이번 포스팅에서는 밀도기반 클러스터링인 DBSCAN(Density-based Spatial Clustering of Applications with Noise)에 대해 살펴보고 클러스터링에 대한 내용을 마무리하도록 하겠습니다.
DBSCAN의 개념적 원리는 단순합니다. 이해를 위해 2차원 평면에 아래 그림과 같이 9개의 데이터가 분포되어 있다고 가정합니다.
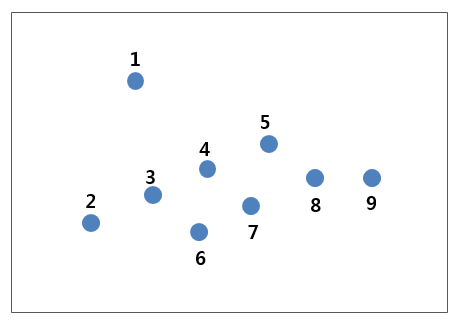
여기에 반지름이 ε인 원이 있다고 하고, 1번 데이터부터 9번 데이터까지 원의 중심에 이 데이터들을 둔다고 생각해봅니다.
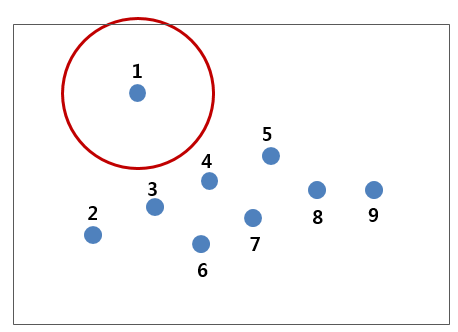
1번 데이터를 반지름 ε인 원의 중심에 둔 그림입니다. 원안에 점이 1번을 제외하고는 없네요. 자 여기서 우리가 하나의 클러스터로 묶을 기준을 정의합니다. 이 원안에 적어도 4개 이상의 점들이 포함되는 녀석들만 골라서 하나의 클러스터로 분류하는 것으로 해보겠습니다. 위 그림처럼 1번 데이터를 원에 중심에 두었을 경우, 1번 데이터를 제외하고는 아무런 데이터가 없습니다. 이런 데이터들을 노이즈 데이터(noise point)라 부르며, 노이즈 데이터들은 클러스터에서 제외시킵니다.
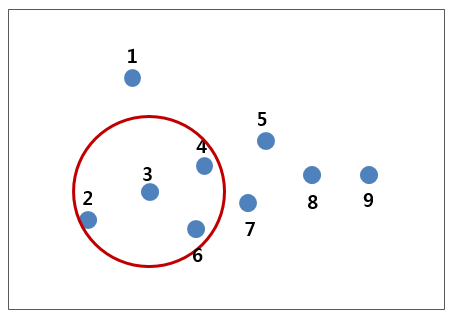
위 그림에서 보는 바와 같이 3번 데이터를 원의 중심으로 두었을 때 4개의 점이 원안에 포함됩니다. 따라서 우리가 세운 기준에 충족하는 데이터가 됩니다. 이러한 데이터를 코어 데이터(core point)라 부릅니다. 코어 데이터들은 하나의 클러스터에 포함시킵니다.
그런데, 아래 그림에서 보는 것처럼 2번과 9번 데이터는 우리의 기준인 4개의 데이터를 포함하는 것에는 충족하지 못하지만 클러스터에 포함되는 코어 데이터인 3번 데이터를 포함하고 있습니다. 이런 데이터를 경계 데이터(border point)라 부르며 이 녀석들도 해당 클러스터에 포함시킵니다.
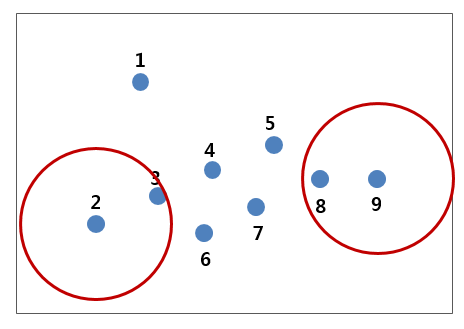
이런 식으로 반지름 ε인 원을 이용해 코어 데이터, 경계 데이터, 노이즈 데이터들을 분류해보면 아래 그림과 같은 결과가 나옵니다.

위 그림은 최종적으로 데이터들을 분류한 것이며, 빨간색과 노란색 데이터들을 하나의 클러스터로 묶고, 회색 데이터는 클러스터에서 제외합니다.
DBSCAN의 원리는 이것이 다입니다.
자, 그러면 코드로 들어가 볼까요..
skl_dbscandata.py

이 코드는 필요한 모듈을 임포트한 후, 반달 모양으로 분포하는 샘플 데이터를 생성하고 화면에 출력합니다. 코드를 실행하면 아래와 같은 데이터 분포를 볼 수 있습니다.
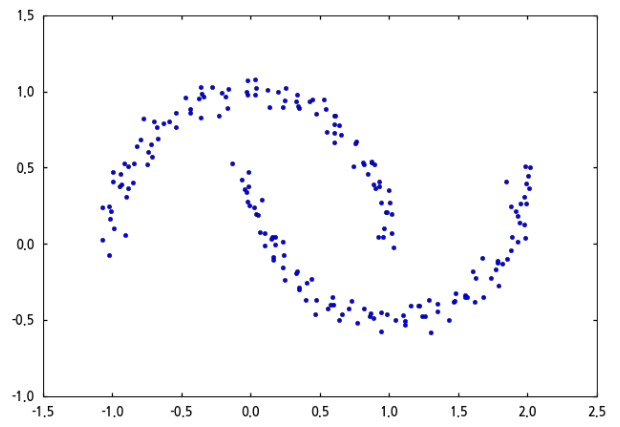
샘플 데이터는 위쪽 반달 부분에 100개, 아래쪽 반들 부분에 100개의 데이터가 분포하고 있습니다.
이제 아래 코드와 같이 plotResult()라는 함수를 정의하고, k-means 클러스터링으로 샘플 데이터를 분류합니다. plotResult()는 다양한 클러스터링 기법으로 분류한 결과를 시각적으로 보이기 위한 것입니다.

skl_dbscandata.py에서 plt.scatter() 이하 2줄을 삭제하고 위 코드를 추가한 후 실행하면 아래와 같은 결과가 나옵니다.
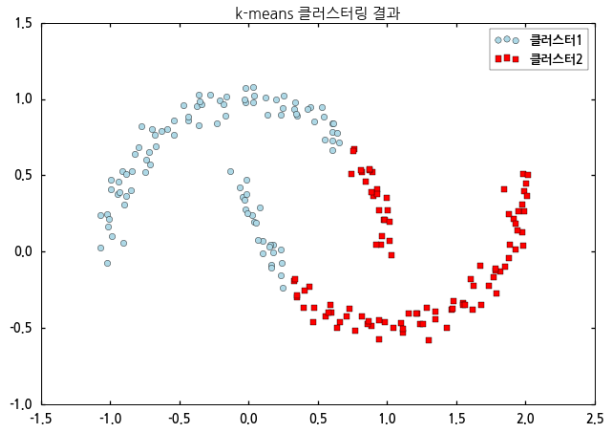
k-means 클러스터링으로 분류한 결과는 어떤가요? 뭔가 제대로 분류된 것 같지가 않습니다. 아무래도 위쪽 반달과 아래쪽 반달로 구분해야 더 적절한것 같은데요.. 이제 32편에서 다루었던 응집형 계층적 클러스터링으로 한번 분류해보죠.
기존 코드에 아래의 코드를 추가합니다.
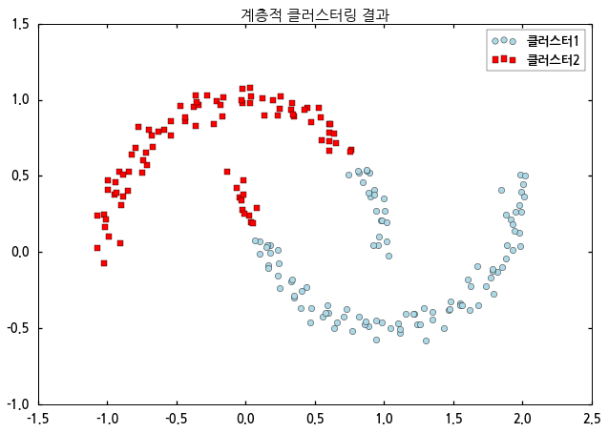
계층적 클러스터링의 결과도 k-means와 비슷하지만 그래도 좀 품질이 좋아진 것 같네요. 이제 이번 포스팅의 주제인 DBSCAN을 이용해 분류해봅니다. 기존 코드에 아래의 코드를 추가합니다.

코드에서 DBSCAN의 인자 eps가 위에서 언급했던 원의 반지름이며, min_samples는 원에 포함되는 데이터 개수의 최소값입니다. 추가한 코드를 실행하면 아래와 같은 결과가 나옵니다.
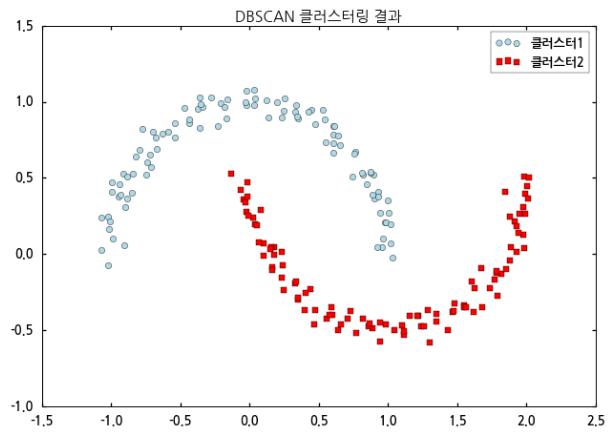
드디어 우리가 원하던 결과가 나온 것 같습니다.
우리가 여태 다루었던 k-means 클러스터링, 계층적 클러스터링, DBSCAN은 데이터 간 유사도를 위해 유클리드 거리를 적용하여 계산했습니다. 유클리드 거리를 이용하는 기법에는 '차원의 저주(curse of dimensionality)'라는 효과가 발생한다는 단점이 존재합니다.
차원의 저주는 머신러닝, 데이터 마이닝 분야에서 사용하는 용어인데 데이터의 차원이 증가하면 해당 공간의 부피가 기하급수적으로 증가하게 되고, 모델을 추정하기 위해 필요한 샘플 데이터의 개수도 기하급수적으로 증가합니다. 또한 공간 상에 분포하는 데이터의 밀도 역시 매우 희박하게 됩니다. 이런 현상을 차원의 저주라는 표현을 써서 어려움을 나타내는 것이지요.
아무튼 DBSCAN에서 차원의 저주를 극복하기 위해 적절한 ε의 값과 최소 샘플 데이터 개수를 정하는 것이 중요한 포인트입니다.
이로써 머신러닝 기초에 대한 개념과 원리, 내용에 대해서는 거의 다 살펴본 것 같습니다. 앞으로의 포스팅에서는 요즘 핫하게 뜨고 있는 딥러닝을 이해하기 위한 인공신경망에 대해 본격적으로 공부해 보기로 합니다.
[출처] [33편] 밀도기반 클러스터링 - DBSCAN|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [35편] 딥러닝의 핵심 개념 - 역전파(backpropagation) 이해하기1 (0) | 2017.12.14 |
|---|---|
| [34편] 딥러닝의 기초 - 다층 퍼셉트론(Multi-Layer Perceptron; MLP) (0) | 2017.12.14 |
| [32편] 계층적 클러스터링 (0) | 2017.12.14 |
| [31편] k-means 클러스터링 - 최적 클러스터 개수 찾기 (0) | 2017.12.14 |
| [30편] k-means 클러스터링 (0) | 2017.12.14 |