SVM이 머신러닝 실무자들에게 인기가 높은 이유 중 하나는 선형으로 분류가 되지 않는 모델에 대해서도 적용할 수 있다는 장점 때문입니다. 아래는 표준 정규분포로부터 200개의 샘플을 추출하고, 추출한 샘플을 100개씩 두 개의 그룹으로 나누어, 두 그룹에 속하는 멤버들이 0보다 큰지 아닌지에 대한 논리값을 순서대로 XOR 연산하여 나온 결과 중 True는 1로, False는 -1로 라벨링한 후, 이를 좌표에 표시하는 코드입니다.
코드를 실행하면 아래와 같이 선형 분리가 되지 않는 모양으로 빨간 사각형 그룹의 점과 파란 x 그룹들의 점들이 분포하고 있는 그림을 볼 수 있습니다.
위 그림처럼 분포되어 있는 빨간색 그룹과 파란색 그룹을 선형으로 분류하기가 쉽지 않습니다. 엄밀히 말하면 불가능합니다. 다시 말하면, 위 그림과 같은 비선형 모델은 여태 우리가 다루었던 퍼셉트론이나 로지스틱 회귀로는 머신러닝을 수행하기가 어렵습니다. 그렇다면 위 그림처럼 분포하고 있는 두 그룹을 어떻게 하면 선형으로 분류할 수 있을까요? 아래의 그림을 봅니다.
원리는 이렇습니다. 위의 왼쪽 그림은 2개의 값 (X1, X2)로 되어 있는 데이터 샘플의 분포를 2차원 평면에 그려 놓은 것입니다. 데이터의 분포는 원형으로 되어 있어서 선형 분리가 되지 않습니다. (X1, X2) 2차원으로 분포된 데이터를 변환 Φ를 통해 1차원 높은 3차원 (Z1, Z2, Z3) 형태의 분포로 변환하게 되면 오른쪽 위 그림처럼 빨간색 그룹과 파란색 그룹을 선형(엄밀하게 말하면 2차원 초평면으로 분리가 가능함)으로 분리할 수 있게 됩니다. 이렇게 선형으로 분리한 후 다시 2차원 (X1, X2) 분포로 변환시키면 오른쪽 아래 그림처럼 빨간색 그룹과 파란색 그룹을 회색 원 모양의 경계선으로 두 그룹을 분류하게 됩니다. 이런 원리에 입각하여 정리하면 또 다시 복잡한 수식이 등장하게 되는데, 이 부분을 다 스킵하면 결국 커널 함수(kernel function)라고 하는 것이 나옵니다. 커널 함수는 두 분류의 집단에 분포하고 있는 값들에 대한 벡터 내적 계산의 효율화를 위해 도입된 것으로 그 종류가 많은데, 이에 대해서 너무 깊게 알 필요는 없을 것 같습니다. 아무튼 커널 함수 중 가장 광범위하게 사용되는 것이 Radial Basic Function kernel(RBF 커널)입니다. RBF 커널과 관련된 식이 가우스 함수(Gaussian fucntion)와 동일한 형태여서 가우시안 커널(Gaussian kernel)로도 불립니다. 참고로, RBF 커널 k는 다음과 같은 다소 복잡한 수식으로 표현됩니다.
여기서 γ는 최적화를 위한 자유 파라미터(free parameter)라고 부릅니다. 따라서 RBF 커널을 적용하는 SVM은 정규화와 관련된 값 C와 자유 파라미터 γ의 값을 지정해주어야 합니다. 이에 대해서는 이 포스팅의 마지막 부분에서 다루어 보도록 합니다. 자, 그러면 scikit-learn이 제공하는 SVM으로 RBF 커널을 적용하여 위에서 서술한 비선형 분리 모델에 대해 머신러닝을 수행한 결과를 살펴보도록 합니다. 먼저, 'scikit-learn을 이용한 SVM' 포스팅에서 구현했던 skl_svm.py의 if __name__ == '__main__'에서 아이리스 데이터를 읽어 들이는 부분을 주석처리하고 이 아래 부분에 위에서 언급한 표준 정규분포부터 200개의 데이터를 추출하고 좌표에 표시하는 코드를 추가한 후, SVM 객체를 호출하는 부분과 plot_decision_region()을 호출하는 부분을 아래와 같이 수정합니다.
if __name__ == '__main__': 코드는 아래와 같습니다.
이 코드를 수행하면 아래와 비슷한 결과가 나옵니다. 참고로 200개 샘플 데이터는 프로그램을 수행할 때마다 달라지므로 본 포스팅에서 제시한 결과와 다를 수 있습니다.
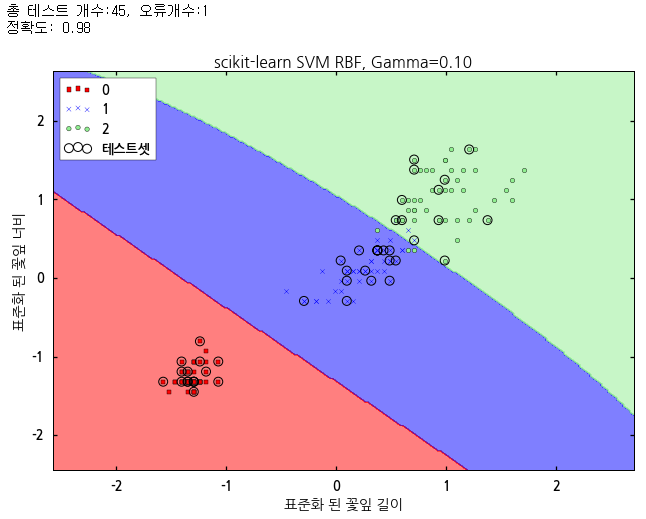
RBF 커널을 적용한 SVM으로 머신러닝을 수행하면 선형으로 분리가 되지 않는 데이터에 대해서도 훌륭하게 머신러닝을 수행하여 제대로 된 학습이 이루어질 수 있음을 알 수 있습니다. 그러면 아이리스 데이터에 rbf 커널을 가진 SVM을 적용하는데, γ 값을 달리해서 적용해 보겠습니다. 아이리스 데이터를 읽는 코드는 아래와 같습니다. skl_svm_rbf.py
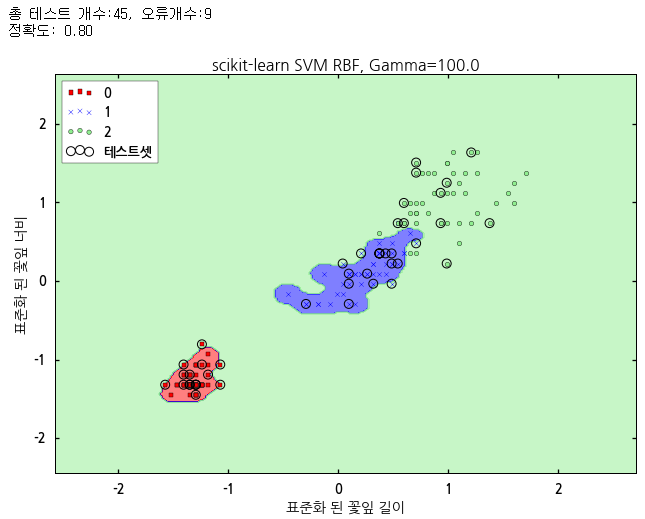
위 결과를 보면 γ 값이 작으면 트레이닝 데이터를 잘 분류하면서도 테스트 데이터에 대해서도 훌륭한 결과를 보여주지만, γ 값이 커지면 트레이닝 데이터에는 매우 잘 맞아 떨어지지만 테스트 데이터에 대해서는 결과가 썩 만족스럽게 나오지 않습니다. 따라서 이 결과는 오버피팅 된 결과이며 γ 값의 크기는 오버피팅과 관련이 되어 있음을 알 수 있습니다. 따라서 적절한 γ 값을 적용하여 오버피팅이나 언더피팅이 되지 않게 하는 것이 중요합니다. |



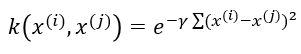




'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [17편] scikit-learn 의사결정트리 학습 (0) | 2017.12.14 |
|---|---|
| [16편] 의사결정트리 학습(Decision tree learning) (0) | 2017.12.14 |
| [14편] scikit-learn의 확률적 경사하강법 버전 (0) | 2017.12.14 |
| [13편] scikit-learn SVM(Support Vector Machine) (0) | 2017.12.14 |
| [12편] scikit-learn 로지스틱 회귀 (0) | 2017.12.14 |