이번 포스팅에서는 클러스터링을 위한 또 다른 기법인 계층적 클러스터링(Hierarchical Clustering) 또는 계층적 군집화에 대해 살펴보겠습니다.
계층적 클러스터링은 특정 알고리즘에 의해 데이터들을 연결하여 계층적으로 클러스터를 구성해 나가는 방법입니다. k-means 클러스터링 방법과는 달리 계층적 클러스터링은 최초에 클러스터의 개수를 가정할 필요가 없다는 장점이 있습니다. 계층적 클러스터링은 아래와 같이 응집형(agglomerative) 계층적 클러스터링과 분리형(divisive) 계층적 클러스터링 2가지가 있습니다.
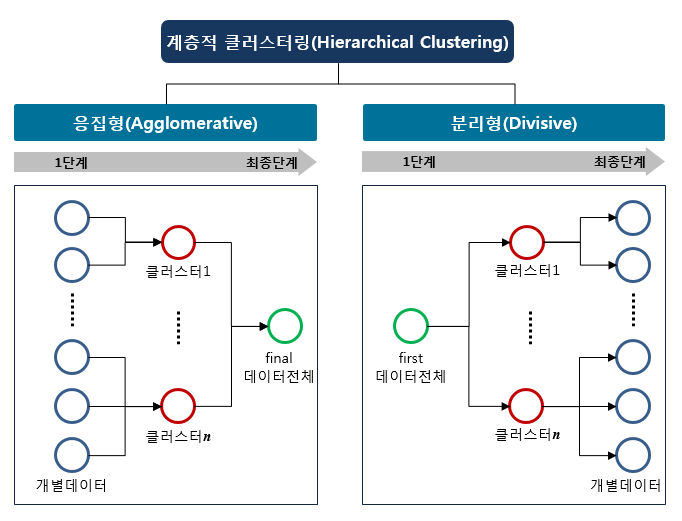
응집형 계층적 클러스터링은 주어진 데이터에서 개별 데이터 하나하나를 독립된 하나의 클러스터로 가정하고 이들을 특정 알고리즘에 의해 병합하여 상위단계 클러스터를 구성하고, 이렇게 구성된 상위단계 클러스터를 특정 알고리즘에 의해 또 다시 병합하여 최종적으로 데이터 전체를 멤버로 하는 하나의 클러스터로 구성하는 방법입니다.
분리형 계층적 클러스터링은 응집형과는 완전히 반대로 진행되는데, 데이터 전체를 멤버로 하는 하나의 클러스터에서 시작하여 개별 데이터로 분리해나가는 식으로 클러스터를 구성하는 방법입니다.
이 포스팅에서는 응집형 계층적 클러스터링에 대해서만 살펴보도록 합니다.
계층적 클러스터링에서 상위 단계의 클러스터를 구성하기 위한 대표적인 특정 알고리즘은 단순연결(single linkage)과 완전연결(complete linkage)이라 불리는 기법이 있습니다.
단순연결 기법은 2개의 클러스터에서 각 클러스터에 속하는 멤버 사이의 거리가 가장 가까운 거리를 모두 계산하고, 이 값들중 가장 작은 값을 가지는 2개의 클러스터를 병합하여 상위 단계 클러스터를 구성하는 방법이며, 완전연결 기법은 2개의 클러스터에서 각 클러스터에 속하는 멤버 사이의 거리가 가장 먼 거리를 모두 계산하고, 이 값들중 가장 작은 값을 가지는 2개의 클러스터를 병합하여 상위 단계 클러스터를 구성하는 방법입니다.
글로 이해하는 것은 역시 어려운 법입니다. 예시를 들어 이해하는 것이 가장 쉽고 빠른 방법이죠.
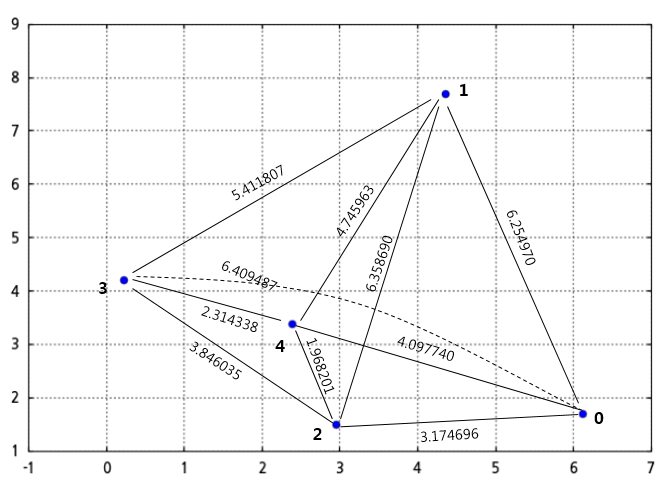
아래 그림과 같이 좌표상에 0~4 번호가 붙어 있는 5개의 점이 있습니다. 이 5개의 점을 응집형 계층적 클러스터링으로 클러스터를 구성해보겠습니다. 클러스터를 구성하기 위한 알고리즘은 완전연결 기법을 이용하겠습니다. (완전연결 기법만 이해해도 단순연결은 쉽게 이해할 수 있습니다.)

이들 점 사이의 거리를 계산하면 아래와 같습니다.
응집형 계층적 클러스터링에서 첫단계는 개별 데이터가 하나의 클러스터로 가정하고 시작하므로 점들간의 거리가 가장 가까운 2개의 점을 하나의 클러스터로 구성하면 될 것입니다. 점2와 점4의 거리가 가장 가까우므로 이 두점을 하나의 클러스터(아래 그림에서 초록색 타원)로 구성합니다.
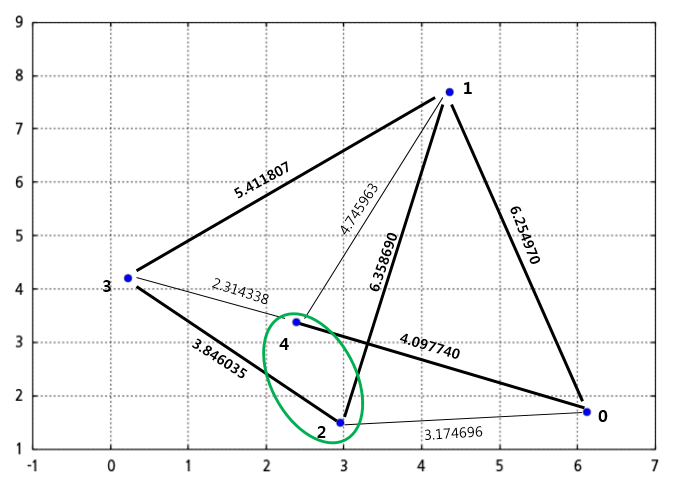
이제 남은 클러스터는 점0, 1, 3과 점2, 점4로 이루어져 있는 초록색 타원으로 표시된 클러스터이겠지요.
이제 각 점과 초록색 타원 클러스터내의 멤버와의 거리중 멀리 있는 거리를 계산합니다. 점0은 초록색 클러스터의 2개의 멤버와의 거리중 멀리 떨어져 있는 점4와의 거리 4.097740을 택합니다. 마찬가지로 점1과 초록색 클러스터의 멤버와 먼 거리는 6.358690이 될 것이고, 점3과 초록색 클러스터 멤버와 먼 거리는 3.846035가 됩니다.
이 값들 중 가장 작은 값은 점3과의 거리인 3.846035가 됩니다. 이 값과 점0과 점1 사이의 거리, 점1과 점3사이의 거리, 점0과 점3사이의 거리중 가장 작은 값을 가지는 거리를 선택합니다. 제일 작은 값은 초록색 클러스터와 점3과의 거리인 3.864035가 됩니다. 따라서 초록색 클러스터와 점3을 병합하여 상위단계 클러스터(아래 그림에서 큰 초록색 타원)를 구성합니다.
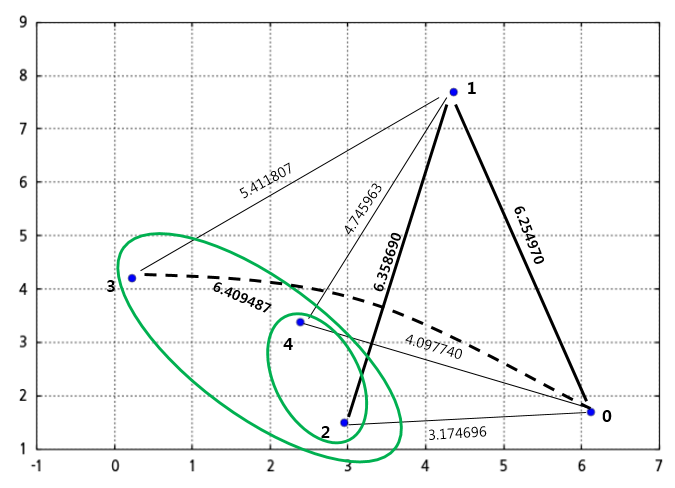
동일한 방법으로 점2, 3, 4를 포함하는 큰 초록색 타원으로 표시된 클러스터 멤버와 점0, 점1과 먼 거리와, 점0과 점1과의 거리 중 가장 가까운 거리를 선택하면 점0과 점1 사이의 거리가 됩니다. 따라서 그 다음 단계로 구성하는 클러스터는 점0과 점1을 묶은 클러스터(아래 그림에서 파란색 타원)가 됩니다.

마지막으로 남은 2개의 클러스터를 묶어 하나의 클러스터로 구성하고 종료합니다. 이 예는 결국 데이터를 초록색과 파란색 타원으로 표현된 2개의 클러스터를 최종 결과로 볼 수 있을 겁니다.
이제 응집형 계층적 클러스터링 방법에 대해 약간 이해가 가시나요? 비교하는 거리가 가까운 거리라는 것 빼고는 단순연결 기법을 이용하는 것도 완전연결과 동일한 절차로 수행하면 됩니다.
아래 코드를 봅니다.
skl_makerandompts.py

이 코드를 수행하면 응집형 계층적 클러스터링의 이해를 위해 도입했던 점0~4까지가 좌표상에 나타날 겁니다.
skl_makerandompts.py 맨 아래에 다음 코드를 추가합니다.
skl_caldist.py

이 코드는 scipy.spatial.distance 모듈이 제공하는 pdist와 squareform을 이용하여 skl_makerandompts.py가 생성한 점0~점4의 거리 행렬을 구하고 화면에 표시해줍니다.
점 5개의 대한 거리행렬은 5x5 정사각 행렬로 만들어집니다. pandas를 이용해 보기좋게 화면에 출력하면 다음과 같습니다.
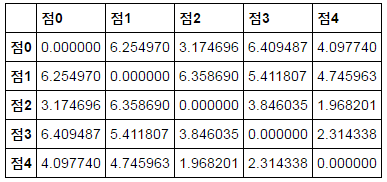
각 점 사이의 거리가 계산되어 그 값을 요소로 하는 정사각행렬로 구성되었다는 것을 알 수 있습니다. 거리 행렬은 대각선 요소를 기준으로 대칭인 행렬이 됩니다.
참고로 pdist는 인자로 입력된 numpy 배열에 있는 값을 이용해 각 요소들의 거리를 계산하고 거리 행렬의 대각 요소의 윗 부분의 값들을 1차원 배열로 구성하여 리턴합니다.
skl_caldist.py 맨 아래에 다음 코드를 추가합니다.
skl_complete_linkage.py

이 코드는 scipy.cluster.hierarchy 모듈이 제공하는 linkage를 이용해 완전연결 기법을 적용한 응집형 계층적 클러스터링을 수행하고 그 결과를 화면에 표시합니다.
코드에서 주석처리한 부분은 주석 처리하지 않은 바로 위코드와 동일한 기능을 수행합니다.
이 코드를 수행하면 아래와 같은 결과가 나옵니다.

이 표에서 클러스터1~클러스터4는 완전연결을 이용해 응집형 계층적 클러스터링으로 차례로 구성되는 클러스터를 의미하며, 클러스터ID_1과 클러스터ID_2는 병합되는 클러스터 번호를 나타냅니다. 표에서 거리는 클러스터ID_1과 클러스터ID_2의 가장 먼 거리를 나타내며, 클러스터 멤버수는 병합된 클러스터에 속해 있는 멤버 개수를 의미합니다.
최초 5개의 점(응집형에서는 이 점들 최초 단계에서는 하나의 클러스터가 됨)이 있다는 것을 고려하여 표를 해석해보면, 1단계에서 클러스터ID 2와 4를 병합하여 6번째(클러스터ID는 5가 됨) 클러스터를 구성하고, 2단계에서 클러스터 ID 3과 5를 병합하여 7번째 클러스터를 구성합니다. 3단계에서 클러스터ID 0과 1을 병합하여 8번째 클러스터를 구성하고, 마지막 단계에서 클러스터 ID 6과 7을 병합하여 9번째 클러스터를 구성하고 종료합니다.
linkage()의 리턴값 row_clusters를 이용하여 클러스터의 계층 구조를 덴드로그램(dendrogram, 계통도)으로 나타낼 수 있습니다. 아래의 코드를 skl_complete_linkage.py 맨 아래에 추가합니다.
skl_dendrogram.py

코드를 실행하면 아래와 같은 응집형 계층적 클러스터링의 결과를 덴드로그램으로 보여줍니다.
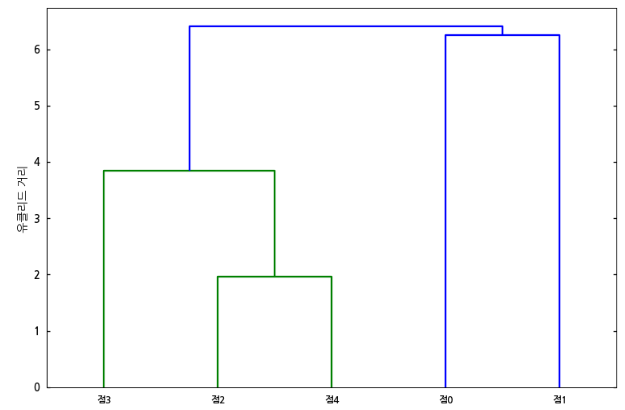
덴드로그램에서 세로축은 완전연결 기법으로 계산한 클러스터 사이의 유클리드 거리를, 가로축은 최초 단계에서 클러스터(점)를 나타냅니다. 이 덴드로그램을 보면 점2와 점4는 하나의 클러스터로 봐도 무방할 정도로 유클리드 거리가 작지만, 점0과 점1은 하나의 클러스터로 보기에는 상대적으로 부적절하다는 것을 알 수 있습니다.
이러한 덴드로그램이 실제로 활용될 때 아래와 같이 상관도를 색상으로 표현해주는 히트맵(heat map)과 조합하여 표시해주면 더욱 직관적으로 파악할 수 있습니다.

위 그림처럼 화면에 나타내려면 약간 노동집약적인 트릭이 필요합니다. skl_dendrogram.py를 아래의 코드로 변경하면 됩니다. 코드에 대한 설명은 생략합니다.

scikit-learn은 응집형 계층적 클러스터링을 위해 AgglomerativeClustering이라는 클래스를 제공하며, 계층적 클러스터링에 의해 최종적으로 분류된 클러스터에 대한 정보만 보여줍니다.
아래의 코드를 skl_makerandompts.py 맨 아래 부분에 추가합니다.

코드를 수행하면 아래와 같은 결과가 나옵니다.
클러스터 분류 결과: [0 0 1 1 1]
[0 0 1 1 1]의 의미는 점0, 점1은 클러스터0, 점2, 점3, 점4는 클러스터1로 분류된다는 것을 나타냅니다. 따라서 최종적으로 분류한 클러스터의 개수는 2개가 되며, 이는 scipy를 이용했을 때와 클러스터링 결과가 동일하다는 것을 알 수 있습니다
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [34편] 딥러닝의 기초 - 다층 퍼셉트론(Multi-Layer Perceptron; MLP) (0) | 2017.12.14 |
|---|---|
| [33편] 밀도기반 클러스터링 - DBSCAN (0) | 2017.12.14 |
| [31편] k-means 클러스터링 - 최적 클러스터 개수 찾기 (0) | 2017.12.14 |
| [30편] k-means 클러스터링 (0) | 2017.12.14 |
| [29편] 회귀 분석 - 의사결정 트리 회귀와 랜덤 포레스트 회귀 (0) | 2017.12.14 |