로지스틱 회귀와 함께 분류를 위한 강력한 머신러닝 알고리즘으로 널리 사용되는 것이 바로 SVM(Support Vector Machine)입니다.
SVM은 퍼셉트론의 개념을 확장하여 적용한 알고리즘인데, 퍼셉트론이 분류 오류를 최소화하는 알고리즘인 반면 SVM은 margin을 최대가 되도록 하는 알고리즘입니다.
여기서 말하는 margin은 분류를 위한 경계선과 이 경계선에 가장 가까운 트레이닝 데이터 사이의 거리를 말합니다. 이 경계선에 가장 가까운 트레이닝 데이터들을 support vector라고 부릅니다. 아래의 그림을 보시죠~
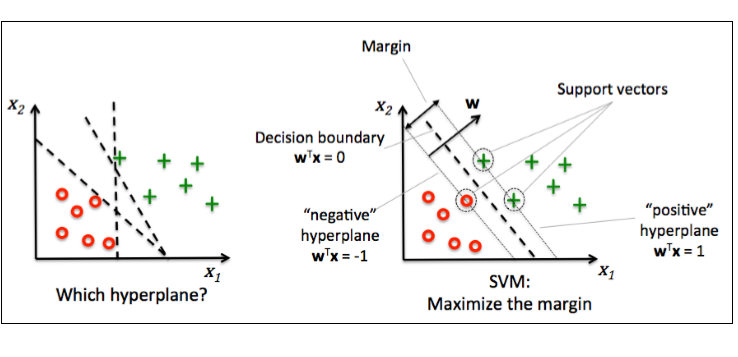
위의 왼쪽 그림을 보면 빨간색 원으로 표시된 집단과 초록색 더하기 기호로 표시된 집단을 분류하는 경계선은 다양하게 존재할 수 있습니다. SVM은 두 집단을 분류하는 경계선 중 support vector와의 거리가 가장 멀리 떨어져 있는 경계선을 찾아내는 알고리즘입니다.
이 알고리즘은 경계선에 가장 가까이 있는 support vector를 지나는 선과 거리가 최대가 되는 경계선을 구함으로써 그 목적을 달성하게 됩니다. 여기서 말한 선은 엄밀히 말하면 다차원 공간의 초평면(hyperplane)인데, 초평면의 개념을 설명하기도 복잡하고, 실제 초평면을 머릿속으로 상상하기도 힘들므로, 그냥 선으로 생각하고 사용해도 큰 무리가 없으므로 초평면을 선으로 생각하도록 하겠습니다.
SVM이 퍼셉트론의 개념으로부터 출발하고 확장된 것이므로 입력되는 트레이닝 데이터, 입력값과 곱해지는 가중치와 관련된 수식들이 등장하게 되는데, 중간단계의 복잡한 수식을 모두 스킵하면 결국 아래 수식의 최소 값을 구하는 것이 SVM의 핵심 원리가 됩니다.
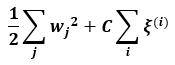
여기서 j는 트레이닝 데이터의 특성값의 개수가 그 범위가 되며, i는 트레이닝 데이터의 개수가 그 범위가 됩니다. C는 로지스틱 회귀에서 설명했던 정규화와 관련된 상수와 비슷한 개념이며 ξ는 여유 변수(slack variables)라고 부르는데, 이 변수는 분류 오류가 생기는 데이터에 적절한 패널티를 부여함으로써 비선형적으로 분리되는 모델을 완화시켜 최적화된 수렴값을 가지도록 하기 위한 선형 제약(linear contraints) 값입니다.
말이 좀 어렵지만 여기서 우리가 눈여겨 볼 부분이 C입니다. C값을 변화시키면 알고리즘이 결정하는 경계선이 달라집니다. 아래의 그림을 보면서 살포시 이해를 해봅니다.

위 그림과 같이 빨간색 원으로 이루어진 집단과 초록색 더하기 기호로 이루어진 집단이 분포하고 있을 때, C 값이 크면 왼쪽 그림처럼, C 값이 작으면 오른쪽 그림처럼 경계선이 결정됩니다. 왼쪽 그림에서 경계선은 오버피팅되었다고 볼 수 있고 오른쪽 그림에서 경계선은 최적화 되었다고 볼 수 있습니다.
대충 눈치를 챘겠지만 scikit-learn의 SVM을 적용할 때도 위에서 설명한 C값이 등장하게 됩니다.
이전 포스팅에서 구현했던 skl_logistic.py에서..
아래와 같이 SVM을 활용하기 위한 모듈을 추가합니다.
![]()
그리고 if __name__ == '__main__': 에서 로지스틱 회귀 알고리즘을 호출하는 부분을 아래의 내용으로 바꿉니다.
![]()
마지막으로 plot_decision_regions() 함수 호출부분에서 title 인자를 적절한 값으로 수정합니다.
수정된 코드를 skl_svm.py로 저장합니다.
skl_svm.py

추가된 코드에서 C 값으로 1.0이 할당되어 있습니다. 이 C값을 조정함으로써 언더피팅과 오버피팅을 조절하게 됩니다.
이제 코드를 수행해보면 아래와 같은 결과가 나옵니다.
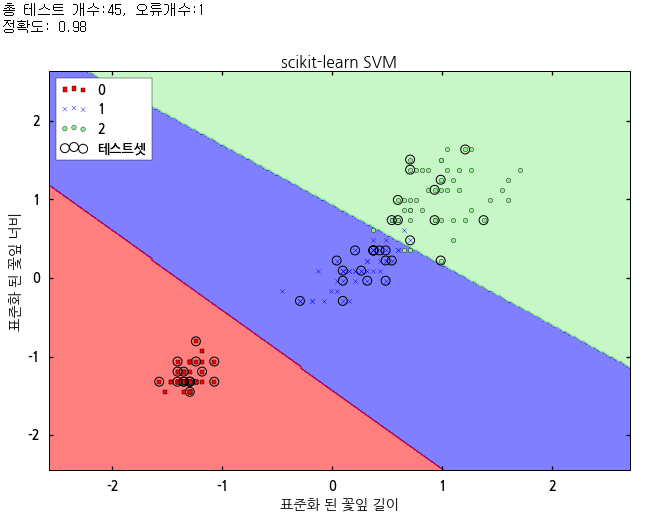
로지스틱 회귀가 구분한 경계선과 비교해보면 경계선과 support vector와의 거리가 동일하게 그려져 있음을 알 수 있습니다. 결과의 품질은 로지스틱 회귀와 동일하게 나오네요.
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [15편] scikit-learn SVM을 비선형 분리 모델에 적용하기 (0) | 2017.12.14 |
|---|---|
| [14편] scikit-learn의 확률적 경사하강법 버전 (0) | 2017.12.14 |
| [12편] scikit-learn 로지스틱 회귀 (0) | 2017.12.14 |
| [11편] scikit-learn 퍼셉트론의 유효성 확인 (0) | 2017.12.14 |
| [10편] scikit-learn을 이용해 퍼셉트론 머신러닝 수행하기 (0) | 2017.12.14 |