로지스틱 회귀(logistic regression)는 선형 또는 바이너리 분류 문제를 위한 단순하면서도 보다 강력한 분류 알고리즘입니다. 로지스틱 회귀에서 등장하는 회귀(regression)는 통계에서 말하는 회귀와는 별로 관계가 없는, 머신러닝의 분류와 관련된 알고리즘 이름으로 생각하면 됩니다.
로지스틱 회귀는 선형 분리 모델에서 훌륭하게 동작하며, 실제로 가장 많이 사용되는 분류 알고리즘 중 하나입니다. 머리가 좀 아프더라도 로지스틱 회귀를 살포시 이해하도록 해봅니다.
로지스틱 회귀를 이해하기 위한 첫 단계는 다음과 같은 약간의 확률과 관련된 지식이 필요합니다.
영어로 odds는 어떤 일이 일어날 승산을 말합니다. 특정 사건의 승산률 odds ratio는 다음과 같이 정의됩니다.

여기서 p는 어떤 특정 사건이 발생할 확률입니다. 즉 odds ratio는 어떤 특정 사건이 일어날 확률과 그 사건이 일어나지 않을 확률의 비로 정의됩니다.
다시 우리의 머신러닝 주제로 돌아갑니다. 우리가 머신러닝을 수행해서 얻은 학습 결과를 이용해 어떤 값에 대한 예측값이 실제 결과값과 동일하게 나올 확률을 p라고 하면 이 머신러닝의 odds ratio 역시 위와 같이 정의됩니다.
이제, odds ratio의 로그값을 함수값으로 가지는 함수를 정의해 봅니다.
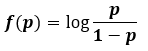
p는 0과 1사이의 수이고, f(p)의 범위는 실수 전체가 됩니다. 우리가 이전 포스팅에서 다루었던 순입력 함수의 리턴값을 다시 한번 상기해 봅니다. 순입력 함수의 리턴값을 z로 표기하면 아래와 같습니다.

z는 w의 값에 따라 실수 전체에 대해 매핑되는 값이며, z의 값에 따라 입력된 트레이닝 데이터 X가 어떤 집단에 속하는지 아닌지 결정하게 되는 값입니다. 따라서 위에서 정의한 f(p)의 값을 z로 매핑할 수 있습니다.
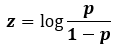
여기서, p를 z에 관한 식으로 나타내면 아래와 같은 식이 됩니다. (고등학교때 배웠던 지수와 로그의 관계식을 알면 됩니다!)
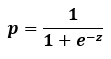
이 확률 p를 z에 관한 함수로 표현하여 다음과 같이 나타냅니다.
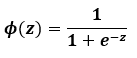
이 함수를 그래프로 그려보면 다음과 같은 s자 형태의 곡선으로 나타납니다. 이런 이유로 이 함수를 sigmoid 함수라고 부릅니다.
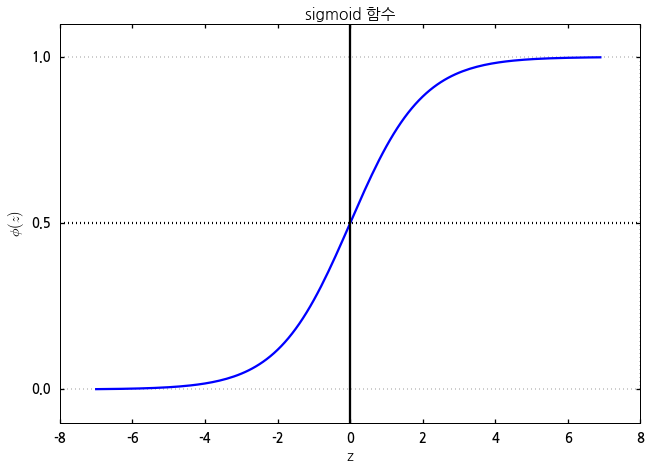
로지스틱 회귀에서는 순입력 함수의 리턴값에 대해 가중치 업데이트 여부를 결정하는 활성 함수로 이 sigmoid 함수를 이용합니다.

즉 로지스틱 회귀는 순입력 함수의 리턴값을 sigmoid 함수에 대입하여 그 결과값을 가지고 가중치 업데이트를 할지 말지를 결정하는 것이 핵심입니다. sigmoid 함수의 리턴값은 곧 입력한 트레이닝 데이터가 특정 클래스에 속할 확률이 되므로, 로지스틱 회귀는 입력되는 트레이닝 데이터의 특정 클래스에 포함될 예측 확률에 따라 머신러닝을 수행하는 알고리즘임을 알 수 있습니다.
우리는 실생활에서 예측되는 부류(class) 그 자체 뿐만 아니라 그 부류에 속할 확률이 유용할 때가 많습니다. 일기예보에서 내일 비가 올 확률을 예측하는 것이라던지, 환자의 증상을 보고 그 환자가 특정 질병에 걸렸을 확률을 계산하는 것 등이 그 예입니다. 로지스틱 회귀는 실제로 의학 분야에서 광범위하게 활용되고 있기도 합니다.
로지스틱 회귀에서 활용되는 비용함수 J(w)와 가중치 업데이트 식은 퍼셉트론의 그것과 동일한 원리이며, 이에 대한 구체적인 내용은 본 포스팅의 목적에 어울리지 않게 너무 어려워서 패스하도록 합니다.
그러면 아이리스 데이터를 가지고 scikit-learn을 이용하여 로지스틱 회귀 알고리즘으로 머신러닝을 수행하는 코드를 봅니다.
이전 포스팅에서 설명한 skl_perceptron.py 코드에서 아래의 내용을 반영합니다.
필요 모듈 임포트하는 부분에서 아래 코드를 추가합니다.
![]()
if __name__ == '__main__': 에서 아래 코드를 찾습니다.
![]()
이 부분을 아래의 코드로 수정합니다.
![]()
마지막으로 plot_decision_regions() 함수 호출부분에서 title 인자를 적절하게 변경합니다.
이렇게 작성된 코드를 skl_logistic.py로 저장합니다.
skl_logistic.py

결국 scikit-learn의 퍼셉트론 코드와 로지스틱 회귀 코드는 알고리즘을 선택하고 적용하는 부분만 다릅니다.
그런데 LogisticRegression()을 보면 C=1000.0 이라는 생소한 부분이 보입니다. 이 값을 이해하려면 머신러닝에 있어 공통적으로 나타나는 문제인 오버피팅과 이를 해결하기 위한 정규화라는 개념을 알아야 합니다.
오버피팅(Overfitting)이란 말 그대로 너무 잘 맞아 떨어진다는 뜻이며, 이는 머신러닝을 위해 입력된 값에만 너무 잘 맞아 떨어지도록 계산을 해서 입력에 사용된 트레이닝 데이터 이외의 데이터들에 대해서는 잘 맞아 떨어지지 않는 경우가 발생하게 되어 미지의 데이터에 대해 그 결과를 예측하기 위한 머신러닝의 결과로는 바람직하지 않습니다.
아래의 그림을 보면 오버피팅을 이해할 수 있습니다. 물론 이 그림은 'Python Machine Learning'에서 가져온 것입니다.
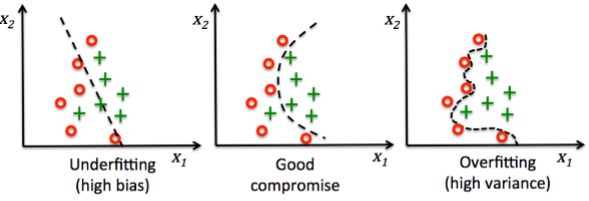
위 그림에서 2번째 그림처럼 최적의 조건을 찾기 위해 사용되는 것이 정규화(regularization)라는 기법인데, 정규화를 통해 데이터 모델의 복잡성을 튜닝하여 언더피팅과 오버피팅의 트레이드 오프(trade-off)를 찾아내는 것입니다. 로지스틱 회귀에서 사용되는 정규화 기법은 가장 일반적으로 사용되는 L2 정규화인데, 위의 코드에서 생소했던 C=1000.0 부분이 L2 정규화와 관련된 인자로 이해하시면 됩니다.
L2 정규화는 로지스틱 회귀의 비용함수 J(w)를 아래와 같은 식으로 변형하여 동작합니다.

여기서 λ를 정규화 파라미터라고 부르며, C값은 λ의 역수로 정의합니다.

따라서 C값을 감소시키면 λ가 커지게 되며, 이는 정규화를 강하게 한다는 의미입니다. 아무튼 생소했던 C값이 무엇인지 대충은 알았으므로 이쯤에서 넘어 가도록 하겠습니다.
코드를 수행하면 다음과 같은 결과가 나옵니다.

결과를 보면 scikit-learn 퍼셉트론에 비해 로지스틱 회귀가 아이리스 데이터에 대해 더 정확도 높게 분류하고 있고, 머신러닝에 의해 분리된 영역이 퍼셉트론의 결과와 다르다는 것을 알 수 있습니다.
이것으로 로지스틱 회귀에 대한 내용은 마무리하겠습니다.
[출처] [12편] scikit-learn 로지스틱 회귀|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [14편] scikit-learn의 확률적 경사하강법 버전 (0) | 2017.12.14 |
|---|---|
| [13편] scikit-learn SVM(Support Vector Machine) (0) | 2017.12.14 |
| [11편] scikit-learn 퍼셉트론의 유효성 확인 (0) | 2017.12.14 |
| [10편] scikit-learn을 이용해 퍼셉트론 머신러닝 수행하기 (0) | 2017.12.14 |
| [9편] 확률적 경사하강법을 적용한 아달라인 구현하기 (0) | 2017.12.14 |