바로 앞 포스팅 '의사결정트리 학습'에서 언급했던 불순도를 계산하는 3가지 방법은 다음과 같습니다.
- 지니 인덱스
- 엔트로피
- 분류오류
이 3가지 불순도 계산 방법은 각각 특성을 가지고 있습니다. 아래와 같은 상황을 생각해봅니다.
어떤 데이터 세트에 여러가지 데이터가 섞여 있다고 가정합니다. 이 데이터 세트에 특정 부류(예를 들면 다각형들이 모여있는 집단에서 원으로 분류되는 부류와 같이..)에 속하는 멤버가 차지하는 비율을 가지고 불순도를 계산해 보도록 합니다. 비율은 0~100%의 범위를 가지지만 이를 0~1사이의 값으로 조정하더라도 본질적으로 차이가 없다는 것은 잘 알고 있지요?
이 비율이 0에서 1로 변해갈때 3가지 불순도 계산 방법의 추이는 어떻게 되는지 그래프로 그려보면 아래 그림과 같습니다.

이 그래프에서 엔트로피(scaled)로 되어 있는 회색 실선으로 나타낸 곡선은 원래 엔트로피의 0.5배한 그래프입니다. 그래프를 보면 3가지 불순도 계산 방법 모두 0 또는 1에 가까와질 수록 불순도가 낮아지고, 0.5일 때 불순도가 가장 높게 나옵니다. 이는 곧, 데이트 세트에 여러가지 부류에 속하는 데이터가 섞여 있는 경우, 특정 부류에 속하는 멤버입장에서 고려할 때 그 멤버가 차지하는 비율이 0에 가까와지거나 1에 가까와 질 때 가장 순도가 높고, 0.5일 때 불순도가 가장 높다..라고 해석 됩니다.
분류오류의 경우 멤버가 차지하는 비율이 0.5까지 높아짐에 따라 선형적으로 불순도가 증가하는 것에 반해, 지니 인덱스와 엔트로피는 멤버가 차지하는 비율이 증가함에 따라 불순도가 빠르게 증가하다가 0.5 근방에서 최대를 보이는 패턴을 갖습니다. 특히 엔트로피의 경우가 불순도가 더 급격하게 증가하는 경향을 보입니다.
3가지 불순도의 특성에 대해서는 이 정도에서 마무리 하도록 하겠습니다.
이제 scikit-learn에서 제공하는 의사결정트리 학습 API를 이용해서 아이리스 데이터에 적용해보도록 합니다.
여태까지 우리가 작성한 코드에 아래의 모듈을 추가합니다.
![]()
그리고 if __name__ == '__main__'에서 분류기 알고리즘 적용 부분에 아래의 코드로 수정합니다.
![]()
이 코드에서 DecisionTreeClassifier()가 scikit-learn이 제공하는 의사결정트리 학습 API이며 criterion='entropy'는 엔트로피를 불순도 계산 방법으로 적용한다는 의미입니다. scikit-learn의 DecisionTreeClassifier()가 지원하는 불순도 계산 방법은 지니 인덱스와 엔트로피입니다. 지니 인덱스를 적용하고자 하면 criterion = 'gini'로 하면 됩니다.
마지막으로 plot_decision_region() 함수의 title 인자로 적절한 값을 적용합니다.
수정된 코드를 skl_tree.py로 저장합니다.
skl_tree.py의 if __name__ == '__main__'

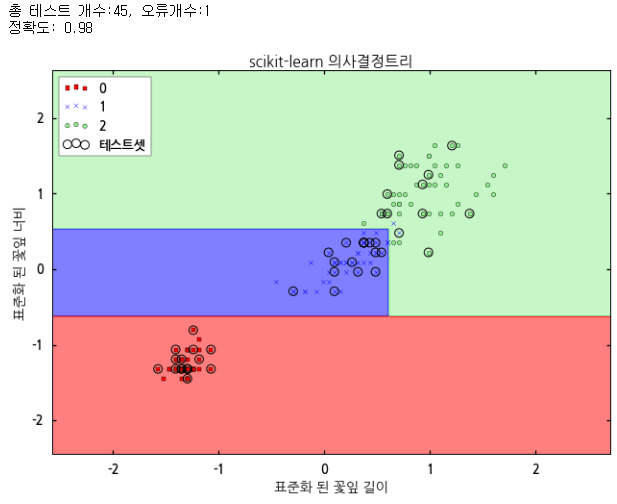
skl_tree.py를 실행하면 다음과 같은 결과가 나옵니다.
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [19편] scikit-learn kNN(k-Nearest Neighbors) (0) | 2017.12.14 |
|---|---|
| [18편] scikit-learn 랜덤 포레스트(Random Forest) (0) | 2017.12.14 |
| [16편] 의사결정트리 학습(Decision tree learning) (0) | 2017.12.14 |
| [15편] scikit-learn SVM을 비선형 분리 모델에 적용하기 (0) | 2017.12.14 |
| [14편] scikit-learn의 확률적 경사하강법 버전 (0) | 2017.12.14 |