[35]편에서 역전파에 대한 개념적인 내용을 살펴보았습니다. 그런데, [35편]에서 역전파 개념을 설명할 때 도입한 비용함수 J(w)는 아래와 같이 오차제곱합으로 정의했습니다.
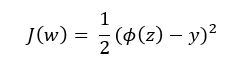
여기서 Φ(z)는 활성 함수인 시그모이드 함수값인거죠.
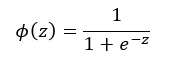
그리고 z는 각 층에서 순입력 함수값인거 아실겁니다.
그런데 활성함수가 시그모이드이고 오차제곱합으로 정의된 비용함수는 경사하강법을 적용하는데 약간의 문제가 있습니다. 오차제곱합으로 정의된 비용함수 J(w)를 그래프로 그려보면 아래와 비슷한 모양이 됩니다.

이런 모양을 이루고 있는 함수에서 경사하강법을 적용하게 되면 우리가 원하는 최소값에 도달하는 것이 아니라 아래 그림과 같이 국소적인 부분에서의 최소값에 도달하고 더 이상 진행할 수 없는 상태가 될 수 있습니다.
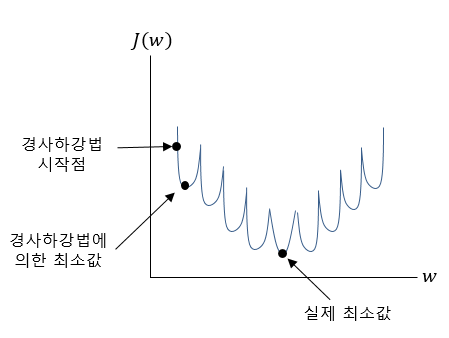
경사하강법이 성공적으로 적용되려면 볼록형태의 그래프를 가진 함수이어야 합니다. 그래서 머리 좋은 몇몇 사람들이 로지스틱 회귀를 위한 비용함수를 경사하강법이 적용될 수 있도록 그래프가 볼록한 모양으로 되는 새로운 비용함수를 아래와 같이 정의하게 됩니다.
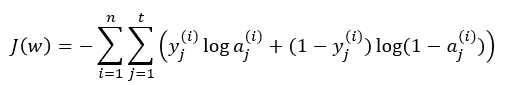
하~ 복잡한 수식이네요.. 아무튼 위 식에서 n은 트레이닝 데이터의 개수이며, t는 출력층의 출력값의 개수입니다. 그리고 y는 트레이닝 데이터에 대한 실제값이며 a는 트레이닝 데이터에 대한 활성 함수값 즉 학습에 의한 결과값입니다.
그런데 이 수식은 복잡해보여도 트레이닝 데이터에 대한 실제 결과값 y의 값을 0 또는 1로 정의해버리면 단순하게 됩니다. y값이 1이면 J(w)의 두번째 항이 0으로 되고, y값이 0이면 J(w)의 첫번째 항이 0으로 됩니다. 즉,
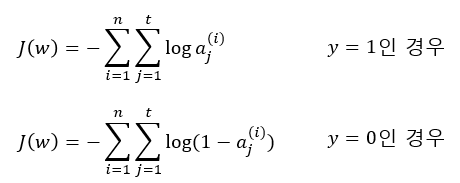
이 두 개의 식을 하나로 표현한 것이 저 위에 있는 복잡해보이는 수식이 됩니다. 자, 이제 [35편]에서 언급한 가중치 업데이트 식을 다시 가져와 봅니다.
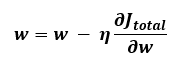
가중치 업데이트를 하려면 J에 대한 w의 미분값이 필요한거 이제 다 아는 이야기입니다. 위 J(w) 식에서 a는 시그모이드 함수 Φ(z)입니다. 시그모이드 함수 Φ를 미분하면 Φ(1-Φ)가 됩니다. 이 부분을 유념하면서 진행하도록 합니다.
[35편]에서 역전파 개념 이해를 위해 도입된 2-2-2 다층 퍼셉트론을 다시 불러옵니다.

여기서 순전파에 있어 값의 흐름을 다시 불러와서 적어보면 다음과 같습니다.
[식 1]
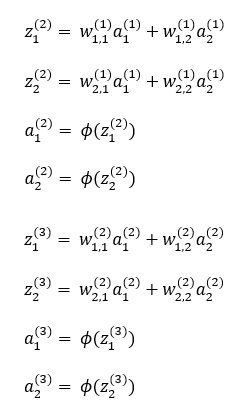
그리고, 출력층 a1(3), a2(3)에서의 출력값과 실제값의 오차 J1, J2는 로지스틱 회귀의 비용함수를 이용해 다음과 같이 정의합니다.
[식2]

이제 [35편]에서 설명한 바와 마찬가지로 방법으로 역전파를 이용해 가중치를 업데이트 해보도록 합니다. 계산의 편의를 위해 learning rate η는 1로 둡니다.
먼저, w1,1(2)에 대한 업데이트 식을 구해봅니다. 이를 위해 Jtotal을 w1,1(2)에 대해 미분한 값을 구해야겠지요~ a1(3)에서 Jtotal은 J1이므로,

[식2]와 [식1]을 참조하여 위의 식을 계산하면 다음과 같습니다.

따라서
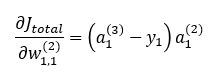
마찬가지로 Jtotal을 w1,2(2)에 대해서 미분한 값은 다음과 같습니다.
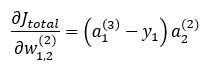
동일한 방법으로 가중치 w2,1(2), w2,2(2)에 대해서 계산해보면 다음과 같은 결과가 유도됩니다.
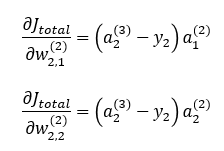
이 식들을 하나의 식으로 표현하면 다음과 같이 됩니다.
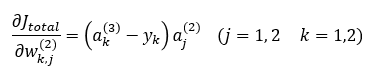
위 식을 아래와 같은 식으로 단순화하여 표현해봅니다.
[식3]

여기서, j, k는 각각 은닉층의 출력값 개수 범위와 출력층의 출력값 개수 범위를 적용하면 되므로, 이로써 출력층에서 은닉층으로의 역전파에 대해 파이썬으로 구현하기 위한 알고리즘을 마련한 것 같습니다.
[35편]을 참조하여 은닉층에서 입력층으로의 역전파시 가중치 업데이트 식을 계산하여 정리하면 다음과 같습니다.
[식4]
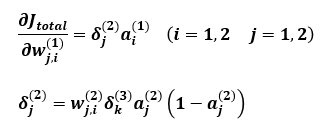
여기서, i는 입력층의 입력값 개수가 범위이며, [식4]를 통해 은닉층에서 출력층으로의 역전파에 대해 파이썬으로 구현하기 위한 알고리즘도 마련되었습니다.
n1-n2-n3 다층 퍼셉트론에서 역전파시 가중치 업데이트를 위한 식은 아래와 같이 표현할 수 있습니다.
[식5]
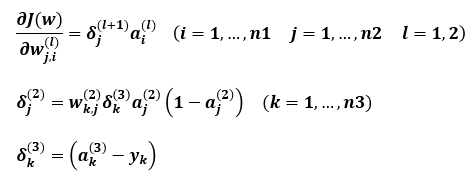
이로써, 역전파를 통해 가중치를 업데이트하는 일반화된 식을 이용해 파이썬으로 잘 구현하면 될 것 같습니다.
실제로 다층 퍼셉트론을 코드로 구현할 때, 성능 향상을 위하여 비용함수에 정규화 L1, L2를 적용한 항을 추가하여 계산하게 됩니다.
여기서 잠깐..
[35편]과 [36편]에서 역전파를 이해하기 위해 도입한 활성함수는 시그모이드 함수입니다. 시그모이드 함수는 활성함수로서 여러가지 장점이 있는 함수임에는 틀림이 없으나 은닉층이 매우 많은 심층신경망에서는 단점이 존재하는데, 신경망의 은닉층이 많아질수록 역전파에 의한 가중치 보정이 의미가 없어지는 gradient vanishing 문제가 발생합니다.
gradient vanishing은 역전파를 수행하는 은닉층의 개수가 많아지면 J(w)의 w에 대한 편미분값이 0에 가까와져서 가중치 업데이트 식에 의한 가중치 갱신이 거의 이루어지지 않기 때문에 발생하는 현상입니다. 이는 [식5]의 δ의 절대값이 1보다 작기때문에 δ를 곱하면 곱할수록 0에 가까와지기 때문입니다.
gradient vanishing 현상을 해결하기 위해 새로운 활성함수를 도입하게 되는데 바로 ReLU(Rectified Linear Unit)라는 함수입니다. ReLU는 아래 그래프와 같이 입력값이 0보다 작거나 같으면 0, 0보다 크면 입력값을 리턴하는 함수입니다.
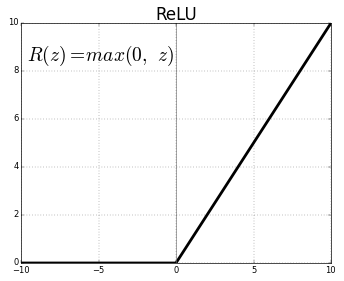
심층신경망에서 활성함수로써 ReLU는 시그모이드보다 훨씬 나은 성능을 보이며, 대부분의 심층신경망에서 활성함수로 널리 사용되고 있습니다.
따라서 [35편]과 [36편]에서 보인 시그모이드를 활성함수로 한 예시는 역전파의 개념을 이해하는데 만족하시고 실제 응용시에는 ReLU를 활성함수로 적용하면 됩니다.
다음 포스팅에서는 Sebstian Raschka의 책 "Python Machine Learning"에 있는 다층 퍼셉트론을 구현한 파이썬 코드를 소개하고, MNIST에서 제공하는 손글씨 숫자 이미지 60,000개를 이용해 MLP 딥러닝 학습을 수행한 후 손글씨 숫자 인식률에 대해서 살펴보도록 합니다.
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [38편] 인공신경망의 정확성 검증 - gradient checking (0) | 2017.12.14 |
|---|---|
| [37편] 다층 퍼셉트론 구현하기 (0) | 2017.12.14 |
| [35편] 딥러닝의 핵심 개념 - 역전파(backpropagation) 이해하기1 (0) | 2017.12.14 |
| [34편] 딥러닝의 기초 - 다층 퍼셉트론(Multi-Layer Perceptron; MLP) (0) | 2017.12.14 |
| [33편] 밀도기반 클러스터링 - DBSCAN (0) | 2017.12.14 |