이번 포스팅에서는 [34편]~[36편] 내용에서 다룬 다층 퍼셉트론을 파이썬으로 구현한 코드를 소개하고, MNIST의 손글씨 숫자 60,000개의 샘플을 딥러닝 학습을 수행한 후 손글씨 숫자에 대한 인식률을 살펴보는 것으로 하겠습니다.
MNIST 데이터는 다양한 사람들이 직접 쓴 숫자 0~9까지의 이미지 집합이며, 이미지의 크기는 28 x 28 크기로 표준화되어 있습니다. MNIST 데이터는 트레이닝을 위한 60,000개의 손글씨 숫자 이미지 데이터와 테스트를 위한 10,000개의 손글씨 숫자 이미지 데이터로 구성되어 있습니다.
먼저 아래의 링크를 눌러서 MNIST 데이터를 확보합니다.
링크를 눌러 MNIST 데이터 홈페이지에 들어가면 아래와 같은 4개의 데이터 파일이 보일 것입니다.
- train-images-idx3-ubyte.gz : training set images
- train-labels-idx1-ubyte.gz : training set labels
- t10k-images-idx3-ubyte.gz : test set images
- t10k-labels-idx1-ubyte.gz : test set labels
이 파일들을 모두 다운로드 받아 특정 디렉토리에 저장한 후, 압축 프로그램을 이용해 압축을 해제합니다.
MNIST 데이터 홈페이지 아랫부분에 보면 이 파일들에 대한 포맷형식이 설명되어 있습니다. 파일 포맷을 요약해보면 다음과 같습니다.
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
※label 값은 0~9까지임
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
※ 픽셀값은 1바이트씩 아래로 쭉 연결됨. 28x28=784바이트 단위로 하나의 손글씨 이미지로 구분되며 pixel값이 0이면 흰색 바탕, 255이면 검정색 숫자 부분을 의미함
테스트를 위한 파일 포맷도 트레이닝 데이터와 마찬가지 포맷입니다. 트레이닝을 위한 라벨 데이터가 저장된 파일의 최초 8바이트에는 아이템 개수 등의 정보가 저장되어 있고 라벨은 9바이트째부터 시작됩니다. 손글씨 숫자 이미지가 저장된 파일의 최초 16바이트에는 이미지 개수, 가로 세로 픽셀수 등의 정보가 저장되어 있고 이미지 픽셀 데이터는 17바이트째부터 시작됩니다.
자, 그럼 아래의 코드를 봅니다.
dl_load_digits.py

위 코드의 load_mnist(path, kind='train')는 라벨 데이터가 저장된 파일과 이미지 데이터가 저장된 파일로부터 데이터를 모두 읽어 각각 numpy 배열 labels, images로 저장하여 리턴하는 함수입니다.
참고로 이 포스팅에서는 학습을 위한 데이터가 저장된 폴더는 dl_load_digits.py가 저장된 폴더 아래에 data/mnist 폴더입니다. 따라서 여러분들의 학습 데이터가 저장된 폴더 위치에 맞게 경로를 조정해줘야 한다는 거 잊지마세요~
코드에 등장하는 struct.unpack()은 저의 첫번째 책 '암호와 해킹'에서 간략하게 설명되어 있는데, 간단히 요약하여 설명하면, 파이썬의 struct 모듈은 파이썬 바이트 객체로 표현된 C구조체와 파이썬에서 사용하는 값을 상호 변환하는데 사용되는 각종 메쏘드들을 제공합니다.
>>> magic, n = struct.unpack('>II', imgpath.read(8))
이 코드의 의미는 imgpath 파일에서 8바이트 데이터를 big-endian(>)으로 읽고, 읽은 데이터를 unsigned integer(I) 2개로 나누어서 각각 magic, n 변수에 대입하라는 뜻입니다.
이 코드를 실행하면 4개의 MNIST 데이터 파일을 모두 읽어, 트레이닝 이미지 데이터는 X_train, 트레이닝 라벨 데이터는 y_train, 테스트 이미지 데이터는 X_test, 테스트 라벨 데이터는 y_test로 저장하고 이미지 샘플의 개수 정보를 화면에 표시합니다.
코드를 실행하면 다음과 같은 결과가 나오면 데이터를 성공적으로 로드한 것입니다.
학습 샘플수 : 60000, 컬럼수: 784
테스트 샘플수 : 10000, 컬럼수: 784
이제, 아래의 코드를 dl_load_digits.py 아래 부분에 추가합니다.
dl_show_09digits.py

이 코드는 X_train에 저장된 0~9까지 이미지를 화면에 출력하는 코드입니다. 코드를 실행하면 다음과 같은 손글씨 숫자가 화면에 나올 겁니다.

위 코드를 아래와 같이 약간 수정해서 같은 숫자 25개에 대한 이미지를 화면에 출력하도록 해봅니다.
dl_show_samedigits.py

이 코드를 실행하면 아래와 같이 숫자 6에 대한 다양한 손글씨 이미지 25개를 화면에 출력합니다.

dl_show_samedigits.py 코드에서 y_train == 6 부분을 y_train == 5 등으로 바꾸어 다른 숫자들도 확인해보세요. 이로써 우리가 확보한 MNIST 손글씨 데이터가 어떤 식으로 되어있는지 확인을 했네요~
이제는 이 손글씨 데이터를 학습할 다층 퍼셉트론을 파이썬으로 구현하는 것입니다. 이 포스팅에 제시된 대부분의 소스코드는 Sebatian Raschka의 책 "Python Machine Learning"에서 발췌한 것이며 필요시 제가 조금 수정하거나 추가한 코드도 있기도 합니다. 아래에 제시된 MLP 구현 코드도 이 책에서 발췌한 것인데, 딥러닝 성능을 위해 추가적인 알고리즘이 적용되어 있는 제대로 된 다층 퍼셉트론을 구현한 코드입니다.
dl_mlp_class.py




음... 코드가 참 깁니다. 딥러닝의 세계는 쉽지 않은 길입니다. NeuralNetMLP라는 이름의 클래스가 바로 다층 퍼셉트론을 구현한 부분입니다. 코드의 세부적인 내용을 이 포스팅에서 일일이 서술하는 것은 무리일 것 같아서, 함수 단위로 설명을 하도록 합니다.
먼저, NeuralNetMLP 클래스의 초기값을 위해 입력되는 인자들이 굉장히 많습니다. 이 인자들에 대해 가볍게 살펴보는 것으로 시작해봅니다.
- n_output:
- 출력층의 출력값 개수. 손글씨 숫자의 경우 0~9까지 10으로 지정하면 됨
- n_features:
- 입력층에 입력되는 특성값의 개수. 28x28 픽셀의 이미지 데이터이므로 784로 지정하면 됨
- n_hidden:
- 은닉층의 노드 개수. 손글씨 숫자 학습을 위해 50으로 지정할 것임
- l1:
- L1 정규화를 위한 람다값. 오버피팅 방지를 위한 것임
- l2:
- L2 정규화를 위한 람다값. 오버피팅 방지를 위한 것임
- epochs:
- 학습 반복 회수
- eta:
- learning rate η
- alpha:
- 가중치 업데이트를 보다 고속으로 처리하기 위한 모멘텀 학습 파라미터
- decrease_const:
- 학습 수렴률을 향상시키기 위해 learning rate을 학습 반복에 따라 감소시키기 위한 감쇠 상수
- 처음에는 learning rate을 다소 큰 값으로 잡아 최소값에 빨리 다다르게 한 후, 감쇠 상수를 지속적으로 곱해서 learning rate을 점점 작아지게 할 용도로 사용됨
- shuffle:
- 매 반복마다 트레이닝 데이터를 뒤섞기를 위한 플래그. True이면 뒤섞음
- minibatches:
- 매 학습에 사용되는 무작위로 추출할 트레이닝 데이터의 실제 개수. 확률적 경사하강법 적용 개념임
- 모집단에서 일정 크기의 표본을 추출하여 결과를 통계적으로 예측하는 것과 비슷한 개념
이것으로 NeuralNetMLP의 초기화를 위한 인자에 대해 설명했습니다. 보면 우리가 아직 다루지 않은 모멘텀 학습 파라미터라든가 감쇠 상수 같은 내용도 있는데, 그냥 이런 것들이 있다는 것만 알고 넘어갑니다.
아무튼 NeuralNetMLP는 [34편], [35편], [36편]에서 다룬 내용을 코드화 한 것으로 볼 수 있습니다.
이제 NeuralNetMLP의 각 함수에 대해 가볍게 설명합니다.
- _encode_labels(self, y, k)
- 출력층 10개 노드에서 출력되는 값이 (1, 0,...0)이면 0, (0, 1, 0,,,)이면 1, (0, 0, ...,1)이면 9를 의미하는 것으로 정의함
- y는 손글씨 숫자의 라벨링 데이터, k는 출력층의 출력값 개수
- _initialize_weights(self)
- 입력층과 은닉층 사이의 가중치 w1과 은닉층과 출력층 사이의 가중치 w2의 값을 초기화함. 바이어스 항도 포함시킴
- _sigmoid(self, z)
- z에 대한 시그모이드 함수값을 리턴함. scipy.expit()은 시그모이드 함수임
- _sigmoid_gradient(self, z)
- z에 대한 시그모이드 함수의 미분값을 리턴함.
- _add_bias_unit(self, X, how='column')
- X에 바이어스 값을 추가해서 X_new로 둠. 행렬 계산의 특성상 입력층에서 은닉층, 은닉층에서 출력층으로의 계산을 위해 how 값을 'column', 'row'로 지정하여 바이어스를 행에 더하거나, 열에 더하도록 함
- _feedforward(self, X, w1, w2)
- w1, w2 가중치로 X를 순전파 시킵니다. 순전파한 결과는 a1, z2, a2, z3, a3로 리턴함
- _L2_reg(self, lambda_, w1, w2), _L1_reg(self, lambda_, w1, w2)
- L2 정규화와 L1 정규화 값을 리턴함
- _get_cost(self, y_enc, output, w1, w2)
- 로지스틱 비용함수 J를 리턴함. J에는 정규화를 위한 값이 추가되었음
- _get_gradient(self, a1, a2, a3, z2, y_enc, w1, w2)
- 역전파 알고리즘을 구현한 함수
- predict(self, X)
- X에 대한 예측값을 리턴
- fit(self, X, y, print_progress=True)
- 트레이닝 데이터 X, y를 이용해 다층 퍼셉트론을 학습시킴. 학습의 속도를 위해 minibatches로 지정된 개수만큼 데이터를 무작위로 추출하여 학습을 시킴
코드의 세부적인 내용은 언급안했으나, 각 함수들의 역할과 이전 포스팅 [34편]~[36편]에서 다루었던 내용을 참고하여 코드를 다시 한번 보면 코드의 내용을 이해할 수 있을 것입니다.
이 코드를 dl_load_digits.py 맨 마지막 부분에 추가합니다.
이제는 구현한 다층 퍼셉트론으로 60,000개의 데이터에 대해 학습을 수행하는 코드를 볼 차례입니다.
dl_mlp_learning.py

이 코드는 결국 784-50-10 다층 퍼셉트론을 구성하고 50개의 데이터를 무작위로 추출한 후 1000번 반복 학습을 수행하는 코드입니다. 학습을 수행하는데 소요되는 시간은 컴퓨터의 성능에 따라 10~30분정도 소요됩니다. 한번 학습한 것을 또 학습할 수는 없으므로 pickle을 이용해 학습된 mlp 객체를 파일로 저장하여 나중에 다시 불러 사용할 수 있게 합니다.
추가한 코드를 실행합니다. 시간이 걸리므로 잠시 다른 일을 하고 와도 됩니다.
학습이 종료되면 학습 결과가 mlp_digits.pkl로 저장됩니다. 이 파일을 불러오려면 아래의 코드를 활용합니다.
dl_load_mlpobj.py

사용법은 이렇습니다. 여태까지 작성된 코드에서 dlp_mlp_learning.py 코드 부분은 주석 처리해서 나중에 트레이닝 데이터가 갱신되게 되면 재사용할 수 있도록 합니다. 그런 후, 주석 처리된 코드 아랫 부분에 dl_load_mlpobj.py 코드를 추가합니다. 이게 끝입니다. 이젠 10분 이상 걸리는 학습을 더 이상 수행하지 않아도 됩니다.
이제 학습의 결과가 어떠한지 살펴볼까요~. 일단 비용함수 J가 어떤 식으로 변화하는지 그래프로 살펴봅니다. 아래의 코드를 여태까지 작성한 코드 마지막 부분에 추가합니다.
dl_plot_cost1.py

추가한 코드를 실행하면 다음과 같은 결과가 화면에 나옵니다.
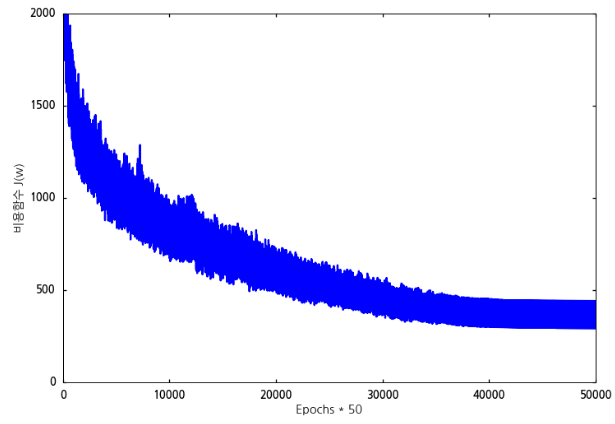
이 그래프는 실제로 비용함수의 값이 오르락 내리락 하는 그래프인데 실제로 그렇게 보이지 않네요. 아무튼 비용함수의 값이 오르락 내리락하면서 편차가 심합니다. 하지만 40,000번째 이후에는 오르락 내리락 하면서도 일정한 범위로 수렴한다는 것을 볼 수 있습니다.
그런데 이 녀석은 minibatches의 단위 50개의 데이터를 처리하는 과정에서 매회 비용함수를 계산한 것입니다. x축의 값을 보면 1,000번 반복한 것이 아니라 50,000번 반복한 것으로 나오는 이유입니다. 따라서 50개의 데이터를 처리한 것의 평균 비용함수의 값을 그래프로 나타내 봅니다.
dl_plot_cost1의 코드를 다음과 같이 수정합니다.
dl_plot_cost2.py

수정된 코드를 실행하면 다음과 같은 결과가 나옵니다.
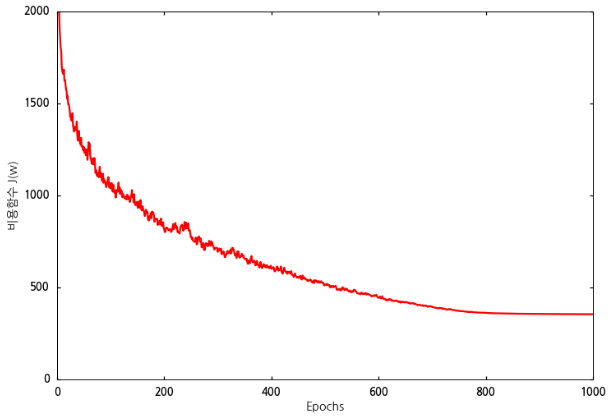
그래프를 보면 800회 학습 이후에 비용함수가 특정값으로 수렴하고 있음을 알 수 있습니다.
이제는 학습된 결과를 살펴보도록 합니다. 아래는 60,000개의 학습 데이터를 이용해 학습을 시키고 학습 데이터에 대한 학습 정확도를 계산하는 코드입니다.
dl_mlp_predict_train.py

이 코드를 실행하면 다음과 같은 결과가 나옵니다.
예측성공/총개수: [58680]/[60000]
딥러닝 정확도: 97.80%
dl_mlp_predict1.py를 조금 수정하여 테스트 데이터에 대한 정확도를 계산해봅니다.
dl_mlp_predict_test.py

이 코드를 실행하면 다음과 같은 결과가 나옵니다.
예측성공/총개수: [9597]/[10000]
딥러닝 정확도: 95.97%
두 개의 결과를 비교해보면 테스트 데이터에 대한 정확도가 트레이닝 데이터에 대한 정확도보다 쪼금 작습니다. 이는 학습 결과가 약간 오버피팅이 되었음을 알 수 있습니다.
그렇다면 어떤 손글씨 숫자들이 제대로 인식이 안되었는지 확인해보죠~
아래의 코드를 여태까지 작성한 코드 마지막에 추가합니다.

위 코드를 추가한 코드를 실행하면 아래와 같은 결과가 화면에 보입니다.
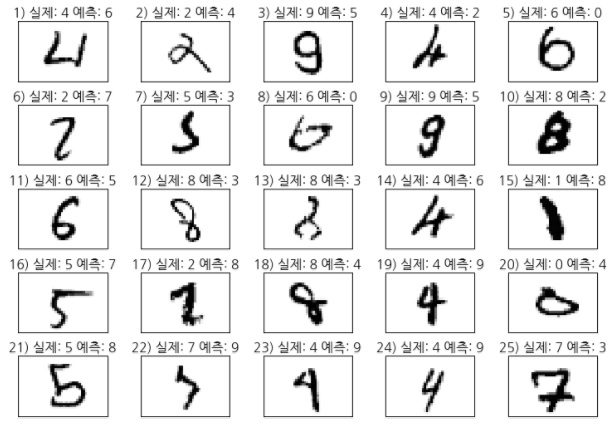
우리가 학습시킨 MLP가 잘못 인식한 숫자들 중 일부입니다. 그런데, 일부 숫자는 사람이 보기에도 구분이 안되는 것이 있습니다. 1), 6), 7), 8), 13), 17), 22), 23), 25) 등은 우리 눈으로 보기에도 헷갈리는 숫자들입니다.
아무튼 이런 데이터들에 대해서는 사용자로 하여금 피드백을 줘서 제대로 된 숫자로 인식하도록 학습시키면 될 것입니다. 사용자의 피드백을 재학습시키는 내용에 대해서는 [22편] 마지막 부분에서 다루었습니다.
만약 여러분들이 직접 쓴 숫자를 여기서 학습한 MLP를 이용해 인식하려고 하면 아래와 같은 로직으로 프로그램을 작성하면 됩니다.
- 여러분이 손으로 쓴 숫자를 이미지로 저장합니다.
- 이미지의 크기를 OpenCV의 cv2.resize()를 이용해 28 x 28 크기로 변환합니다.
- OpenCV의 cv2.threshold()를 이용해 숫자 부분과 배경부분을 검정색과 흰색으로 변환시켜 줍니다.
- 이렇게 변환된 이미지 픽셀을 numpy로 저장하고 ravel()을 이용해 1차원으로 변형한 후 이 값을 X로 둡니다.
- y_pred = mlp.predict(X)로 예측값인 y_pred를 확인하면 됩니다.
OpenCV에 대한 자세한 내용은 제 블로그의 OpenCV 강좌를 참조하면 됩니다.
이상으로 다층 퍼셉트론을 이용한 손글씨 숫자를 인식하는 내용은 마무리 하도록 하겠습니다.
다음 포스팅에서는 구현한 역전파 알고리즘의 정확도를 체크하는 방법인 gradient checking에 대해 가볍게 살펴보도록 하고, 이후 포스팅부터는 또 다른 딥러닝 방법인 Convolutional Neural Network(CNN)과 Recurrent Neural Network(RNN)에 대한 내용을 다루도록 하겠습니다.
[출처] [37편] 다층 퍼셉트론 구현하기|작성자 옥수별
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [39편] 인공신경망/AI에 대한 간략한 히스토리 (0) | 2017.12.14 |
|---|---|
| [38편] 인공신경망의 정확성 검증 - gradient checking (0) | 2017.12.14 |
| [36편] 딥러닝의 핵심 개념 - 역전파(backpropagation) 이해하기2 (0) | 2017.12.14 |
| [35편] 딥러닝의 핵심 개념 - 역전파(backpropagation) 이해하기1 (0) | 2017.12.14 |
| [34편] 딥러닝의 기초 - 다층 퍼셉트론(Multi-Layer Perceptron; MLP) (0) | 2017.12.14 |