[10편] 'scikit-learn을 이용해 퍼셉트론 머신러닝 수행하기'에서 scikit-learn의 퍼셉트론으로 아이리스 데이터의 70%를 가지고 머신러닝을 수행하고, 나머지 30%의 데이터로 머신러닝 결과를 테스트해보는 코드를 제시했습니다.
이번에는 70%의 데이터를 가지고 머신러닝을 수행한 결과가 실제 어떻게 데이터들을 분류하고 있는지 그래프로 나타내보고, 퍼셉트론 알고리즘의 유효성에 대해 고찰해보고자 합니다.
먼저, 아래의 코드를 작성하고 mylib 폴더에 plotdregion.py로 저장합니다.
plotdregion.py

이 코드는 plot_decision_region 함수의 인자 classifier로 주어진 퍼셉트론 분류기를 이용해 머신러닝을 수행한 결과가 트레이닝 데이터가 분포하고 있는 좌표계에서 어떻게 영역을 구분하는지 보여주기 위함입니다.
원리는 이렇습니다.
아이리스 트레이닝 데이터 X는 (꽃잎길이, 꽃잎너비) 2개의 값으로 되어 있으므로 x축의 값으로 꽃잎길이, y축의 값으로 꽃잎너비로 되어 있는 좌표계에 데이터를 표시할 수 있습니다.
그리고 좌표계를 바둑판으로 생각해보면, 좌표계에서 격자의 교차점도 아이리스 데이터 (꽃잎길이, 꽃잎너비)의 어떤 값이라고 생각할 수 있겠지요. 따라서 이 교차점의 좌표를 인자 classifier로 주어진 퍼셉트론 분류기로 머신러닝을 수행하여 나온 결과도 iris-setosa, iris-versicolor, iris-virginica를 의미하는 0, 1, 2 중 어느 한개의 값이 될 것이고, 0으로 되어 있는 영역은 빨간색, 1로 되어 있는 부분은 파란색, 2로 되어 있는 부분은 초록색으로 표시를 하여 머신러닝의 결과를 영역으로 표시하게 됩니다.
그럼 코드의 주요부분을 설명하겠습니다.
>>> markers = ('s', 'x', 'o', '^', 'v')
>>> colors = ('r', 'b', 'lightgreen', 'gray', 'cyan')
>>> cmap = ListedColormap(colors[:len(np.unique(y))])
markers는 matplotlib에서 정의한 점 표시 모양 5개를 튜플로 정의한 것이고, colors는 색상 5개를 튜플로 정의한 것입니다. ListedColormap은 인자로 주어진 색상을 그래프상에 표시하기 위한 객체입니다. numpy.unique(y)는 y에 있는 고유한 값을 작은 값 순으로 나열합니다. 예를 들어 [1, 0, 0, 2, 2, 0, 0, 1, 2]에는 고유한 값이 0, 1, 2밖에 없으므로 numpy.unique([1, 0, 0, 2, 2, 0, 0, 1, 2])는 [0, 1, 2]가 됩니다.
따라서 cmap = ListedColormap(colors[:3])이 되어 cmap에는 colors[0], colors[1], colors[2]가 매핑된 ListedColormap 객체가 됩니다. 이는 곧 빨간색, 파란색, 밝은 초록색이 매핑되는 겁니다.
>>> x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
>>> x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
>>> xx, yy = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
x1_min, x1_max는 트레이닝 데이터 X의 첫 번째값인 꽃잎길이의 최소값-1, 최대값+1 입니다.
마찬가지로 x2_min, x2_max는 트레이닝 데이터 X의 두 번째값인 꽃잎너비의 최소값-1, 최대값+1 입니다.
numpy.meshgrid()는 격자의 교차점 좌표를 편리하게 다룰 수 있도록 값을 리턴하는 함수입니다. 이해를 돕기 위해 아래의 코드를 봅니다.
>>> x = [0, 1, 2, 3, 4, 5]
>>> y = [0, 1, 2, 3, 4, 5]
>>> xx, yy = np.meshgrid(x, y)
>>> plt.plot(xx, yy, marker='.', color='k', linestyle='none')
이 코드는 x 범위 0~5까지 정수, y 범위 0~5까지 정수를 좌표로 하는 격자의 교차점의 위치를 찍어주는 코드입니다. 실행을 해보면 다음과 같은 결과가 나옵니다.
따라서 원래 코드에서 xx와 yy는 아이리스 트레이닝 데이터의 꽃잎길이, 꽃잎너비가 분포하는 좌표 격자 교차점을 resolution 간격으로 편리하게 만들어줄 수 있는 값을 가지고 있습니다.
>>> Z = classifier.predict(np.array([xx.ravel(), yy.ravel()]).T)
>>> Z = Z.reshape(xx.shape)
xx, yy를 ravel()을 이용해 1차원 배열로 한줄로 쭉 만든 후 전치행렬로 변환하여 퍼셉트론 분류기의 predict()의 인자로 입력하여 계산된 예측값을 Z로 둡니다. Z를 reshape()을 이용해 원래 배열 모양으로 복원합니다.
>>> plt.contourf(xx, yy, Z, alpha=0.5, cmap=cmap)
Z를 xx, yy가 축인 그래프상에 cmap을 이용해 등고선을 그립니다.
이후 부분은 아이리스 트레이닝 데이터를 matplotlib의 산점도 그리기를 이용해 그래프상에 찍어주는 겁니다. 특히 테스트 데이터는 강조하는 원으로 다시 표시 해주었습니다. matplotlib의 산점도 그리기 포스팅을 참고하면 됩니다.
이제 이전 포스팅의 skl_perceptron0.py의 if __name__ == '__main__':코드 맨 마지막에 아래의 코드를 추가해서 skl_perceptron.py로 저장합니다.

여기서 numpy.vstack(x, y)는 x배열과 y배열을 수직으로 쌓는 것이고, numpy.hstack(x, y)는 x배열과 y배열을 수평으로 쌓는 것입니다.
skl_perceptron.py

코드를 실행해보면 다음과 같은 결과를 볼 수 있습니다.
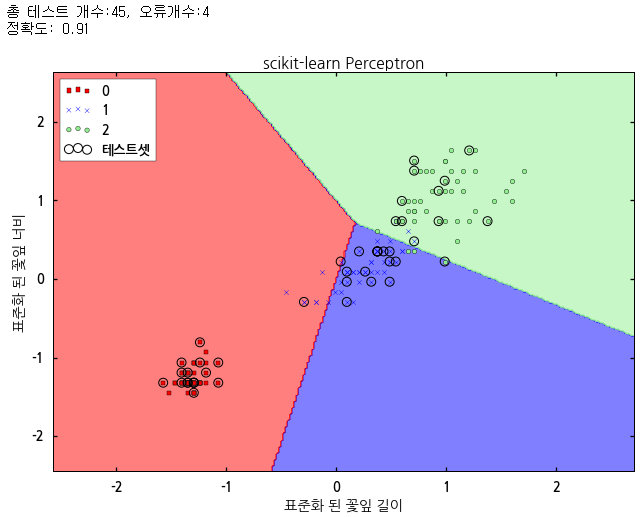
scikit-learn의 퍼셉트론 알고리즘의 아이리스 트레이닝 데이터를 이용해 머신러닝한 결과는 iris-setosa를 빨간색 영역으로, iris-versicolor를 파란색 영역으로, iris-virginica를 초록색 영역과 같이 분류합니다.
그런데 실제 데이터 분포를 보면 알 수 있듯이 x로 표시된 iris-versicolor가 빨간색 영역과 초록색 영역에서도 보이고, 초록색 원으로 표시된 것도 파란색 영역에서 찾을 수 있습니다. 따라서 퍼셉트론으로 아이리스 3가지 품종을 완벽하게 분류하지 못했다는 것을 알 수 있습니다. 테두리가 검정색인 원으로 표시한 것이 테스트 데이터입니다. 테스트 데이터 중 4개가 엉뚱한 영역에 있음을 알 수 있습니다.
퍼셉트론은 이와 같이 선형분리가 완벽하게 되지 않는 데이터로는 머신러닝을 제대로 수행할 수 없습니다.
[출처] [11편] scikit-learn 퍼셉트론의 유효성 확인|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [13편] scikit-learn SVM(Support Vector Machine) (0) | 2017.12.14 |
|---|---|
| [12편] scikit-learn 로지스틱 회귀 (0) | 2017.12.14 |
| [10편] scikit-learn을 이용해 퍼셉트론 머신러닝 수행하기 (0) | 2017.12.14 |
| [9편] 확률적 경사하강법을 적용한 아달라인 구현하기 (0) | 2017.12.14 |
| [8편] 표준화를 이용하여 성능이 향상된 아달라인 구현하기 (0) | 2017.12.14 |