우리가 실제로 다루는 데이터는 매우 큰 용량의 데이터가 대부분이며 , 이런 대규모 데이터에 대한 머신러닝을 이전 포스팅에서 설명한 배치 경사하강법을 이용한 아달라인을 그대로 활용하는 것은 성능면에서 문제가 있습니다.
이런 문제점을 극복하기 위한 방법으로 확률적 경사하강법(Stochastic Gradient Descent)을 적용한 아달라인이 있습니다.
이전 포스팅의 내용 중 아달라인의 가중치 업데이트 수식을 다시 상기해 봅니다.
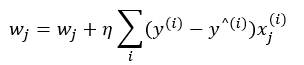
이 수식의 계산을 위해,
모든 트레이닝 데이터의 실제 결과값과 예측값의 차를 더한 값을 구해야 합니다.
그런데, 확률적 경사하강법에서는 아래와 같이 i번째 트레이닝 데이터에 대해서만 계산한 값을 이용합니다.
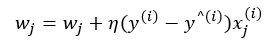
예를 들어 이해를 해봅니다.
100만개의 트레이닝 데이터가 있다고 가정합니다. 이를 배치 경사하강법으로 계산하려면 100만 x 100만 = 1조 번의 연산이 필요합니다. 이는 가중치를 업데이트 하는 식에서 y^(i)를 계산하기 위해 100만번의 덧셈을 해야하고, wj를 최종적으로 업데이트하기 위해 전체적으로 또 100만번의 덧셈을 수행해야 하기 때문입니다.
그런데, 확률적 경사하강법을 적용하게 되면 100만개의 모든 데이터를 활용하여 머신러닝을 수행하더라도 100만번의 연산만 필요합니다.
확률적 경사하강법을 이용하면 배치 경사하강법의 근사치로 계산되지만 가중치를 업데이트하는 시간이 빠르기 때문에 실제로는 비용함수의 수렴값에 더 빨리 도달하게 됩니다.
그리고, 확률적 경사하강법에서 비용함수의 값을 계산할 때 값이 순환되는 것을 피하기 위해 학습을 반복할 때마다 트레이닝 데이터의 순서를 랜덤하게 섞어서 수행하는 것이 좋습니다.
또한 크라우드 소싱(crowd sourcing)으로 머신러닝을 적용하는 웹에서도 확률적 경사하강법을 활용할 수 있습니다. 어떤 사람이 웹을 통해 데이터를 제공하고, 이 데이터에 대한 예측 결과를 그 사람에게 제시하여 피드백을 받아 재학습을 시키는 것이 바로 그 예입니다. 이에 대해서는 이후 포스팅에서 다루어 보도록 하겠습니다.
그러면 실제 코드를 보면서 이해해봅니다. 아래 코드를 작성하고 mylib 폴더에 adalinesgd.py로 저장합니다.
adalinesgd.py

이전 포스팅에서 소개한 표준화를 적용한 배치 아달라인의 AdalineGD 클래스와 여기서 구현한 AdalineSGD 클래스의 다른 부분만 설명합니다.
주요 변경 부분은 AdalineSGD 클래스의 fit() 함수의 로직과 _suffle() 함수가 추가된 것입니다.
>>> from numpy.random import seed
난수 발생기 초기화를 위해 numpy.random 모듈의 seed 함수를 임포트합니다.
>>> if random_state:
seed(random_state)
random_state의 값이 있으면 이 값으로 난수 발생기를 초기화합니다.
>>> if self.shuffle:
X, y = self._shuffle(X, y)
self.shuffle이 True로 설정되어 있으면, self._shuffle() 함수를 이용해 트레이닝 데이터 X와 y를 랜덤하게 섞습니다.
>>> cost = []
for xi, target in zip(X, y):
output = self.net_input(xi)
error = target - output
self.w_[1:] += self.eta * xi.dot(error)
self.w_[0] += self.eta * error
cost.append(0.5 * error**2)
avg_cost = sum(cost)/len(y)
self.cost_.append(avg_cost)
이 부분이 가중치를 업데이트하는 아래 식을 구현한 것입니다.

모든 트레이닝 데이터에 대해 비용함수의 값을 더해주고 for구문이 완료되면 평균값을 구하여 최종적인 비용함수 값으로 취합니다.
>>> def _shuffle(self, X, y):
r = np.random.permutation(len(y))
return X[r], y[r]
numpy.random.permutation은 주어진 인자 미만의 정수(0을 포함)로 순열을 만드는 함수입니다. 따라서 r의 값은 0~len(y) 미만까지 정수를 랜덤하게 섞은 결과이므로, X[r], y[r]은 X와 y를 랜덤하게 섞은 numpy 배열이 됩니다.
나머지 부분은 이전 포스팅의 코드와 동일합니다.
자, 그러면 아래의 파일을 작성하고 std_adalinesgd_iris.py로 저장합니다. 보면 알겠지만, AdalineSGD를 임포트한 것과 AdalineSGD 클래스에서 random_state=1 로 설정한 것 빼고는 이전 포스팅의 std_adaline_iris.py와 로직이 동일합니다.
std_adalinesgd_iris.py

이 코드를 실행하면 아래와 같은 결과가 나옵니다.
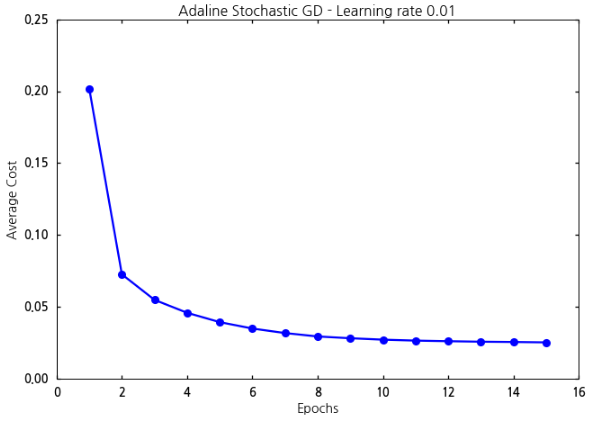
위 그래프를 보면, 비용함수의 값이 빠르게 줄어드는 것을 볼 수 있습니다. 이유는 한번의 반복문에서 가중치를 업데이트하는 빈도수가 더 많이 일어나기 때문이지요. 학습 반복회수가 늘어나면 결국 배치 경사하강법을 적용한 아달라인과 비슷해짐을 알 수 있습니다.
이로써 단순 인공신경망인 퍼셉트론과 아달라인에 대해 간략하게 살펴보았습니다.
물론 수식들이 나오고 내용도 이해하기 난해하지만 이제 어려운 부분들은 모두 끝났습니다. 앞으로 다루게 될 내용들은 이 개념들의 확장들이고, Scikit-Learn과 같은 라이브러리들은 사용자 친화적인 API들이므로 알고리즘 내부를 알 필요없이 다양한 머신러닝을 적용할 수 있습니다.
그렇더라도 퍼셉트론과 아달라인의 개념을 이해하게 되면 scikit-learn에서 제공하는 API의 활용도 더 편리하게 사용할 수 있고, 나아가 텐서플로우(TensorFlow)와 같은 오픈소스로 공개된 러닝 시스템에서도 여태까지 배운 개념이 적용되기도 합니다.
다음에는 머신러닝과 관련된 사용자 친화적인 scikit-learn API를 이용하여 머신러닝을 수행하는 다양한 알고리즘과 관련된 내용을 소개하도록 하겠습니다.
[출처] [9편] 확률적 경사하강법을 적용한 아달라인 구현하기|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [11편] scikit-learn 퍼셉트론의 유효성 확인 (0) | 2017.12.14 |
|---|---|
| [10편] scikit-learn을 이용해 퍼셉트론 머신러닝 수행하기 (0) | 2017.12.14 |
| [8편] 표준화를 이용하여 성능이 향상된 아달라인 구현하기 (0) | 2017.12.14 |
| [7편] 단순 인공신경망 아달라인을 파이썬으로 구현하기 (0) | 2017.12.14 |
| [6편] 아달라인(Adaline)과 경사하강법(Gradient Descent) (0) | 2017.12.14 |