분석하고자 하는 데이터의 설명변수와 응답변수가 선형적인 관계가 아니라 곡선 형태로 되어 있는 경우, 선형 회귀 모델을 이용해 계산하게 되면 오차가 크게 나타날 것입니다.
만약 분석하고자 하는 데이터 분포가 2차원 곡선 형태로 되어 있으면 2차원 곡선으로, 3차원 곡선 형태로 되어 있으면 3차원 곡선으로 접근하는 것이 오차가 작겠지요.
아래와 같은 데이터 분포를 봅니다.
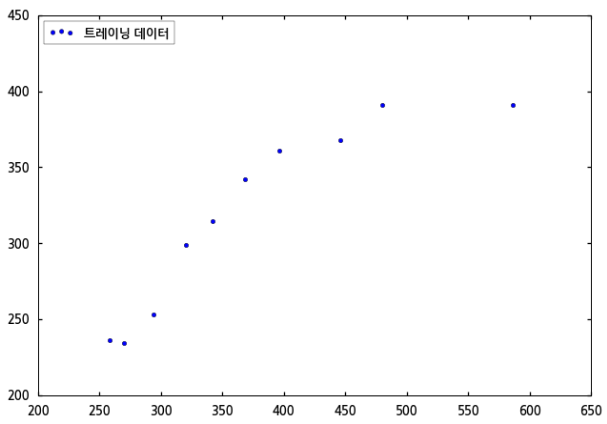
위 그래프와 같은 데이터 분포는 위로 볼록한 2차원 곡선 형태로 되어 있다고 말할 수 있겠지요. 이런 경우, 우리가 구하고자 하는 회귀 모델 식은 아래의 식과 같이 가정할 수 있습니다.
![]()
동일한 개념으로 일반적인 곡선에 대해 회귀 모델을 가정하면 아래와 같이 표현할 수 있겠습니다.
![]()
따라서 위 그래프는 d=2 로 두고 회귀 모델을 구하는 것이라고 보면 됩니다.
회귀 모델식을 위와 같이 다차원 다항식으로 두고 회귀 분석을 수행하는 것을 다항 회귀(Polynomial Regression)라 합니다. 그런데 이 다항 회귀도 결국 다중 회귀식의 일종임을 알 수 있습니다. 앞서 말했듯이 다중 회귀는 설명 변수가 여러 개 있는 식에서 설명 변수 계수를 구하는 것이라 했습니다. 아래의 치환식을 생각해봅니다.
![]()
이 치환식을 적용하면 위에서 보인 다항 회귀 모델식은 아래와 같은 식으로 표현할 수 있습니다.
![]()
즉, 다항 회귀 모델은 다중 회귀 모델로 계산될 수 있다는 말입니다.
코드를 보면서 이해해 보도록 합니다. 먼저 아래와 같이 필요한 모듈을 임포트합니다.
위 코드 아래에 다음 코드를 추가합니다.
skl_polyregression.py

이 코드에서 X와 y는 이 포스팅 처음에 보인 그래프에서 데이터의 분포와 같은 값을 가집니다. 다항 회귀를 적용하려면 아래와 같은 순서로 로직을 구현합니다.
- 다항 회귀를 위한 필요한 차수만큼 항을 추가하기 위해 PolynomialFeatures() 객체를 생성합니다.
- 트레이닝 데이터 X를 PolynomialFeatures.fit_transform(X)로 변형합니다.
- LinearRegression.fit()에 2단계의 결과를 적용하여 회귀 모델을 구합니다.
그러면 코드를 보시죠~
>>> lr = LinearRegression()
>>> pr = LinearRegression()
lr은 단순 선형 회귀 모델로 계산하기 위한 것이고, pr은 다항 회귀를 적용하여 다중 회귀 모델로 계산하기 위한 것입니다. 따라서 pr이 우리가 주목해야 할 부분입니다.
>>> quadratic = PolynomialFeatures(degree=2)
다항 회귀를 위해 2차항을 적용합니다.
>>> X_quad = quadratic.fit_transform(X)
트레이닝 데이터 X를 2차항이 적용된 다항 회귀 모델로 변형합니다.
>>> pr.fit(X_quad, y)
다항 회귀를 위해 변형된 트레이닝 데이터 X_quad를 이용해 회귀 모델 pr을 계산합니다.
>>> y_quad_fit = pr.predict(quadratic.fit_transform(X_fit))
계산된 회귀 모델로 좌표값 X_fit의 예측값을 계산합니다. 계산한 (X_fit, y_quad_fit)을 그래프에 그려주면 회귀 모델 그래프가 그려집니다.
나머지 코드는 회귀 모델 그래프를 화면에 그려주고, 단순 선형 모델의 MSE와 결정 계수값, 다항 회귀 모델을 적용하여 계산한 회귀 모델의 MSE와 결정 계수값을 보여주는 코드입니다.
코드를 실행하면 다음과 같은 결과가 나옵니다.
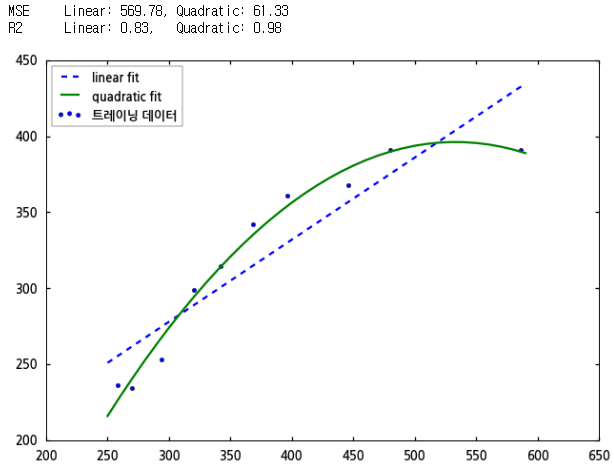
그래프를 보면, 단순 회귀 모델로 계산된 것은 점선으로 된 직선이고, 다항 회귀를 적용한 회귀 모델은 초록색 곡선입니다. 또한 단순 회귀 모델에 의해 계산된 MSE는 569.78로 다소 크지만 다항 회귀를 적용한 다중 회귀 모델의 MSE는 61.33으로 많이 줄어들었음을 알 수 있습니다. 또한 결정 계수의 값도 0.83에서 0.98로 1에 더욱 가까와져 적합도가 더욱 좋아졌습니다.
그러면 여태 다루었던 주택 정보에 다항 회귀를 적용해 보도록 하겠습니다. '회귀 분석 - 준비하기'에서 보인 페어플롯을 다시 보도록 합니다.
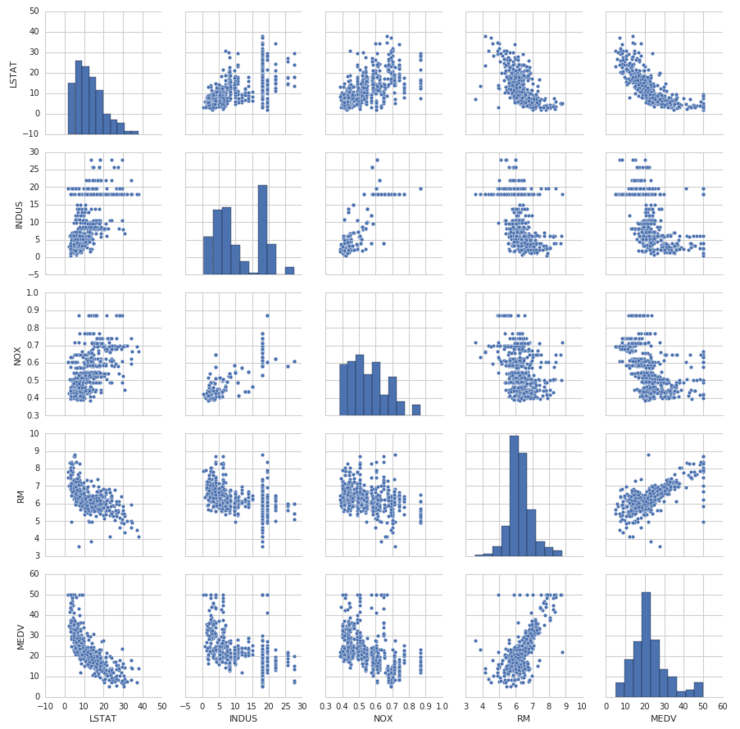
페어플롯에서 MEDV-LSTAT에 해당하는 그래프를 보면 데이터가 2차원 곡선 형태 비스므리하게 분포되어 있음을 알 수 있습니다.
skl_polyregression.py를 아래의 코드로 수정합니다.
skl_polyregression1.py

이 코드는 3차 다항 회귀 모델을 적용하는 부분이 추가된 것 말고는 전체적인 로직이 skl_polyregression.py와 동일합니다. 코드를 실행하면 아래와 같은 결과가 나옵니다.
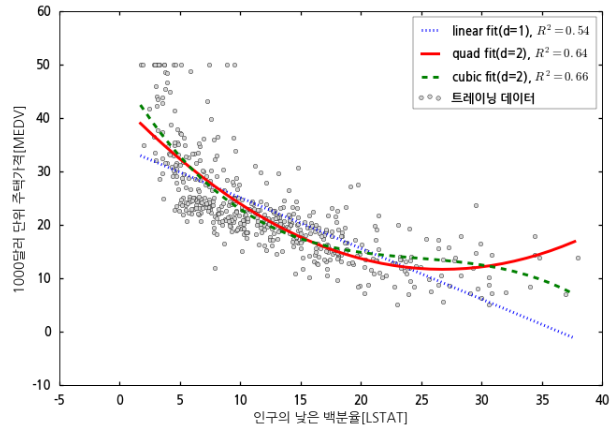
각 회귀 모델의 결정 계수를 보면 결과가 썩 훌륭하지는 못합니다. 모든 비선형 모델에 다항 회귀 모델을 적용하는 것이 팔방미인은 아닙니다. 가끔은 데이터를 다른 식으로 변형해서 단순 회귀 모델로 계산할 때 더 좋은 결과를 보일 때도 있습니다. 이는 데이터를 바라보고 분석하는 사용자의 직관이나 경험이 중요하다는 것을 말해 줍니다.
MEDV-LSTAT 데이터에서, MEDV는 로그 값을 취하고, LSTAT은 제곱근 값을 취한 후, 단순 회귀 모델로 계산해보는 코드는 아래와 같습니다.

skl_polyregression1.py의 #그래프 그리기 부분을 삭제하고 이 코드를 추가합니다. 수정한 코드를 실행하면 다음과 같은 결과가 나옵니다.
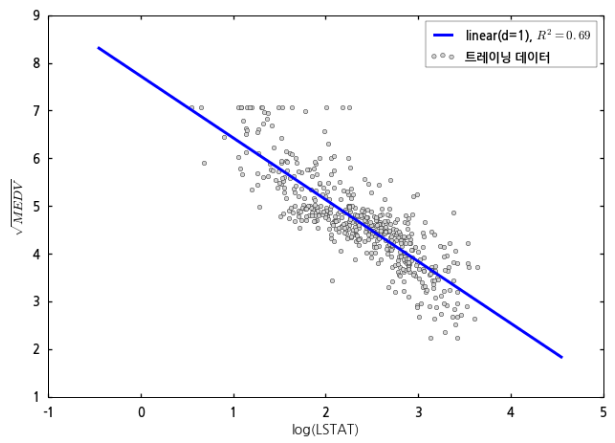
결정 계수 값이 0.69로 이전의 결과보다 더 나아졌다는 것을 알 수 있습니다.
이는 데이터의 분포 형태에 따라 단순 회귀 모델로 계산할지, 다항 회귀를 적용한 다중 회귀 모델로 계산해야 할지 결정하는 것도 중요하지만, 데이터를 바라보고 직관적으로 해석하는 사용자의 경험이나 능력도 중요하다는 것을 말해줍니다.
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [30편] k-means 클러스터링 (0) | 2017.12.14 |
|---|---|
| [29편] 회귀 분석 - 의사결정 트리 회귀와 랜덤 포레스트 회귀 (0) | 2017.12.14 |
| [27편] 회귀 분석 - 정규화 기법을 이용한 회귀 모델 (0) | 2017.12.14 |
| [26편] 회귀 분석 - 회귀 모델의 적합도 측정 (0) | 2017.12.14 |
| [25편] 회귀 분석 - RANSAC (0) | 2017.12.14 |