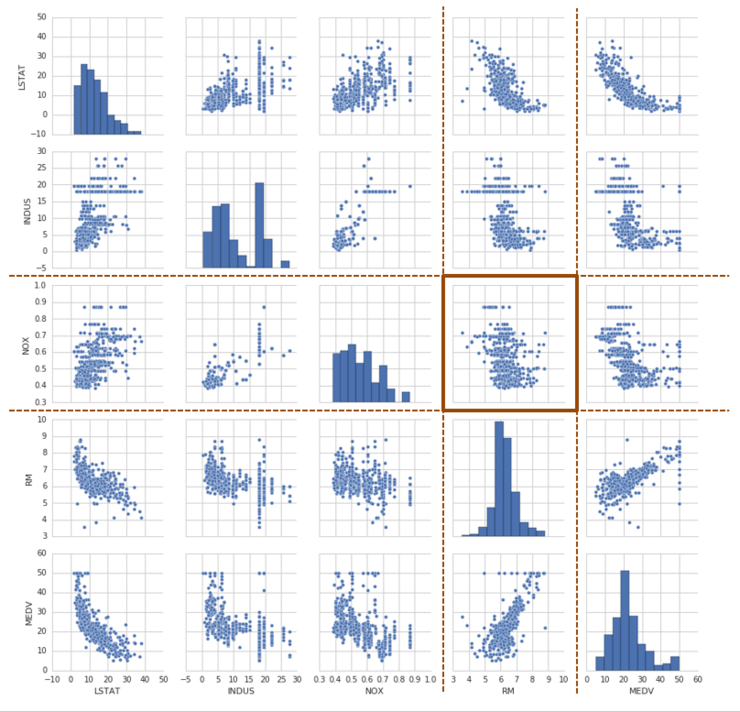
이 그래프에서 분포를 보면 특징적인 모양이 나타나지 않고, 무작위로 분포되어 있는 것처럼 보입니다. 이는 NOX와 RM의 상관관계가 별로 없다는 것이며, NOX의 값이 어떻게 변하든 간에 RM의 값에 영향을 별로 주지 않는다는 의미입니다.
세로축의 LSTAT과 가로축의 MEDV에 해당하는 그래프를 보면 LSTAT의 값이 커지면 MEDV의 값은 작아지고, LSTAT의 값이 작아지면 MEDV의 값이 커지는 경향을 보입니다. 이를 통해, LSTAT과 MEDV는 관련성이 있는 값이라는 것을 알 수 있는 것이죠.
눈으로 관련성을 개략적으로 파악했으니 이젠 정량적인 숫자로도 나타내 봐야겠습니다. 이를 위해 약간의 통계 및 수학적인 지식이 필요한데, 자세한 것은 스킵하고 핵심적인 것만 가볍게(?) 설명합니다.
데이터들 간의 상관관계를 정량화시키려면 상관행렬(correlation matrix)이라는 것을 만들어야 합니다. 상관행렬은 공분산행렬(covariance matrix)이라는 것과 밀접한 관련이 있습니다.
공분산이란 두 개 이상의 데이터가 어떤 연관성을 가지며 분포하는지에 대한 것을 정량적으로 나타낸 값입니다. 실제로, 데이터를 표준화하여 계산한 공분산행렬이 곧 상관행렬입니다.
아무튼 이 상관행렬은 피어슨 상관계수(Pearson correlation coefficients)라 불리는 값을 포함하는 정사각 행렬입니다. 피어슨 상관계수는 줄여서 피어슨의 r이라고 부르기도 합니다.
두 개의 특성 데이터 세트 x, y의 피어슨 상관계수 r은 다음과 같은 식으로 정의됩니다.
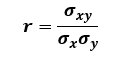
여기서 σx, σy는 x의 표준편차, y의 표준편차이며, σxy는 x와 y의 공분산입니다.
피어슨 상관계수 r은 -1과 1사이의 값을 가지며, 0에 가까울수록 상관관계가 없다는 것을 나타내고, -1이나 1에 가까울수록 상관관계가 강하다는 것을 나타냅니다. 피어슨 상관계수 r의 범위에 따른 상관관계는 일반적으로 다음과 같습니다.
-1.0 ≤ r ≤ -0.7 : 매우 강한 음의 상관관계
-0.7 < r ≤ -0.3 : 강한 음의 상관관계
-0.3 < r ≤ -0.1 : 약한 음의 상관관계
-0.1 < r ≤ 0.1 : 상관관계 없음
0.1 < r ≤ 0.3 : 약한 양의 상관관계
0.3 < r ≤ 0.7 : 강한 양의 상관관계
0.7 < r ≤ 1.0 : 매우 강한 양의 상관관계
머리 복잡한 통계 지식은 이정도로 하고 이제 seaborn의 유용한 기능을 활용해서 보스턴 주택 정보들 간의 상관관계를 정량적으로 표시해보겠습니다. 상관관계를 시각화해서 보여주는 방법 중 히트맵(heatmap)이라는 방법이 있습니다. 양의 상관도가 높으면 빨간색 계통으로, 음의 상관도가 높으면 파란색 계통으로, 아무런 상관관계가 없으면 흰색과 가까운 색으로 표현하는 것입니다.
아래의 코드는 위에서 설명한 페어플롯을 히트맵 + 정량적 상관관계로 표현한 버전입니다.

이 코드를 실행하면 아래와 같은 정량적 상관관계 수치와 함께 히트맵이 화면에 출력됩니다.
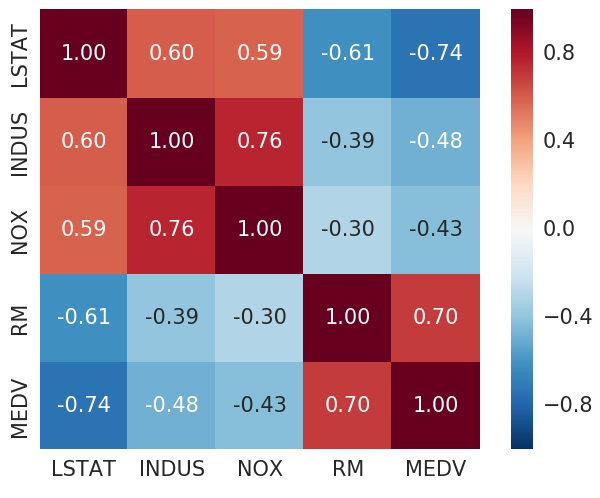
히트맵을 보면 어떤 데이터들이 상관관계가 있는지 정량적인 값으로 쉽게 살펴볼 수 있습니다.
이제 회귀 분석을 위한 준비는 되었으니, 다음 포스팅에서는 히트맵에 표시된 데이터 쌍에서 상관관계가 특별한 몇 개에 대해 회귀 분석을 위한 코드를 구현해 보도록 하겠습니다.
[출처] [23편] 회귀 분석 - 준비하기|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [25편] 회귀 분석 - RANSAC (0) | 2017.12.14 |
|---|---|
| [24편] 회귀 분석 - 최소제곱법 기반 회귀 모델 구현하기 (0) | 2017.12.14 |
| [22편] 머신러닝을 이용한 감정 분석3 - 대용량 데이터에 적용하기 (0) | 2017.12.14 |
| [21편] 머신러닝을 이용한 감정 분석2 - 머신러닝 수행하기 (0) | 2017.12.14 |
| [20편] 머신러닝을 이용한 감정 분석1 - 준비하기 (0) | 2017.12.14 |