우리는 한번쯤 스무고개라는 놀이를 해본 경험이 있을 겁니다. 상대방이 가지고 있는 답을 20번 이내의 질문으로 알아 맞추는 것이죠. 스무고개는 정답을 맞추는 사람이 질문을 잘 던져야 답을 제대로 빨리 찾아낼 수 있습니다.
스무고개와 비슷한 원리로, 의사결정트리 분류기(decison tree classifier)는 일련의 질문에 근거하여 주어진 데이터를 분류해주는 알고리즘입니다. 아래의 그림을 보시죠.
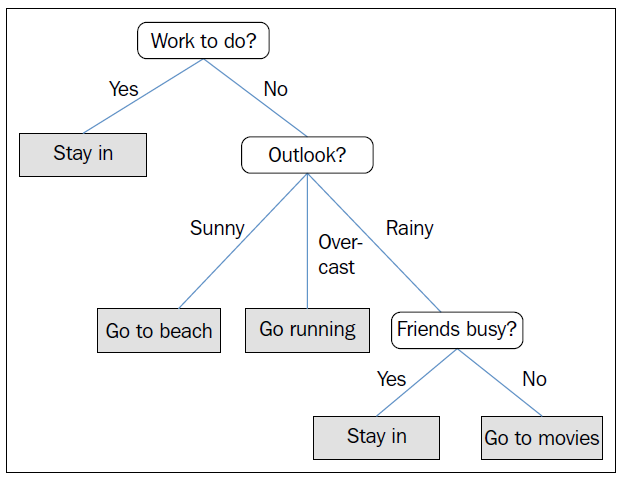
이 그림은 휴일에 무엇을 할지 결정하기 위한 의사결정트리의 한 예입니다. 흰색 둥근 사각형으로 되어 있는 부분이 의사결정을 위한 질문이고, 회색으로 채워진 사각형은 의사결정이 된 부분입니다.
이와 비슷한 원리로 꽃잎길이와 꽃잎너비와 같이 수치로 되어 있는 데이터에 대해서도 의사결정트리를 이용해 분류가 가능하겠지요. 예를 들면 아래 그림과 같이 3-depth 질문으로 분류가 가능한 질문을 만들 수가 있을 것입니다.
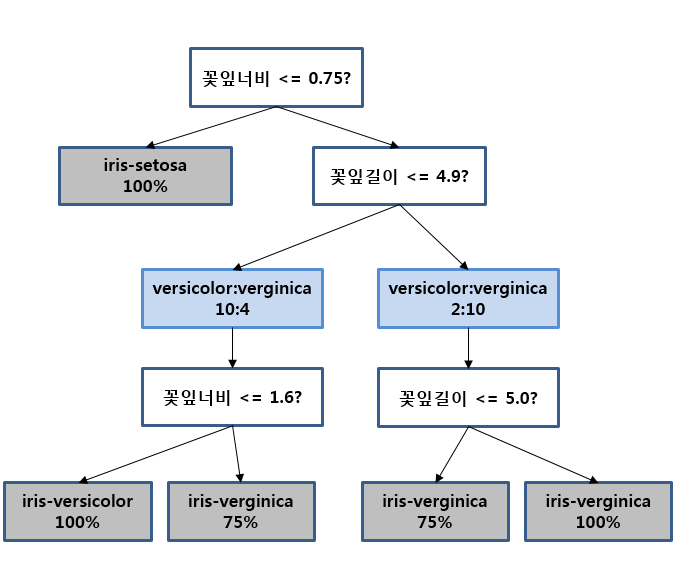
위 그림을 해설하면 이렇습니다.
첫 번째 질문인 꽃잎너비가 0.75 이하인 녀석들만 분류를 해봤더니 setosa로 모두 분류되었고, 그렇지 않은 녀석들 중에 꽃잎길이가 4.9 이하인 녀석들만 모아보니 versicolor와 verginica의 비율이 10:4로, 꽃잎길이가 4.9 초과하는 녀석들만 모아보니 versicolor와 verginica의 비율이 2:10으로 나오더라 입니다. 마찬가지로 각기 분류된 녀석들 각각에서 꽃잎너비가 1.6이하인지, 꽃잎길이가 5.0 이하인지로 질문을 던져서 각각 분류해보니 최종적으로 맨 아래의 회색 사각형처럼 분류되더라..가 결론입니다.
만약 이 질문의 깊이가 더 깊어지면 보다 더 정확한 값들로 분류가 되겠지만, 이전 포스팅에서 말한 오버피팅이 되버리는 문제가 발생할 수 있으므로 적절한 선에서 질문을 잘라줘야 합니다.
그렇다면 이런 일련의 질문들을 어떻게 만들 수 있을까요...?
의사결정트리 학습은 트레이닝 데이터를 이용해 데이터를 최적으로 분류해주는 질문들을 학습하는 머신러닝입니다.
의사결정트리 학습에 대한 개념은 이것이 다입니다. 이제 의사결정트리에서 질문들을 만들어내기 위한 메커니즘에 대해 가볍게 살펴봅니다. 말은 가볍게라고 썼지만 결코 가볍지 않습니다.
의사결정트리 학습에서 각 노드에서 분기하기 위한 최적의 질문은 정보이득(Information Gain)이라는 값이 최대가 되도록 만들어주는 것이 핵심입니다. 어느 특정 노드에서 m개의 자식 노드로 분기되는 경우 정보이득은 아래의 식으로 정의합니다.
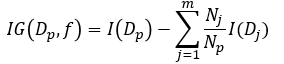
여기서, f는 분기를 시키기 위한 트레이닝 데이터의 특성값(예를 들어, 꽃잎 길이 또는 꽃잎 너비)이며 Dp는 부모노드에 존재하는 데이터 세트, Dj는 j번째 자식노드에 존재하는 데이터 세트입니다. I(Dp)는 Dp의 데이터 불순도(impurity), I(Dj)는 Dj의 데이터 불순도를 의미합니다. 그리고 Np와 Nj는 Dp의 데이터 개수와 Dj의 데이터의 개수입니다.
여기서 데이터 불순도란 데이터가 제대로 분류되지 않고 섞여 있는 정도를 말하는데, 이에 대해서는 아래에서 좀 더 자세히 다루도록 하겠습니다.
아무튼 정보이득 IG는 자식노드의 데이터 불순도가 작으면 작을수록 커지게 됩니다.
계산을 단순화하기 위해 보통 의사결정트리에서 분기되는 자식 노드의 개수는 2개로 하는데, 이를 이진 의사결정트리(Binary decision tree)라고 부릅니다. 특정 노드에서 분기되는 2개의 자식노드를 각각 L과 R첨자를 나타내서 표현하여 위 식을 단순화하면 아래와 같은 식이 됩니다.
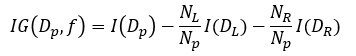
아까 위에서 데이터 불순도를 언급했는데, 이진 의사결정트리에서 데이터 불순도를 측정하는 방법은 아래와 같이 3가지가 있습니다.
- 지니 인덱스(Gini Index)
- 엔트로피(entropy)
- 분류오류(classification error)
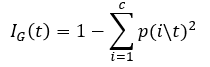

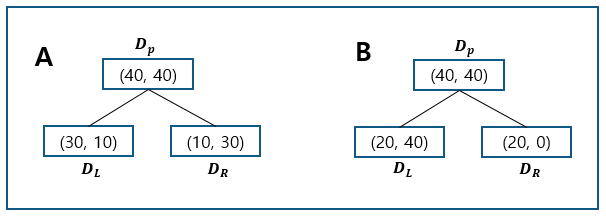
위 그림과 같이 80개의 데이터가 40개씩 두 종류의 데이터로 분류되어 있고, 이를 (40, 40)과 같이 표현해 봅니다. 의사결정트리 A는 (40, 40)을 (30, 10), (10, 30)으로 분리하는 것이고, 의사결정트리 B는 (40, 40)을 (20, 40), (20, 0)으로 분리하는 것입니다.
여기서 데이터 불순도 계산 방법으로 분류오류를 적용하고, 최종적으로 A, B의 정보이득을 각각 계산해보도록 하겠습니다.
Dp의 데이터 불순도를 계산하려면 p(i\t)를 계산해야 하겠죠. p(i\t)는 노드 t에 존재하는 데이터 중, i부류에 속하는 데이터 비율이라고 했습니다. 위의 예에서 2가지 부류만 있으므로 편의상 제1부류, 제2부류라 하겠습니다. (40, 40)은 80개의 데이터 중 40개는 제1부류에, 나머지 40개는 제2부류에 속하는 멤버이므로 p(1\t), p(2\t)는 모두 0.5로 같습니다. 따라서 위에서 서술한 분류오류에 의한 데이터 불순도 역시 제1부류, 제2부류 모두 0.5로 같습니다.
마찬가지 방법으로 DL, DR의 데이터 불순도를 계산할 수 있겠지요. 계산식을 적어보면 다음과 같습니다.
의사결정트리 A의 경우 불순도 I(Dp), I(DL), I(DR) 및 정보이득 IG 계산
![]()
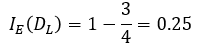

따라서 정보이득 계산식에 의한 정보이득 값은 다음과 같습니다.
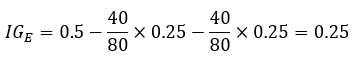
의사결정트리 B의 경우 불순도 I(Dp), I(DL), I(DR) 및 정보이득 IG 계산
![]()
![]()
![]()
따라서 정보이득계산 식에 의한 정보이득 값은 다음과 같습니다.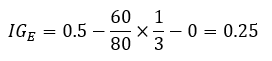
이제 정보이득을 계산하는 원리는 대충 이해했겠지요.
비슷한 방법으로 데이터 불순도를 계산하는 방법으로 지니 인덱스, 엔트로피를 적용하였을 경우 A, B에서 정보이득은 다음과 같이 계산됩니다.
지니 인덱스로 계산한 경우
- A에서 정보이득 : 0.125
- B에서 정보이득 : 약 0.16
- A에서 정보이득 : 0.19
- B에서 정보이득 : 0.31
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [18편] scikit-learn 랜덤 포레스트(Random Forest) (0) | 2017.12.14 |
|---|---|
| [17편] scikit-learn 의사결정트리 학습 (0) | 2017.12.14 |
| [15편] scikit-learn SVM을 비선형 분리 모델에 적용하기 (0) | 2017.12.14 |
| [14편] scikit-learn의 확률적 경사하강법 버전 (0) | 2017.12.14 |
| [13편] scikit-learn SVM(Support Vector Machine) (0) | 2017.12.14 |