하지만 통계학에서 말하는 표준화(Standardization)를 이용해 트레이닝 데이터를 표준화된 값으로 변환하여 머신러닝을 수행하게 되면 비교적 큰 값의 learning rate에도 머신러닝이 유효하게 동작합니다.
우리는 고등학교 수학시간에 정규분포라는 통계학 용어를 접해보았을 것입니다. 정규분포라는 것이 통계학에 있어서는 매우 중요한데, 자연상에 존재하는 다양한 값들의 분포는 일반적으로 정규분포를 따른다고 알려져 있습니다.
예를 들어 지구상에 존재하는 사람의 키에 따른 사람의 수를 그래프로 그려보면 평균키를 기준으로 좌우로 대칭인 곡선으로 나타나는데, 평균에서 멀어지면 급격하게 그 수가 감소하는 양상으로 나타납니다. 이는 비단 사람의 키 뿐만 아니라 사람의 수명이라든가, 어느 한 종류 군집의 특징적인 값들의 분포들이 정규분포를 따른다고 봐도 됩니다.
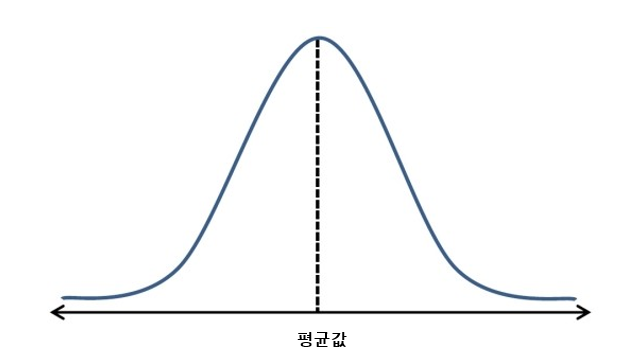
위 그림은 정규분포 곡선을 나타낸 것인데 정규분포곡선은 평균값을 기준으로 좌우 대칭인 종모양의 곡선이며, 이 곡선의 폭을 결정하는 것이 표준편차입니다. 표준편차는 값들의 분포가 평균값을 기준으로 얼마나 흩어져 있느냐를 말해주는 수치입니다.
그런데 모든 정규분포 곡선은 어떤 변환을 이용하면 평균값이 0, 표준편차가 1인 정규분포 곡선으로 바꿀 수 있습니다. 평균값이 0이고 표준편차가 1인 정규분포를 표준 정규분포라고 하며, 표준 정규분포로 변환하는 작업을 표준화(Standardization)라고 부릅니다.
이전 포스팅에서 사용한 아이리스 품종 데이터는 Iris-setosa, versicolor, verginica 각각 50개씩 총 150개입니다. 만약 이 데이터가 매우 많고 이들의 꽃잎 크기나 꽃받침 크기 분포를 그려보면 아마도 정규분포 곡선 모양이 될 것입니다.
일반적으로 데이터를 표준화하여 처리하게 되면 일관성이 생길뿐만 아니라 처리 성능까지 향상되는 결과를 가져올 수 있습니다. 어떤 데이터 집합 x가 있으면 표준화 된 데이터 X는 아래의 식에 의해 구해집니다.
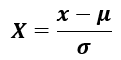
여기서 μ는 데이터 집합 x의 평균이며 σ는 데이터 집합 x의 표준편차입니다.
이제, 아이리스 품종 데이터를 표준화하여 아달라인을 적용하는 코드를 작성해 보겠습니다.
이전 포스팅의 adaline_iris.py 에서 if __name__ == '__main__' 을 아래와 같이 수정합니다.
std_adaline_iris.py

코드에서 아이리스 품종 데이터를 읽어들이는 부분도 동일합니다. 바뀐 부분만 살펴봅니다.
>>> X_std = np.copy(X)
X를 하나 복사하여 X_std로 둡니다.
>>> X_std[:, 0] = (X[:, 0] - X[:, 0].mean()) / X[:, 0].std()
>>> X_std[:, 1] = (X[:, 1] - X[:, 1].mean()) / X[:, 1].std()
이 부분이 바로 아이리스 데이터에서 꽃받침 길이와 꽃잎 길이의 표준화한 값을 X_std에 할당하는 부분입니다. numpy의 mean()은 numpy 배열에 있는 값들의 평균을, numpy의 std()는 numpy 배열에 있는 값들의 표준편차를 구해주는 함수입니다.
>>> adal = AdalineGD(eta=0.01, n_iter=15).fit(X_std, y)
learning rate을 0.01로, 반복회수를 15로 두고, X_std를 아달라인으로 머신러닝을 수행합니다.
>>> plt.plot(range(1, len(adal.cost_) + 1), adal.cost_, marker='o')
이전 포스팅에서는 y축의 값으로 log 스케일로 그렸지만, 지금은 그냥 그대로 그려봅니다.
코드를 수행하면 아래와 같은 그래프가 화면에 그려집니다.
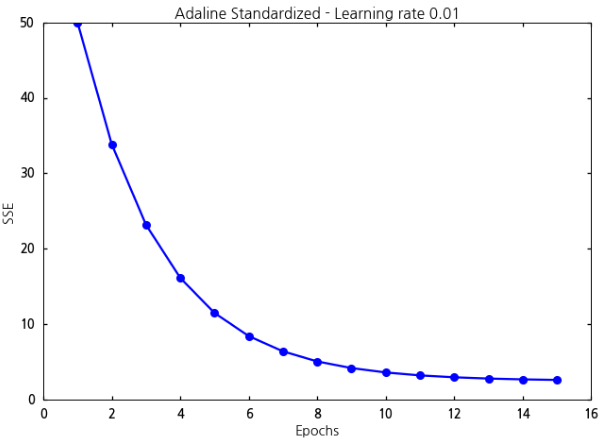
표준화를 이용하면 learning rate을 0.01로 두어도 비용함수의 값이 발산하지 않고 특정한 값에 수렴하고 있음을 알 수 있습니다.
여기까지 살펴본 아달라인 내용은 우리가 가지고 있는 모든 트레이닝 데이터를 한꺼번에 일괄 적용하여 학습을 수행하는 것이었습니다. 이를 배치 경사하강법(Batch Gradient Descent)을 이용한 아달라인이라 부릅니다. 배치 경사하강법을 이용하는 경우, 데이터의 개수가 매우 많아지고, 데이터 입력값의 종류도 다양하다면 머신러닝을 효율적으로 수행할 수 없고 시간도 매우 오래 걸리게 됩니다.
다음 포스팅에서는 이를 극복하기 위한 확률적 경사하강법(Stochastic Gradient Descent)을 이용하는 아달라인에 대해 다루도록 하겠습니다.
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [10편] scikit-learn을 이용해 퍼셉트론 머신러닝 수행하기 (0) | 2017.12.14 |
|---|---|
| [9편] 확률적 경사하강법을 적용한 아달라인 구현하기 (0) | 2017.12.14 |
| [7편] 단순 인공신경망 아달라인을 파이썬으로 구현하기 (0) | 2017.12.14 |
| [6편] 아달라인(Adaline)과 경사하강법(Gradient Descent) (0) | 2017.12.14 |
| [5편] 단순 인공신경망 퍼셉트론을 이용한 머신러닝 예시 (0) | 2017.12.14 |