그동안 개인적으로 이런저런 일로 바쁘고, 많은 변화가 있어, 정말 오랜만에 포스팅을 하게 됩니다.
이번 포스팅에서는 여태까지 다루어 보았던 머신러닝 및 딥러닝, AI와 관련하여 그 기반이 되는 인공신경망에 대한 간략한 히스토리를 정리해보고자 합니다.
아, 물론 딥러닝의 꽃이라 부를 수 있는 CNN(Convolutional Neural Network)이나 RNN(Recurrent Neural Network) 등에 대해서는 제 블로그에서 아직 다루진 않았습니다만... 이에 대해서는 시간 나는대로 포스팅하도록 하겠습니다.
먼저 아래 그림으로 인공신경망에 대한 간략한 히스토리를 정리해봅니다.
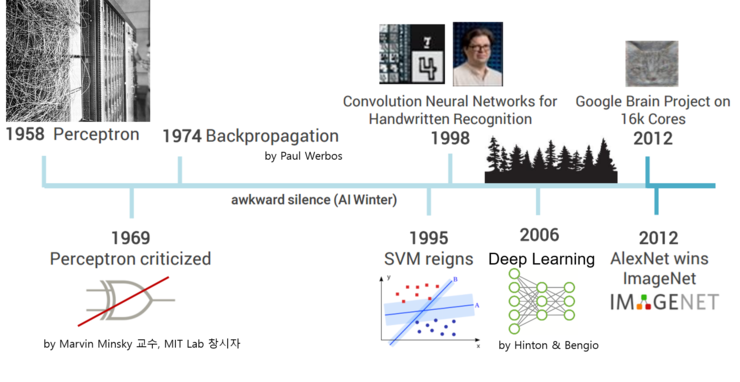
그러면 위 그림을 보면서 인공신경망 발전의 역사를 살포시 살펴봅니다. (내용중 재탕하는 내용도 있으니 참고바랍니다.)
1943년 신경과학자인 Warren S. McCulloch과 논리학자인 Walter Pitts는 하나의 사람 뇌 신경세포를 하나의 이진(Binary)출력을 가지는 단순 논리 게이트로 설명했는데, 이를 McCulloch-Pitts 뉴런(MCP 뉴런)이라 부릅니다.
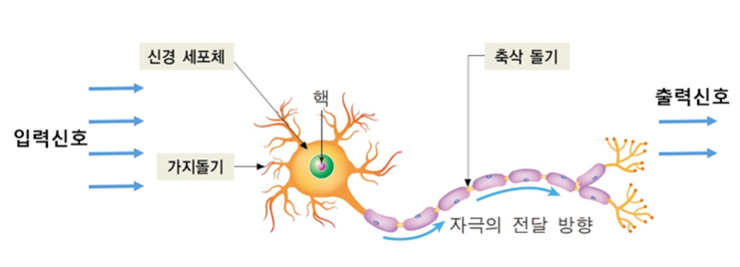
1957년 코넬 항공 연구소에 근무하던 Frank Rosenblatt은 MCP 뉴런 모델을 기초로 퍼셉트론(Perceptron) 학습 규칙이라는 개념을 고안하게 되는데, Rosenblatt은 하나의 MCP 뉴런이 출력신호를 발생할지 안할지 결정하기 위해, MCP 뉴런으로 들어오는 각 입력값에 곱해지는 가중치 값을 자동적으로 학습하는 알고리즘을 제안했습니다.
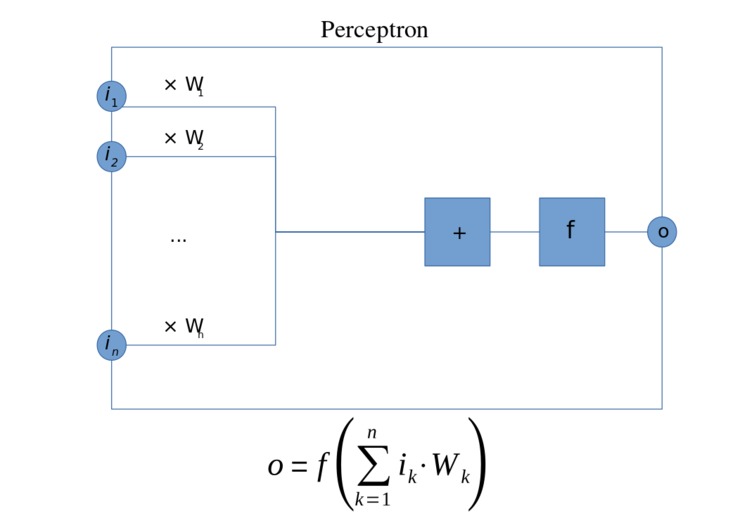
1958년 퍼셉트론이 발표된 후 같은 해 7월 8일자 뉴욕타임즈는 앞으로 조만간 걷고, 말하고 자아를 인식하는 단계에 이르는 컴퓨터 세상이 도래할 것이라는 다소 과격한 기사를 냈습니다.
하지만 1969년, 단순 퍼셉트론은 XOR 문제도 풀 수 없다는 사실을 MIT AI 랩 창시자인 Marvin Minsky 교수가 증명하였고, 아래 그림과 같은 다층 퍼셉트론(MLP)으로 신경망을 구성하면 XOR 문제를 풀 수 있다고 했습니다.
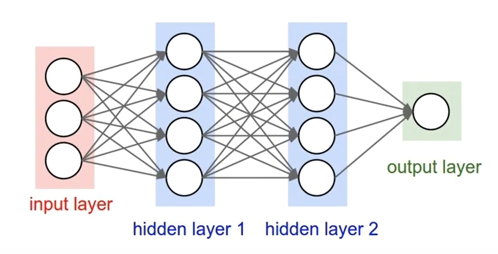
그런데, Minsky 교수는 이러한 MLP에서 hidden layer의 가중치를 계산하는, 다시 말하면 MLP를 학습시키는 방법은 존재하지 않는다고 단정해버렸습니다.
이로 인해 떠들석했던 인공신경망과 관련된 학문과 기술은 더 이상 발전되지 않고 암흑기를 겪게 됩니다.
그러다가 1974년, 당시 하버드 대학교 박사과정이었던 Paul Werbos는 MLP를 학습시키는 방법을 찾게 되는데, 이 방법을 Minsky 교수에게 설명하지만 냉랭한 분위기속에 무시되버립니다.
Paul Werbos가 Minsky 교수에게 설명한 MLP를 학습시킬 수 있는 획기적인 방법이 바로 오류 역전파 (Backpropagation of errors)라는 개념입니다. 그냥 줄여서 역전파(Backpropagation)이라 부르기도 하지요.
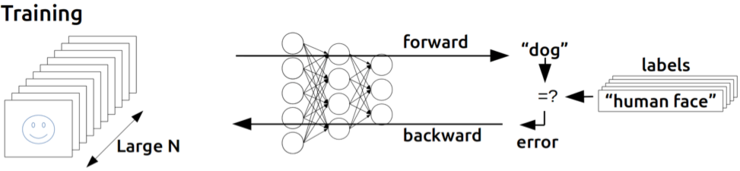
이런 획기적인 방법 역시 당시 인공신경망의 대가와 학계로부터 무시당해버린 후 Werbos는 1982년 역전파에 대한 내용을 논문으로 발표하고 마무리합니다. Werbos의 역전파가 무시된 이후 10여년 넘게 AI 분야는 혹한기를 겪게 됩니다.
그러다가 1986년 인지심리학자이자 컴퓨터공학자였던 Geoffrey Hinton 교수는 Werbos가 제안한 오류 역전파 알고리즘에 대한 내용을 독자적으로 제안하게 됩니다. 하지만 Werbos가 수 년전에 먼저 논문으로 발표한 내용이기 때문에 Hinton 교수는 역전파 개념을 다시 발견했다고 보는 것이 맞을 겁니다.
그런데 다층구조로 되어 있는 MLP의 학습은 역전파를 통해 학습이 가능하지만 학습의 효과를 크게 하려면 인공신경망의 은닉층(hidden layer)를 많이 쌓아야 더 좋은 결과가 나올 수 있다는 것이 경험적으로 검증되었습니다.
하지만, 당시까지만 해도 활성함수로써 시그모이드 함수를 사용했고, 이는 은닉층의 개수가 많아질수록 역전파에 의한 가중치 계산이 불가능하게 되는 gradient vanishing이라는 문제에 직면하게 되었습니다.

gradient vanishing 문제는 인공신경망 분야의 2번째 암흑기가 시작되는 계기가 되버립니다.
1995년에는 당시 다른 방식으로 발전되었던 보다 단순한 머신러닝 알고리즘인 SVM, RandomForest와 같은 알고리즘이 손글씨 인식 등과 같은 분야에는 더 잘 작동한다고 Lecun 교수 등이 발표하기도 했습니다.
1998년 컴퓨터공학자인 Yann Lecun 교수는 1950년대 수행했던 고양이의 뇌파 실험에 영감을 얻어 이미지 인식을 획기적으로 개선할 수 있는 CNN(Convolutional Neural Network)라는 새로운 형태의 인공신경망을 고안하게 됩니다.
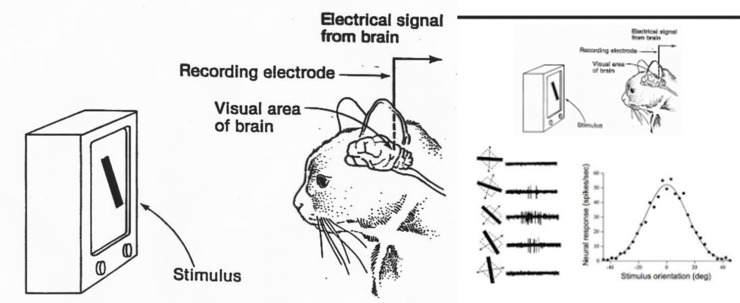
1950년대 수행했던 고양이의 실험은 고양이의 눈으로 보는 사물의 형태에 따라 뇌의 특정영역, 정확히 말하면 특정 뉴런만이 활성화 된다는 것을 알게 된 것입니다. Lecun 교수는 이러한 실험 결과에 영감을 얻어 CNN이라는 새로운 형태의 인공신경망을 고안하게 된 것입니다.
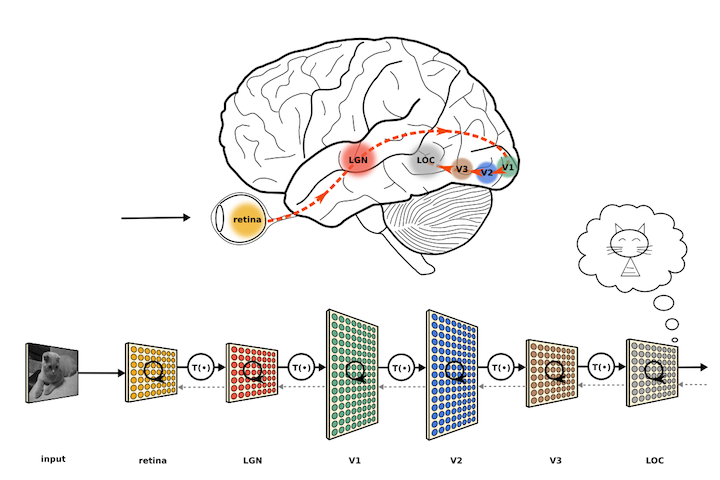
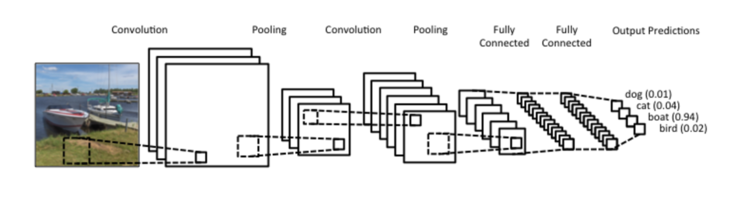
하지만 gradient vanishing 문제 등으로 인해 한동안 인공신경망 분야가 침체기를 겪고 있던 시기에, Hinton 교수와 Bengio 교수는 2006년, 2007년 두 편의 논문을 발표하였는데 초기 입력값을 잘 선택하면 아무리 인공신경망의 층의 개수가 많더라도 학습이 가능하며, 복잡한 문제도 층의 개수가 많게 구성된 인공신경망이라면 해결할 수 있다고 했습니다. 그리고 이렇게 층의 개수가 많은 신경망을 심층신경망(Deep Neural Network:DNN)이라 리브랜딩하고 심층신경망을 학습시키는 방법을 딥러닝(Deep Learning:DL)이라고 명명하게 됩니다.
그리고 2000년 네이처(Nature)지에 시그모이드를 대신하여 사용한 Rectifier라는 활성함수를 이용해 효과를 봤다는 내용의 생물학 분야의 논문이 발표되었습니다. Rectifier는 ReLU(Rectified Linear Unit)라고 불리게 되는 활성함수인데, 이 활성함수를 심층신경망의 딥러닝에 사용해보니 gradient vanishing 문제가 해결되버린 것입니다. 물론 심층신경망의 최종 출력층에서는 여전히 시그모이드나 SoftMax를 사용하지만 말이죠.
아무튼 활성함수 ReLU의 등장으로 딥러닝은 많은 발전을 이루게 되었고, 2012년 이미지 인식 분야의 유명한 대회인 ImageNet Large Scale Visiual Recognition Challenge(ILVRC)에서 캐나다 토론토 대학의 AlexNet이라 불리는 CNN 인공신경망으로 우승하게 되는데, 이전 까지 이미지 인식 오류율이 26%대였던 것이 15%대로 줄이게 된 것입니다.
이후 CNN의 신경망구조가 지속적으로 개선되고 GPU의 발전으로 현재는 5% 이내의 오류율로 학습이 가능하게 되었습니다.
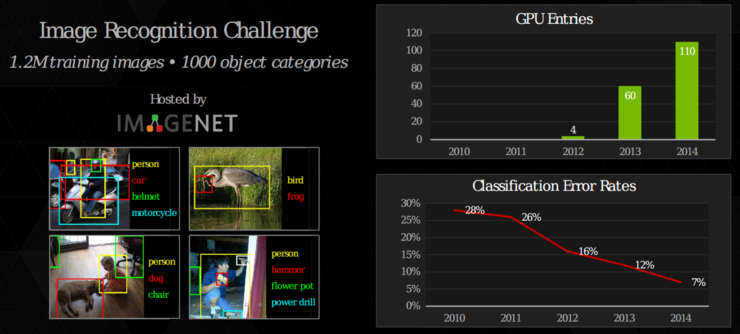
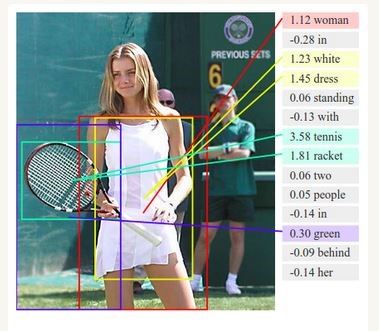
현재 이미지 인식 수준은 아래 그림과 같이 주어진 사진을 설명하는 단계에 이르고 있습니다.
그리고 2016년 알파고가 등장하여 이세돌 9단을 4승1패로 이기면서 세계를 놀라게 했고, 현재는 인공신경망을 이용한 인공지능을 자율주행자동차와 같은 다양한 분야에 적용하고자 노력하고 있는 중입니다.


아마, 미래에는 스스로 생각하고 인지하는 인공지능이 탄생할지도 모르지요.

하지만....
아직까지 인공지능과 우리 인간의 뇌는 다릅니다!
- 인간의 뇌는 약 1천억개의 뉴런과 100조개의 시냅스로 연결되어 있고, 20와트의 전력만으로 충분합니다.
- 하지만 가장 거대한 인공신경망의 규모는 기껏해봐야 16,000개의 CPU코어상에서 1천만 뉴런과 10억개의 연결로 이루어져 있으며, 소모되는 전력은 3백만와트나 됩니다.
- 인간의 뇌는 5개의 감각기관으로부터 5가지 유형의 입력만 받습니다.
- 우리 아기들은 고양이를 학습하는데 라벨링된 10만장의 사진이 필요하지 않습니다.
솔직히 우리는,,, 학습이 이루어지는 우리 뇌의 기작을 잘 알지 못합니다.
이상으로 인공신경망에 대한 히스토리를 가볍게 살펴보았습니다.
아래 영상은 제가 ImageNet으로부터 다운받은 강아지 사진과 꽃 사진을 이용해 tensorflow로 학습을 하고 구글에서 제공해준 템플릿 코드를 이용하여 만들어본 안드로이드 프로그램을 구동한 것입니다.
왼쪽 동영상은 제 스마트폰으로 PC화면에 보이는 강아지와 꽃들을 촬영한 화면을 캡쳐 녹화한 것이고, 오른쪽 동영상은 우리집 강아지와 장미 조화를 스마트폰으로 촬영한 영상을 보인 것입니다. 화면에 표시되는 숫자는 이미지 인식 확률이며 1.0이 100%입니다.


참고로 제 사진 50여장과 무작위 남자 사진 1000여장을 학습시켜본 결과 제 사진을 촬영했을 때 저를 인식한 확률이 매우 높았습니다.
'책 리뷰 > Python Machine Learning' 카테고리의 다른 글
| [Chapter9] 머신러닝 모델의 웹 애플리케이션 임베딩 (0) | 2017.12.25 |
|---|---|
| [Chapter8] 머신러닝을 감성분석에 적용하기 (0) | 2017.12.25 |
| [38편] 인공신경망의 정확성 검증 - gradient checking (0) | 2017.12.14 |
| [37편] 다층 퍼셉트론 구현하기 (0) | 2017.12.14 |
| [36편] 딥러닝의 핵심 개념 - 역전파(backpropagation) 이해하기2 (0) | 2017.12.14 |