우리는 의사결정트리 학습과 랜덤 포레스트를 이용해 데이터를 학습하고 분류하는 것에 대해 공부한 적이 있습니다. 기억나지 않는다면 아래의 링크를 살포시 눌러서 가볍게 훝어보고 옵니다.
회귀 분석에 있어서도 의사결정트리를 이용하거나 랜덤 포레스트를 이용해서 회귀 모델을 구할 수 있습니다. 단 차이점은 분류를 위한 의사결정트리 학습과 랜덤 포레스트에서는 정보이득의 불순도 측정을 위해 지니 인덱스나 엔트로피를 사용했다면, 회귀 모델을 위한 정보이득의 불순도 측정은 평균 제곱 오차 MSE로 한다는 것입니다.
개념은 이전에 학습했던 것과 동일하므로 바로 코드로 들어가 보죠~
skl_DTRegression.py

>>> rm = DecisionTreeRegressor(max_depth=3)
의사결정트리 회귀를 위해 scikit-learn의 DecisionTreeRegressor 객체를 이용합니다. 이 객체의 인자 max_depth의 값을 적절하게 조절하여 언더피팅이나 오버피팅이 되지 않도록 하는 것이 중요합니다.
>>> sort_idx = X.ravel().argsort()
의사결정트리 회귀의 결과를 그래프로 표시하기 위해 X의 요소값이 작은 순서로 정렬한 인덱스를 sort_idx로 둡니다. 말이 어려운데, 예를 들어 [1, 0, 5].argsort()의 값은 [1, 0, 2]가 됩니다.
결정 계수의 값을 계산하고 결과를 화면에 출력하면 다음과 같습니다.

결정 계수의 값이 0.70으로 제법 훌륭한 결과가 나옵니다.
이제 랜덤 포레스트를 활용하여 회귀 모델을 구하는 것을 해보도록 합니다. skl_DTRegression.py에서 아래의 모듈을 임포트합니다.
>>> from sklearn.ensemble import RandomForestRegressor
rm = DecisionTreeRegressor(max_depth=3)을 아래의 코드로 변경합니다.
>>> rm = RandomForestRegressor(n_estimators=1000, criterion='mse',
random_state=1, n_jobs=-1)
수정한 코드를 실행하면 아래와 같은 결과가 나옵니다.

결정 계수의 값은 0.91로 매우 훌륭한 결과가 나옵니다만, 회귀 모델 그래프를 보니 뭔가 오버피팅 되어 있다는 느낌이 강합니다. 샘플 데이터를 트레이닝 데이터와 테스트 데이터로 나누어서 측정해봐야 겠습니다.
skl_DTRegression.py에서 rm = DecisionTreeRegressor(max_depth=3) 이하를 모두 지우고, 아래의 코드를 추가합니다.

위 코드를 적용한 skl_DTRegression.py를 실행하면 다음과 같은 결과가 나옵니다.
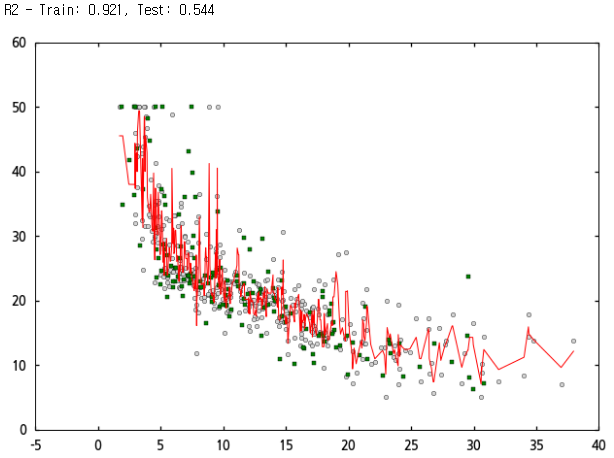
샘플 데이터의 70%를 트레이닝 데이터로 해서 랜덤 포레스트로 계산한 회귀 모델의 결정 계수는 0.921로 매우 높지만, 테스트 데이터를 적용하면 결정 계수의 값이 0.544로 뚝 떨어집니다. 따라서 이 데이터 모델에 대한 랜덤 포레스트 회귀 모델은 오버피팅이 강하게 되어 있다는 것을 알 수 있습니다.
데이터 모델에 따라서 랜덤 포레스트의 결과가 오버피팅이 되어 있을 지라도 테스트 데이터에 대한 결정 계수가 높게 나온다면 바람직한 모델을 구한 것이 됩니다. 아래의 코드를 skl_DTRegression.py에 맨 아래에 추가합니다.

이 코드는 '회귀 분석 - 회귀 모델의 적합도 측정' 포스팅에서 잔차 분석을 위해 사용된 MEDV와 나머지 주택 정보들에 대해, 랜덤 포레스트로 회귀 모델을 구하고 트레이닝 데이터 및 테스트 데이터의 결정 계수를 계산하는 코드입니다.
코드를 수행하면 아래와 같은 결과가 나옵니다.
R2 - Train: 0.980, Test: 0.910
결과를 보면 트레이닝 데이터의 결정 계수에 비해 테스트 데이터의 결정 계수가 작지만 그 값이 0.910으로 적합도가 매우 훌륭하게 나온다는 것을 알 수 있습니다.
이로써 회귀 분석에 대한 내용은 모두 마무리 하도록 하겠습니다.
[출처] [29편] 회귀 분석 - 의사결정 트리 회귀와 랜덤 포레스트 회귀|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [31편] k-means 클러스터링 - 최적 클러스터 개수 찾기 (0) | 2017.12.14 |
|---|---|
| [30편] k-means 클러스터링 (0) | 2017.12.14 |
| [28편] 회귀 분석 - 다항 회귀(Polynomial Regression) (0) | 2017.12.14 |
| [27편] 회귀 분석 - 정규화 기법을 이용한 회귀 모델 (0) | 2017.12.14 |
| [26편] 회귀 분석 - 회귀 모델의 적합도 측정 (0) | 2017.12.14 |